Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
nota
Amazon Neptune envía las métricas CloudWatch solo cuando tienen un valor distinto de cero.
Para todas las métricas de Neptune, la granularidad de acumulación es de 5 minutos.
Métricas de Neptune CloudWatch
En la siguiente tabla se enumeran las CloudWatch métricas que admite Neptune.
nota
Todas las métricas acumuladas se restablecen a cero cada vez que el servidor se reinicia, ya sea para realizar tareas de mantenimiento, para reiniciarse o para recuperarse de una caída.
| Métrica | Descripción |
|---|---|
|
La cantidad total de almacenamiento de copias de seguridad, en bytes, que se utiliza para permitir el periodo de retención de copias de seguridad del clúster de base de datos de Neptune. Se incluye en el total registrado por la métrica |
|
Porcentaje de solicitudes que se responden desde la caché de búfer. Esta métrica puede resultar útil para diagnosticar la latencia de las consultas, ya que la falta de memoria caché provoca una latencia significativa. Si la relación de aciertos de la caché es inferior al 99,9 %, considere la posibilidad de actualizar el tipo de instancia para almacenar en caché más datos en memoria. |
|
Para una réplica de lectura, retardo en milisegundos que se da cuando la replicación actualiza desde la instancia principal. |
|
Retardo máximo en milisegundos entre la instancia principal y cada instancia de base de datos de Neptune del clúster de base de datos. |
|
Retardo mínimo en milisegundos entre la instancia principal y cada instancia de base de datos de Neptune del clúster de base de datos. |
|
El número de créditos de CPU que una instancia ha acumulado, notificados en intervalos de 5 minutos. Puede utilizar esta métrica para determinar cuánto tiempo puede una instancia de base de datos de sobrepasar temporalmente su nivel de rendimiento de referencia a una velocidad dada. |
|
El número de créditos de CPU consumidos durante el período especificado, notificados en intervalos de 5 minutos. Esta métrica mide el tiempo durante el cual se CPUs ha utilizado el material físico para procesar las instrucciones de forma virtual CPUs asignado a la instancia de base de datos. |
|
La cantidad de créditos sobrantes que ha gastado una instancia ilimitada cuando su valor |
|
El número de créditos excedentes gastados que no se amortizan con los créditos de CPU acumulados y que conllevan un cargo adicional. |
|
El porcentaje de utilización de CPU. |
|
Cantidad de tiempo en segundos que la instancia lleva en ejecución. |
|
Cantidad de memoria de acceso aleatorio disponible en bytes. |
|
El número de bytes de datos de redo log transferidos desde la base de datos principal Región de AWS a una secundaria Región de AWS en una base de datos global de Neptune. |
|
El número de operaciones de E/S de escritura replicadas desde la Región de AWS principal de la base de datos global hasta el volumen de clúster de una Región de AWS secundaria. Los cálculos de facturación de cada clúster de base de datos de una base de datos global de Neptune utilizan la métrica |
|
El número de milisegundos que un clúster secundario está por detrás del clúster principal tanto para las transacciones de usuario como para las del sistema. |
|
Número de errores del lado del cliente por segundo en recorridos Gremlin. |
|
Número de errores del lado del servidor por segundo en recorridos Gremlin. |
|
Número de solicitudes por segundo al motor Gremlin. |
|
El número de WebSocket conexiones abiertas a Neptune. |
|
Número de errores del lado del cliente por segundo desde solicitudes del programa de carga. |
|
Número de solicitudes del programa de carga por segundo. |
|
Número de errores del lado del servidor del programa de carga por segundo. |
|
El número de solicitudes que espera en la cola de entrada pendientes de ejecución. Neptune comienza a limitar las solicitudes cuando superan la capacidad máxima de cola. |
|
Solo se aplica a una instancia de base de datos o un clúster de base de datos de Neptune sin servidor. A nivel de instancia, indica un porcentaje calculado como el número de unidades de capacidad de Neptune (NCUs) que utiliza actualmente la instancia en cuestión, dividido por la configuración de capacidad máxima de la NCU para el clúster. Una NCU, o unidad de capacidad de Neptune, consta de 2 GiB (gibibyte) de memoria (RAM), junto con la capacidad del procesador virtual (vCPU) y la red asociadas. A nivel de clúster, |
|
Cantidad de rendimiento de red en bytes por segundo recibida de los clientes y transmitida a ellos por cada instancia del clúster de base de datos de Neptune. Este rendimiento no incluye el tráfico de red entre las instancias del clúster de bases de datos y el volumen de clúster. |
|
Cantidad de rendimiento de red de salida en bytes por segundo transmitida a los clientes por cada instancia del clúster de base de datos de Neptune. Este rendimiento no incluye el tráfico de red entre las instancias del clúster de bases de datos y el volumen de clúster. |
NumIndexDeletesPerSec |
Número de eliminaciones de índices individuales. Las eliminaciones de cada índice se cuentan de forma individual. Esto incluye las eliminaciones que pueden revertirse si una consulta encuentra un error. |
NumIndexInsertsPerSec |
Número de inserciones en índices individuales. Las inserciones de cada índice se cuentan por separado. Esto incluye las inserciones que pueden revertirse si una consulta encuentra un error. |
NumIndexReadsPerSec |
Número de declaraciones escaneadas desde cualquier índice. Cualquier patrón de acceso comienza con una búsqueda en un índice y lee todas las sentencias coincidentes. Un aumento en esta métrica puede provocar un aumento en las latencias de las consultas o en el uso de la CPU. |
|
El número de errores del OpenCypher cliente por segundo. |
|
El número de OpenCypher solicitudes por segundo. |
|
El número de errores OpenCypher del servidor por segundo. |
|
El número de solicitudes en cola por segundo. |
|
Número de visitas a la caché de resultados de Gremlin. |
|
Número de errores en la caché de resultados de Gremlin. |
|
Número de transacciones confirmadas correctamente por segundo. |
|
Número de transacciones abiertas en el servidor por segundo. |
|
Para consultas de escritura, número de transacciones por segundo restauradas en el servidor debido a errores. En el caso de las consultas de solo lectura, esta métrica es igual al número de transacciones de solo lectura completadas por segundo. |
NumUndoPagesPurged |
Esta métrica indica el número de lotes purgados. Esta métrica es un indicador del progreso en la purga. El valor es 0 para las instancias de lectura y la métrica solo se aplica a la instancia de escritura. |
|
Número de solicitudes por segundo (tanto HTTPS como Bolt) al motor de openCypher. |
|
Número de conexiones Bolt abiertas a Neptune. |
|
Tamaño total estimado (en bytes) de todos los elementos en caché de la caché de resultados de Gremlin. |
|
Número de elementos en la caché de resultados de Gremlin. |
|
La marca de tiempo del elemento más antiguo almacenado en caché en la caché de resultados de Gremlin. |
|
La marca de tiempo del elemento más reciente guardado en caché en la caché de resultados de Gremlin. |
|
Como métrica a nivel de instancia, A nivel de clúster, |
|
La cantidad total de almacenamiento de copias de seguridad consumida por todas las instantáneas de un clúster de base de datos de Neptune determinado fuera de su periodo de retención de copia de seguridad en bytes. Se incluye en el total registrado por la métrica |
|
Número de errores del lado del cliente por segundo en las consultas SPARQL. |
|
Número de solicitudes al motor de SPARQL por segundo. |
|
El número de errores del servidor SPARQL por segundo. |
|
El número total de instrucciones escaneadas en busca de estadísticas de DFE desde que se inició el servidor. Cada vez que se activa el cálculo de estadísticas, este número aumenta y, cuando no se realiza ningún cálculo, permanece estático. Como resultado, si lo representa en un gráfico a lo largo del tiempo, puede saber cuándo se realizó el cálculo y cuándo no: 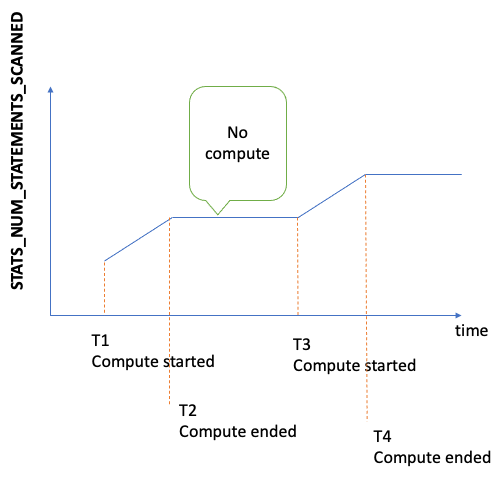
Al observar la pendiente del gráfico en los períodos en los que la métrica aumenta, también puede ver lo rápido que se realizó el cálculo. Si no existe esa métrica, significa que la característica de estadísticas está deshabilitada en el clúster de base de datos o que la versión del motor que está ejecutando no tiene la característica de estadísticas. Si el valor de la métrica es cero, significa que no se ha realizado ningún cálculo estadístico. |
|
La cantidad de rendimiento de red que recibe del subsistema de almacenamiento cada instancia del clúster de base de datos Neptune. |
StorageNetworkThroughput |
La cantidad de rendimiento de red que cada instancia del clúster de base de datos Neptune recibe y envía al subsistema de almacenamiento. |
|
La cantidad de rendimiento de red que cada instancia del clúster de base de datos Neptune envía al subsistema de almacenamiento. |
|
La cantidad de espacio de intercambio utilizada. |
|
El número de IOPS para lectura y escritura en el almacenamiento local conectado a la instancia de base de datos Neptune. Esta métrica representa un recuento y se mide una vez por segundo. |
|
La cantidad de datos transferidos hacia y desde el almacenamiento local asociado a la instancia de base de datos Neptune. Esta métrica representa un número de bytes y se mide una vez por segundo. |
|
La cantidad total de almacenamiento de copias de seguridad facturada para un clúster de base de datos de Neptune determinado en bytes. Incluye el almacenamiento de copias de seguridad medido por las métricas |
|
Número total de solicitudes por segundo dirigidas al servidor desde todos los orígenes. |
|
Número total por segundo de solicitudes que han dado error debido a problemas del lado del cliente. |
|
Número total por segundo de solicitudes en las que se ha producido un error en el servidor debido a errores internos. |
|
El recuento de registros de deshacer en la lista de registros de deshacer. Los registros de deshacer contienen registros de transacciones confirmadas que caducan cuando todas las transacciones activas son más recientes que la fecha de confirmación. Los registros caducados se depuran periódicamente. Los registros de las operaciones de eliminación pueden tardar más en depurarse que los registros de otros tipos de transacciones. La depuración la realiza exclusivamente la instancia de escritura del clúster de base de datos, por lo que la velocidad de depuración depende del tipo de instancia de escritura. Si el valor de Además, si está actualizando a la versión del motor |
|
La cantidad total de almacenamiento asignado al clúster de base de datos de Neptune, en bytes. Esta es la cantidad de almacenamiento por la que se le factura. Es la cantidad máxima de almacenamiento asignada al clúster de base de datos en cualquier momento de su existencia, no la cantidad que está utilizando actualmente (consulte Facturación del almacenamiento de Neptune). |
|
El número total de operaciones de E/S de lectura facturadas desde un volumen de clúster, informadas en intervalos de 5 minutos. Las operaciones de lectura facturadas se calculan en el nivel del volumen de clúster, agrupadas desde todas las instancias del clúster de base de datos de Neptune y notificadas a continuación a intervalos de 5 minutos. |
VolumeWriteIOPs |
El número total de operaciones de E/S del disco de escritura en el volumen del clúster, registrado en intervalos de 5 minutos. |
CloudWatch Métricas que ahora están en desuso en Neptune
Estas métricas están ahora en desuso. Siguen siendo compatibles, pero podrían eliminarse en el futuro cuando haya nuevas y mejores métricas disponibles.
Métrica |
Descripción |
|---|---|
|
Número de respuestas HTTP 1xx del punto de enlace de Gremlin por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de respuestas HTTP 2xx del punto de enlace de Gremlin por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 4xx del punto de enlace de Gremlin por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 5xx del punto de enlace de Gremlin por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores en recorridos Gremlin. |
|
Número de solicitudes al motor de Gremlin. |
|
Número de WebSocket conexiones correctas al punto final de Gremlin por segundo. |
|
Número de errores de WebSocket cliente en el punto final de Gremlin por segundo. |
|
Número de errores del WebSocket servidor en el punto final de Gremlin por segundo. |
|
Número de WebSocket conexiones potenciales disponibles actualmente. |
|
Número de respuestas HTTP 100 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de respuestas HTTP 101 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de respuestas HTTP 1xx del punto de enlace por segundo. |
|
Número de respuestas HTTP 200 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de respuestas HTTP 2xx del punto de enlace por segundo. |
|
Número de errores HTTP 400 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 403 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 405 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 413 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 429 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 4xx del punto de enlace por segundo. |
|
Número de errores HTTP 500 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 501 del punto de enlace por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 5xx del punto de enlace por segundo. |
|
Número de errores de las solicitudes del programa de carga. |
|
Número de solicitudes del programa de carga. |
|
Número de respuestas HTTP 1xx del punto de enlace de SPARQL por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de respuestas HTTP 2xx del punto de enlace de SPARQL por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 4xx del punto de enlace de SPARQL por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores HTTP 5xx del punto de enlace de SPARQL por segundo. Le recomendamos que utilice la nueva métrica combinada |
|
Número de errores en las consultas SPARQL. |
|
Número de solicitudes al motor de SPARQL. |
|
Número de errores del punto de enlace de estado. |
|
Número de solicitudes al punto de enlace de estado. |
