Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von Map State im verteilten Modus für umfangreiche parallel Workloads in Step Functions
Status verwalten und Daten transformieren
Erfahren Sie mehr über das Übergeben von Daten zwischen Zuständen mithilfe von Variablen und das Transformieren von Daten mit JSONata.
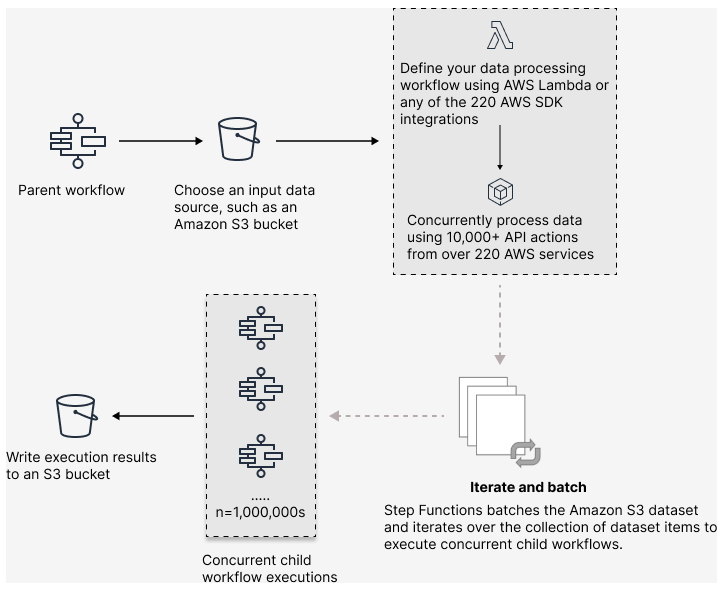
Mit Step Functions können Sie umfangreiche parallel Workloads orchestrieren, um Aufgaben wie die On-Demand-Verarbeitung halbstrukturierter Daten auszuführen. Mit diesen parallel Workloads können Sie große Datenquellen, die in Amazon S3 gespeichert sind, gleichzeitig verarbeiten. Sie könnten beispielsweise eine einzelne JSON- oder CSV-Datei verarbeiten, die große Datenmengen enthält. Oder Sie könnten eine große Menge von Amazon S3 S3-Objekten verarbeiten.
Um eine umfangreiche parallel Arbeitslast in Ihren Workflows einzurichten, fügen Sie einen Map Status im Modus Verteilt hinzu. Der Kartenstatus verarbeitet Elemente in einem Datensatz gleichzeitig. Ein Map Status, der auf Distributed gesetzt ist, wird als Distributed Map-Status bezeichnet. Im Modus „Verteilt“ ermöglicht der Map Status eine Verarbeitung mit hoher Parallelität. Im verteilten Modus verarbeitet der Map Status die Elemente in der Datenmenge in Iterationen, die als untergeordnete Workflow-Ausführungen bezeichnet werden. Sie können die Anzahl der untergeordneten Workflow-Ausführungen angeben, die parallel ausgeführt werden können. Jede Ausführung eines untergeordneten Workflows hat einen eigenen Ausführungsverlauf, der von dem des übergeordneten Workflows getrennt ist. Wenn Sie nichts angeben, führt Step Functions 10.000 parallele Ausführungen untergeordneter Workflows parallel aus.
In der folgenden Abbildung wird erklärt, wie Sie umfangreiche parallel Workloads in Ihren Workflows einrichten können.
Lernen Sie in einem Workshop
Erfahren Sie, wie serverlose Technologien wie Step Functions und Lambda die Verwaltung und Skalierung vereinfachen, undifferenzierte Aufgaben auslagern und die Herausforderungen der groß angelegten verteilten Datenverarbeitung bewältigen können. Unterwegs werden Sie mit verteilter Karte arbeiten, um eine hohe Parallelität der Verarbeitung zu gewährleisten. In dem Workshop werden auch bewährte Verfahren zur Optimierung Ihrer Arbeitsabläufe sowie praktische Anwendungsfälle für die Bearbeitung von Schadensfällen, das Scannen von Sicherheitslücken und die Monte-Carlo-Simulation vorgestellt.
Workshop: Datenverarbeitung im großen Maßstab mit Step Functions
In diesem Thema
Wichtige Begriffe
- Verteilter Modus
-
Ein Verarbeitungsmodus des Kartenstatus. In diesem Modus wird jede Iteration des
MapStatus als untergeordnete Workflow-Ausführung ausgeführt, wodurch eine hohe Parallelität ermöglicht wird. Jede untergeordnete Workflow-Ausführung hat ihren eigenen Ausführungsverlauf, der vom Ausführungsverlauf des übergeordneten Workflows getrennt ist. Dieser Modus unterstützt das Lesen von Eingaben aus großen Amazon S3 S3-Datenquellen. - Status der verteilten Karte
-
Ein Map-Status, der auf den Modus Verteilte Verarbeitung gesetzt ist.
- Arbeitsablauf zuordnen
Eine Reihe von Schritten, die ein
MapBundesstaat ausführt.- Übergeordneter Arbeitsablauf
-
Ein Workflow, der einen oder mehrere Distributed Map-Status enthält.
- Ausführung eines untergeordneten Workflows
-
Eine Iteration des Distributed-Map-Status. Die Ausführung eines untergeordneten Workflows hat einen eigenen Ausführungsverlauf, der vom Ausführungsverlauf des übergeordneten Workflows getrennt ist.
- Ordnen Sie Run zu
-
Wenn Sie einen
MapStatus im verteilten Modus ausführen, erstellt Step Functions eine Map Run-Ressource. Ein Map Run bezieht sich auf eine Reihe von untergeordneten Workflow-Ausführungen, die im Status Distributed Map gestartet werden, sowie auf die Laufzeiteinstellungen, die diese Ausführungen steuern. Step Functions weist Ihrem Map Run einen Amazon-Ressourcennamen (ARN) zu. Sie können einen Map Run in der Step Functions-Konsole untersuchen. Sie können dieDescribeMapRunAPI-Aktion auch aufrufen.Untergeordnete Workflow-Ausführungen eines Map Run senden Metriken an CloudWatch;. Für diese Metriken wird ein mit State Machine beschrifteter ARN im folgenden Format angezeigt:
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUIDWeitere Informationen finden Sie unter Map Runs anzeigen.
Beispiel für eine Status-Definition von Distributed Map () JSONPath
Verwenden Sie den Map Status im Modus Verteilt, wenn Sie umfangreiche parallel Workloads orchestrieren müssen, die eine beliebige Kombination der folgenden Bedingungen erfüllen:
Die Größe Ihres Datensatzes übersteigt 256 KiB.
Der Verlauf der Ausführungsereignisse des Workflows würde 25.000 Einträge überschreiten.
Sie benötigen eine Parallelität von mehr als 40 gleichzeitigen Iterationen.
Das folgende Beispiel für die Zustandsdefinition von Distributed Map spezifiziert den Datensatz als CSV-Datei, die in einem Amazon S3 S3-Bucket gespeichert ist. Es spezifiziert auch eine Lambda-Funktion, die die Daten in jeder Zeile der CSV-Datei verarbeitet. Da in diesem Beispiel eine CSV-Datei verwendet wird, wird auch die Position der CSV-Spaltenüberschriften angegeben. Die vollständige State-Machine-Definition dieses Beispiels finden Sie im Tutorial Kopieren umfangreicher CSV-Daten mit Distributed Map.
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}Berechtigungen zum Ausführen von Distributed Map
Wenn Sie einen Distributed Map-Status in Ihre Workflows aufnehmen, benötigt Step Functions die entsprechenden Berechtigungen, damit die Zustandsmaschinenrolle die StartExecution API-Aktion für den Distributed-Map-Status aufrufen kann.
Das folgende Beispiel für eine IAM-Richtlinie gewährt Ihrer State-Machine-Rolle die geringsten Rechte, die für die Ausführung des Status Distributed Map erforderlich sind.
Anmerkung
Stellen Sie sicher, dass Sie den Status stateMachineNamearn:aws:states:.region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
Darüber hinaus müssen Sie sicherstellen, dass Sie über die geringsten Rechte verfügen, die für den Zugriff auf die im Status Distributed Map verwendeten AWS Ressourcen erforderlich sind, z. B. Amazon S3 S3-Buckets. Weitere Informationen finden Sie unter IAM-Richtlinien für die Verwendung von Distributed Map-Status.
Felder für den Status von Distributed Map
Um den Status „Distributed Map“ in Ihren Workflows zu verwenden, geben Sie eines oder mehrere dieser Felder an. Sie geben diese Felder zusätzlich zu den allgemeinen Statusfeldern an.
Type(Erforderlich)-
Legt den Zustandstyp fest, z.
MapB. ItemProcessor(Erforderlich)-
Enthält die folgenden JSON-Objekte, die den Verarbeitungsmodus und die Definition des
MapStatus angeben.-
ProcessorConfig— JSON-Objekt, das den Modus für die Verarbeitung von Elementen spezifiziert, mit den folgenden Unterfeldern:-
Mode— Auf einstellen,DISTRIBUTEDum denMapStatus im verteilten Modus zu verwenden.Warnung
Der verteilte Modus wird in Standard-Workflows unterstützt, in Express-Workflows jedoch nicht.
-
ExecutionType— Gibt den Ausführungstyp für den Map-Workflow entweder als STANDARD oder EXPRESS an. Sie müssen dieses Feld angeben, wenn Sie esDISTRIBUTEDfür dasModeUnterfeld angegeben haben. Weitere Informationen zu Workflowtypen finden Sie unterWorkflowtyp in Step Functions auswählen.
-
StartAt— Gibt eine Zeichenfolge an, die den ersten Status in einem Workflow angibt. Bei dieser Zeichenfolge wird zwischen Groß- und Kleinschreibung unterschieden und sie muss mit dem Namen eines der Statusobjekte übereinstimmen. Dieser Status wird für jedes Element im Datensatz zuerst ausgeführt. Jede Ausführungseingabe, die Sie für denMapStatus bereitstellen, wird zuerst an denStartAtStatus übergeben.States— Ein JSON-Objekt, das eine durch Kommas getrennte Gruppe von Zuständen enthält. In diesem Objekt definieren Sie die. Map workflow
-
ItemReader-
Gibt einen Datensatz und seinen Speicherort an. Der
MapStaat erhält seine Eingabedaten aus dem angegebenen Datensatz.Im verteilten Modus können Sie entweder eine JSON-Nutzlast, die aus einem früheren Status übergeben wurde, oder eine umfangreiche Amazon S3 S3-Datenquelle als Datensatz verwenden. Weitere Informationen finden Sie unter ItemReader (Karte).
Items( JSONata Nur optional)-
Ein JSON-Array, ein JSON-Objekt oder ein JSONata Ausdruck, der zu einem Array oder Objekt ausgewertet werden muss.
ItemsPath( JSONPath Nur optional)-
Gibt einen Referenzpfad an, der anhand der JsonPath
Syntax den JSON-Knoten auswählt, der ein Array von Elementen oder ein Objekt mit Schlüssel-Wert-Paaren innerhalb der Statuseingabe enthält. Im verteilten Modus geben Sie dieses Feld nur an, wenn Sie ein JSON-Array oder ein JSON-Objekt aus einem vorherigen Schritt als Statuseingabe verwenden. Weitere Informationen finden Sie unter ItemsPath ( JSONPath Nur Karte).
ItemSelector( JSONPath Nur optional)-
Überschreibt die Werte einzelner Datensatzelemente, bevor sie an jede
MapState-Iteration weitergegeben werden.In diesem Feld geben Sie eine gültige JSON-Eingabe an, die eine Sammlung von Schlüssel-Wert-Paaren enthält. Bei diesen Paaren kann es sich entweder um statische Werte handeln, die Sie in Ihrer Zustandsmaschinen-Definition definieren, um Werte, die mithilfe eines Pfads aus der Zustandseingabe ausgewählt wurden, oder um Werte, auf die über das Kontextobjekt zugegriffen wird. Weitere Informationen finden Sie unter ItemSelector (Karte).
ItemBatcher(Optional)-
Gibt an, dass die Datensatzelemente stapelweise verarbeitet werden sollen. Jede untergeordnete Workflow-Ausführung erhält dann einen Stapel dieser Elemente als Eingabe. Weitere Informationen finden Sie unter ItemBatcher (Karte).
MaxConcurrency(Optional)-
Gibt die Anzahl der untergeordneten Workflow-Ausführungen an, die parallel ausgeführt werden können. Der Interpreter erlaubt nur bis zu der angegebenen Anzahl parallel untergeordneter Workflow-Ausführungen. Wenn Sie keinen Parallelitätswert angeben oder ihn auf Null setzen, schränkt Step Functions die Parallelität nicht ein und führt 10.000 parallel untergeordnete Workflow-Ausführungen aus. In JSONata Bundesstaaten können Sie einen JSONata Ausdruck angeben, der eine Ganzzahl ergibt.
Anmerkung
Sie können zwar ein höheres Parallelitätslimit für parallel untergeordnete Workflow-Ausführungen angeben, wir empfehlen jedoch, die Kapazität eines AWS Downstream-Dienstes nicht zu überschreiten, z. B. AWS Lambda
MaxConcurrencyPath(Nur optional) JSONPath-
Wenn Sie mithilfe eines Referenzpfads dynamisch aus der Statuseingabe einen maximalen Parallelitätswert angeben möchten, verwenden Sie
MaxConcurrencyPath. Nach der Auflösung muss der Referenzpfad ein Feld auswählen, dessen Wert eine nicht negative Ganzzahl ist.Anmerkung
Ein
MapStatus kann nicht sowohl als auchMaxConcurrencyenthalten.MaxConcurrencyPath ToleratedFailurePercentage(Optional)-
Definiert den Prozentsatz fehlgeschlagener Elemente, der in einem Map-Run toleriert werden soll. Der Map Run schlägt automatisch fehl, wenn er diesen Prozentsatz überschreitet. Step Functions berechnet den Prozentsatz der fehlgeschlagenen Elemente als Ergebnis der Gesamtzahl der fehlgeschlagenen Elemente oder der Zeitüberschreitung dividiert durch die Gesamtzahl der Elemente. Sie müssen einen Wert zwischen Null und 100 angeben. Weitere Informationen finden Sie unter Festlegung von Ausfallschwellenwerten für Distributed Map-Zustände in Step Functions.
In JSONata Bundesstaaten können Sie einen JSONata Ausdruck angeben, der zu einer Ganzzahl ausgewertet wird.
ToleratedFailurePercentagePath( JSONPath Nur optional)-
Wenn Sie einen prozentualen Wert für tolerierte Fehler dynamisch aus der Statuseingabe mithilfe eines Referenzpfads angeben möchten, verwenden Sie
ToleratedFailurePercentagePath. Wenn das Problem gelöst ist, muss der Referenzpfad ein Feld auswählen, dessen Wert zwischen Null und 100 liegt. ToleratedFailureCount(Optional)-
Definiert die Anzahl der fehlgeschlagenen Elemente, die in einem Map-Run toleriert werden sollen. Der Map Run schlägt automatisch fehl, wenn er diese Anzahl überschreitet. Weitere Informationen finden Sie unter Festlegung von Ausfallschwellenwerten für Distributed Map-Zustände in Step Functions.
In JSONata Bundesstaaten können Sie einen JSONata Ausdruck angeben, der eine Ganzzahl ergibt.
ToleratedFailureCountPath( JSONPath Nur optional)-
Wenn Sie einen Wert für die Anzahl tolerierter Fehler dynamisch aus der Statuseingabe mithilfe eines Referenzpfads angeben möchten, verwenden Sie
ToleratedFailureCountPath. Wenn das Problem gelöst ist, muss der Referenzpfad ein Feld auswählen, dessen Wert eine nicht negative Ganzzahl ist. Label(Optional)-
Eine Zeichenfolge, die einen
MapBundesstaat eindeutig identifiziert. Für jeden Map Run fügt Step Functions das Label zum Map Run-ARN hinzu. Im Folgenden finden Sie ein Beispiel für einen Map Run-ARN mit einem benutzerdefinierten Label namensdemoLabel:arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0bWenn Sie kein Label angeben, generiert Step Functions automatisch ein eindeutiges Label.
Anmerkung
Beschriftungen dürfen nicht länger als 40 Zeichen sein, müssen innerhalb einer State-Machine-Definition eindeutig sein und dürfen keines der folgenden Zeichen enthalten:
-
Leerraum
-
Platzhalterzeichen ()
? * -
Klammerzeichen ()
< > { } [ ] -
Sonderzeichen (
: ; , \ | ^ ~ $ # % & ` ") -
Steuerzeichen (
\\u0000-\\u001foder\\u007f-\\u009f).
Step Functions akzeptiert Namen für Zustandsmaschinen, Ausführungen, Aktivitäten und Labels, die Nicht-ASCII-Zeichen enthalten. Da solche Zeichen Amazon CloudWatch daran hindern, Daten zu protokollieren, empfehlen wir, nur ASCII-Zeichen zu verwenden, damit Sie die Step Functions Functions-Metriken verfolgen können.
-
ResultWriter(Optional)-
Gibt den Amazon S3 S3-Speicherort an, an den Step Functions alle untergeordneten Workflow-Ausführungsergebnisse schreibt.
Step Functions konsolidiert alle Ausführungsdaten des untergeordneten Workflows, wie z. B. Ausführungseingabe und -ausgabe, ARN und Ausführungsstatus. Anschließend werden Ausführungen mit demselben Status in die entsprechenden Dateien am angegebenen Amazon S3 S3-Speicherort exportiert. Weitere Informationen finden Sie unter ResultWriter (Karte).
Wenn Sie die
MapStatusergebnisse nicht exportieren, wird ein Array mit allen Ergebnissen der untergeordneten Workflow-Ausführung zurückgegeben. Beispiel:[1, 2, 3, 4, 5] ResultPath( JSONPath Nur optional)-
Gibt an, wo in der Eingabe die Ausgabe der Iterationen platziert werden soll. Die Eingabe wird dann gemäß den Angaben des OutputPathFelds gefiltert, falls vorhanden, bevor sie als Ausgabe für den Status übergeben wird. Weitere Informationen finden Sie unter Verarbeitung von Eingabe und Ausgabe.
ResultSelector(Optional)-
Übergibt eine Sammlung von Schlüssel-Wert-Paaren, wobei die Werte statisch sind oder aus dem Ergebnis ausgewählt werden. Weitere Informationen finden Sie unter ResultSelector.
Tipp
Wenn der Status Parallel oder Map, den Sie in Ihren Zustandsmaschinen verwenden, ein Array von Arrays zurückgibt, können Sie diese mit dem Feld in ein flaches Array umwandeln. ResultSelector Weitere Informationen finden Sie unter Reduzieren eines Arrays von Arrays.
Retry(Optional)-
Eine Reihe von Objekten, sogenannte Retriers, die eine Wiederholungsrichtlinie definieren. Eine Ausführung verwendet die Wiederholungsrichtlinie, wenn der Status auf Laufzeitfehler stößt. Weitere Informationen finden Sie unter Beispiele für Zustandsmaschinen mit Retry und Catch.
Anmerkung
Wenn Sie Retrier für den Status Distributed Map definieren, gilt die Wiederholungsrichtlinie für alle untergeordneten Workflow-Ausführungen, die im Status gestartet wurden.
MapStellen Sie sich beispielsweise vor, IhrMapBundesstaat hat drei untergeordnete Workflow-Ausführungen gestartet, von denen eine fehlschlägt. Wenn der Fehler auftritt, verwendet die Ausführung dasRetryFeld, sofern definiert, für denMapStatus. Die Wiederholungsrichtlinie gilt für alle untergeordneten Workflow-Ausführungen und nicht nur für die fehlgeschlagene Ausführung. Wenn eine oder mehrere untergeordnete Workflow-Ausführungen fehlschlagen, schlägt der Map Run fehl.Wenn Sie einen
MapStatus erneut versuchen, wird ein neuer Map Run erstellt. Catch(Optional)-
Ein Array von Objekten namens Catcher, die einen Fallback-Zustand definieren. Step Functions verwendet die in definierten Catcher,
Catchwenn der Status auf Laufzeitfehler stößt. Wenn ein Fehler auftritt, verwendet die Ausführung zunächst alle in definierten Retrier.RetryWenn die Wiederholungsrichtlinie nicht definiert oder ausgeschöpft ist, verwendet die Ausführung ihre Catcher, sofern sie definiert sind. Weitere Informationen finden Sie unter Fallback-Zustände. Output(Nur optional) JSONata-
Wird verwendet, um die Ausgabe des Status zu spezifizieren und zu transformieren. Wenn angegeben, überschreibt der Wert die Standardeinstellung für die Statusausgabe.
Das Ausgabefeld akzeptiert jeden JSON-Wert (Objekt, Array, Zeichenfolge, Zahl, boolescher Wert, Null). Jeder Zeichenkettenwert, einschließlich solcher innerhalb von Objekten oder Arrays, wird so ausgewertet, als JSONata ob er von {%%} Zeichen umgeben wäre.
Output akzeptiert auch direkt einen JSONata Ausdruck, zum Beispiel: „Output“: „{% jsonata expression%}“
Weitere Informationen finden Sie unter Transformieren von Daten mit JSONata in Step Functions.
-
Assign(Optional) -
Wird zum Speichern von Variablen verwendet. Das
AssignFeld akzeptiert ein JSON-Objekt mit key/value Paaren, die Variablennamen und die ihnen zugewiesenen Werte definieren. Jeder Zeichenkettenwert, auch solche innerhalb von Objekten oder Arrays, wird so ausgewertet, JSONata als ob er von Zeichen umgeben{% %}wäreWeitere Informationen finden Sie unter Übergeben von Daten zwischen Staaten mit Variablen.
Festlegung von Ausfallschwellenwerten für Distributed Map-Zustände in Step Functions
Wenn Sie umfangreiche parallel Workloads orchestrieren, können Sie auch einen Schwellenwert für tolerierte Fehler definieren. Mit diesem Wert können Sie die maximale Anzahl oder den Prozentsatz fehlgeschlagener Elemente als Schwellenwert für einen Kartenlauf angeben. Je nachdem, welchen Wert Sie angeben, schlägt Ihr Map Run automatisch fehl, wenn er den Schwellenwert überschreitet. Wenn Sie beide Werte angeben, schlägt der Workflow fehl, wenn einer der Werte überschritten wird.
Wenn Sie einen Schwellenwert angeben, können Sie bei einer bestimmten Anzahl von Elementen Fehler beheben, bevor der gesamte Map Run fehlschlägt. Step Functions gibt einen States.ExceedToleratedFailureThreshold Fehler zurück, wenn der Map Run fehlschlägt, weil der angegebene Schwellenwert überschritten wird.
Anmerkung
Step Functions kann weiterhin untergeordnete Workflows in einem Map Run ausführen, auch wenn der tolerierte Fehlerschwellenwert überschritten wurde, aber bevor der Map Run fehlschlägt.
Um den Schwellenwert in Workflow Studio anzugeben, wählen Sie unter Zusätzliche Konfiguration im Feld Runtime-Einstellungen die Option Schwellenwert für tolerierte Fehler festlegen aus.
- Prozentsatz der tolerierten Fehler
-
Definiert den Prozentsatz fehlgeschlagener Elemente, der toleriert werden soll. Ihr Map Run schlägt fehl, wenn dieser Wert überschritten wird. Step Functions berechnet den Prozentsatz der fehlgeschlagenen Elemente als Ergebnis der Gesamtzahl der fehlgeschlagenen Elemente oder der Zeitüberschreitung dividiert durch die Gesamtzahl der Elemente. Sie müssen einen Wert zwischen Null und 100 angeben. Der Standardwert für den Prozentsatz ist Null, was bedeutet, dass der Workflow fehlschlägt, wenn eine der untergeordneten Workflow-Ausführungen fehlschlägt oder ein Timeout auftritt. Wenn Sie den Prozentsatz auf 100 angeben, schlägt der Workflow auch dann nicht fehl, wenn alle untergeordneten Workflow-Ausführungen fehlschlagen.
Alternativ können Sie den Prozentsatz als Referenzpfad zu einem vorhandenen Schlüssel-Wert-Paar in Ihrer Distributed Map-Statuseingabe angeben. Dieser Pfad muss zur Laufzeit in eine positive Ganzzahl zwischen 0 und 100 aufgelöst werden. Sie geben den Referenzpfad im
ToleratedFailurePercentagePathUnterfeld an.Beispielsweise angesichts der folgenden Eingabe:
{"percentage":15}Sie können den Prozentsatz mithilfe eines Referenzpfads zu dieser Eingabe wie folgt angeben:
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }Wichtig
Sie können entweder
ToleratedFailurePercentageoderToleratedFailurePercentagePath, aber nicht beide in Ihrer Statusdefinition für Distributed Map angeben. - Anzahl tolerierter Fehler
-
Definiert die Anzahl der zu tolerierenden fehlgeschlagenen Elemente. Ihr Map Run schlägt fehl, wenn dieser Wert überschritten wird.
Alternativ können Sie die Anzahl als Referenzpfad zu einem vorhandenen Schlüssel-Wert-Paar in Ihrer Distributed Map-Statuseingabe angeben. Dieser Pfad muss zur Laufzeit in eine positive Ganzzahl aufgelöst werden. Sie geben den Referenzpfad im
ToleratedFailureCountPathUnterfeld an.Beispielsweise angesichts der folgenden Eingabe:
{"count":10}Sie können die Nummer mithilfe eines Referenzpfads zu dieser Eingabe wie folgt angeben:
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }Wichtig
Sie können entweder
ToleratedFailureCountoderToleratedFailureCountPath, aber nicht beide in der Status-Definition von Distributed Map angeben.
Erfahren Sie mehr über verteilte Karten
Weitere Informationen zum Status von Distributed Map finden Sie in den folgenden Ressourcen:
-
Verarbeitung von Eingabe und Ausgabe
Um die Eingabe zu konfigurieren, die ein Distributed-Map-Status empfängt, und die Ausgabe, die er generiert, stellt Step Functions die folgenden Felder bereit:
Zusätzlich zu diesen Feldern bietet Ihnen Step Functions auch die Möglichkeit, einen Schwellenwert für tolerierte Fehler für Distributed Map zu definieren. Mit diesem Wert können Sie die maximale Anzahl oder den Prozentsatz fehlgeschlagener Elemente als Fehlerschwellenwert für einen Map-Lauf angeben. Weitere Informationen zur Konfiguration des Schwellenwerts für tolerierte Fehler finden Sie unterFestlegung von Ausfallschwellenwerten für Distributed Map-Zustände in Step Functions.
-
Der Status „Distributed Map“ wird verwendet
In den folgenden Tutorials und Beispielprojekten finden Sie Informationen zu den ersten Schritten mit der Verwendung von Distributed Map State.
-
Untersuchen Sie die Ausführung des Distributed Map-Status
Die Step Functions Functions-Konsole bietet eine Seite mit den Map-Run-Details, auf der alle Informationen zur Ausführung eines Distributed Map-Status angezeigt werden. Informationen darüber, wie Sie die auf dieser Seite angezeigten Informationen überprüfen können, finden Sie unterMap Runs anzeigen.
