翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Chime SDK 通話分析データレイクを使用すると、機械学習を活用したインサイトやメタデータを Amazon Kinesis Data Streams から Amazon S3 バケットにストリーミングできます。例えば、データレイクを使用して、記録用の URL にアクセスすることが可能です。データレイクを作成するには、Amazon Chime SDK コンソールから、または を使用してプログラムで AWS CloudFormation テンプレートのセットをデプロイします AWS CLI。データレイクを使用すると、Amazon Athena の AWS Glue データテーブルを参照して、通話メタデータと音声分析データをクエリできます。
前提条件
Amazon Chime SDK データレイクを作成するには、次の機能が必要です。
-
1 つの Amazon Kinesis Data Streams。詳細については、「Amazon Kinesis Streams Developer Guide」の「Creating a Stream via the AWS Management Console」を参照してください。
-
S3 バケット 詳細については、「Amazon S3 ユーザーガイド」の「最初の S3 バケットを作成する」を参照してください。
データレイクの用語と概念
データレイクの仕組みを理解するには、次の用語と概念を参考にしてください。
- Amazon Kinesis Data Firehose
-
抽出、変換、ロード (ETL) サービス。これにより、ストリーミングデータをデータレイク、データストア、分析サービスに、確実にキャプチャ、変換、配信することが可能です。詳細については、「Amazon Kinesis Data Firehose とは何ですか?」を参照してください。
- Amazon Athena
-
Amazon Athena は、標準 SQL を使用して Amazon S3 のデータを分析できるインタラクティブなクエリサービスです。Athena は、サーバーレスであるため、インフラストラクチャを管理する必要がなく、料金は実行したクエリに対してのみ発生します。Athena を利用するには、Amazon S3 内のデータを指定してスキーマを定義し、標準 SQL クエリを使用します。また、ワークグループでユーザーをグループ化し、クエリの実行時にユーザーがアクセスできるリソースを制御することもできます。ワークグループを使用すると、クエリの同時実行を管理して、さまざまなユーザーグループやワークロードによるクエリ実行に優先順位を付けることが可能です。
- Glue Data Catalog
-
Amazon Athena のテーブルとデータベースには、基礎となるソースデータのスキーマを詳細に示すメタデータが格納されています。また、Athena では、データセットごとにテーブルが存在する必要があります。このテーブル内のメタデータによって Amazon S3 バケットの場所が判断されます。また、列名、データ型、テーブル名などのデータ構造も指定されます。データベースで保持されるのは、データセットのメタデータとスキーマ情報のみです。
複数のデータレイクを作成する
一意の Glue データベース名を指定して通話のインサイトを保存する場所を指定することで、複数のデータレイクを作成できます。特定の AWS アカウントには、対応するデータレイクを持つ複数の通話分析設定があります。つまり、特定のユースケースにデータ分離を適用することが可能です。例えば、保持ポリシーや、データの保存方法に関するアクセスポリシーなどをカスタマイズできます。インサイト、録音データ、メタデータへのアクセスに、さまざまなセキュリティポリシーを適用することも可能です。
リージョン別に見たデータレイクの可用性
Amazon Chime SDK データレイクは、次のリージョンで利用できます。
リージョン |
Glue テーブル |
Amazon QuickSight |
|---|---|---|
us-east-1 |
利用可能 |
利用可能 |
us-west-2 |
利用可能 |
利用可能 |
eu-central-1 |
利用可能 |
利用可能 |
データレイクのアーキテクチャ
データレイクのアーキテクチャを次の図に示します。図の数字は、次の各説明の番号に対応しています。
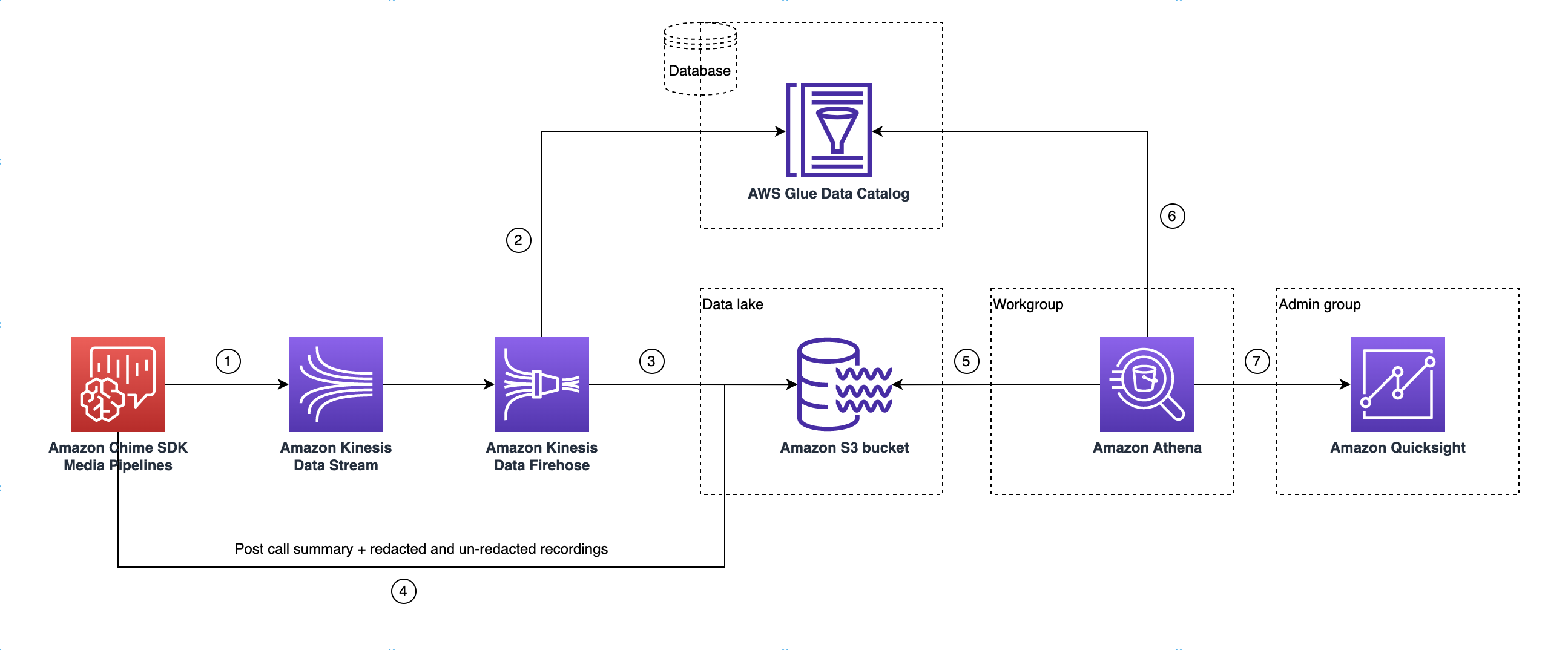
この図では、 AWS コンソールを使用してメディアインサイトパイプライン設定ワークフローから CloudFormation テンプレートをデプロイすると、次のデータが Amazon S3 バケットに流れます。
-
Amazon Chime SDK 通話分析によって、顧客の Kinesis Data Stream に対しリアルタイムデータのストリーミングが開始されます。
-
Amazon Kinesis Firehose では、128 MB まで蓄積される、または 60 秒が経過するまで (どちらか早い方が適用される)、このリアルタイムデータをバッファリングします。次の Firehose では、Glue データカタログの
amazon_chime_sdk_call_analytics_firehose_schemaを使用して、データを圧縮し、JSON レコードを Parquet 形式のファイルに変換します。 -
Parquet ファイルは、パーティション形式で Amazon S3 バケットに格納されます。
-
リアルタイムデータの他に、Amazon Transcribe Call Analytics の通話後概要データ .wav ファイル (設定で指定している場合、編集済みと未編集のファイル) と、通話録音の .wav ファイルも Amazon S3 バケットに送信されます。
-
Amazon Athena と標準 SQL を使用して、Amazon S3 バケット内のデータをクエリすることができます。
-
CloudFormation テンプレートでは、Glue データカタログも作成して、この通話後概要データを Athena 経由でクエリすることができます。
-
Amazon S3 バケットのデータはどれも、Amazon QuickSight を使用した視覚化が可能です。QuickSight では、Amazon Athena を使用して Amazon S3 バケットとの接続を確立します。
Amazon Athena テーブルでは、次の機能を使用して、クエリのパフォーマンスを最適化します。
- データのパーティション化
-
パーティショニングを行うと、テーブルが複数部分に分割され、日付、国、地域などの列の値に基づいて関連データがまとめられます。パーティションは仮想の列として機能します。この場合、テーブル作成時に CloudFormation テンプレートによってパーティションを定義します。これにより、クエリごとにスキャンされるデータの量が減少し、パフォーマンスが向上します。パーティションでフィルタリングして、クエリの際にスキャンするデータの量を制限することもできます。詳細については、「Amazon Athena ユーザーガイド」の「Athena でのデータのパーティション化」を参照してください。
次の例は、2023 年 1 月 1 日の日付を指定したパーティション構造を示しています。
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
DETAIL_TYPEには次のいずれかを指定します。-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- 列指向データストアの生成を最適化する
-
Apache Parquet では、列単位の圧縮、データ型に基づく圧縮、述語プッシュダウンを使用してデータを保存します。圧縮率を上げたり、データブロックをスキップしたりすると、Amazon S3 バケットから読み取るバイト数が減少するため、クエリのパフォーマンスが向上すると共に、コストが削減されます。こうした最適化のために、Amazon Kinesis Data Firehose では、JSON からパーケットへのデータ変換が有効になっています。
- パーティション射影
-
Athena のこの機能では、パーティションを日ごとに自動作成することで、日付ベースのクエリのパフォーマンスを向上させます。
データレイクをセットアップする
Amazon Chime SDK コンソールを使用して、次の手順を完了します。
-
Amazon Chime SDK コンソール (https://console.aws.amazon.com/chime-sdk/home
) を起動し、ナビゲーションペインの [通話分析] で [設定] を選択します。 -
[ステップ 1] を完了して [次へ] を選択し、[ステップ 2] ページの [音声分析] チェックボックスを選択します。
-
[出力の詳細] で [履歴による分析を行うためのデータウェアハウス] チェックボックスを選択し、[CloudFormation スタックをデプロイ] リンクを選択します。
CloudFormation コンソールの [スタックのクイック作成] ページに画面が切り替わります。
-
スタックの名前を入力し、次のパラメータを入力します。
-
DataLakeType— [通話分析のデータレイクを作成] を選択します。 -
KinesisDataStreamName— 対象のストリームを選択します。通話分析ストリーミングに使用するストリームを指定する必要があります。 -
S3BucketURI— Amazon S3 バケットを選択します。URI にはプレフィックスs3://が必要です。bucket-name -
GlueDatabaseName— 一意の AWS Glue データベース名を選択します。 AWS アカウント内の既存のデータベースは再利用できません。
-
-
確認のチェックボックスを選択し、[データレイクを作成] を選択します。データレイクの作成には、10 分かかります。
を使用したデータレイクのセットアップ AWS CLI
を使用して AWS CLI 、CloudFormation の create スタックを呼び出すアクセス許可を持つロールを作成します。次の手順に従って IAM ロールを作成しセットアップします。詳細については、「AWS CloudFormation ユーザーガイド」の「スタックの作成」を参照してください。
-
AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role ロールを作成して信頼ポリシーをそれにアタッチし、CloudFormation にそのロールを持たせることを許可します。
-
次のテンプレートを使用して IAM 信頼ポリシーを作成し、そのファイルを .json 形式で保存します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
aws iam create-role コマンドを実行し、信頼ポリシーをパラメータとして渡します。
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
レスポンスで返ったロール ARN を書き留めておきます。ロール ARN は次の手順で必要になります。
-
-
CloudFormation スタックの作成権限を持つポリシーを作成します。
-
次のテンプレートを使用して IAM ポリシーを作成し、そのファイルを .json 形式で保存します。create-policy を呼び出すときに、このファイルが必要となります。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
aws iam create-policy を実行し、スタック作成のポリシーをパラメータとして渡します。
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
レスポンスで返ったロール ARN を書き留めておきます。ロール ARN は次の手順で必要になります。
-
-
aws iam attach-role-policy ポリシーをロールにアタッチします。
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
CloudFormation スタックを作成し、次に示す必要なパラメータを入力します: aws cloudformation create-stack。
ParameterValue を使用して、各 ParameterKey のパラメータ値を指定します。
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
データレイクのセットアップによって作成されるリソース
データレイク作成によって作成されるリソースを次の表に示します。
リソースタイプ |
リソース名と説明 |
サービス名 |
|---|---|---|
AWS Glue データカタログデータベース |
GlueDatabaseName — 通話インサイトと音声分析に属するすべての AWS Glue データテーブルの論理的なグループ。 |
通話分析、音声分析 |
|
AWS Glue データカタログテーブル |
amazon_chime_sdk_call_analytics_firehose_schema — Kinesis Firehose に送られる通話分析と音声分析用の複合スキーマ。 |
通話分析、音声分析 |
call_analytics_metadata — 通話分析メタデータのスキーマ。SIPmetadata と OneTimeMetadata が含まれています。 |
コール分析 |
|
| call_analytics_recording_metadata — 録音および音声エンハンスメントメタデータのスキーマ。 | 通話分析、音声分析 | |
transcribe_call_analytics – TranscribeCallAnalytics ペイロード「utteranceEvent」のスキーマ。 |
コール分析 |
|
transcribe_call_analytics_category_events – TranscribeCallAnalytics ペイロード「categoryEvent」のスキーマ。 |
コール分析 |
|
transcribe_call_analytics_post_call – Transcribe の通話後分析概要ペイロードに使用するスキーマ。 |
コール分析 |
|
transcribe – Transcribe ペイロードのスキーマ。 |
コール分析 |
|
voice_analytics_status – 音声分析の準備状況を示すイベントのスキーマ。 |
音声分析 |
|
speaker_search_status – 識別一致に使用するスキーマ。 |
音声分析 |
|
voice_tone_analysis_status – ボイストーン分析イベントのスキーマ。 |
音声分析 |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-call-analytics- |
通話分析、音声分析 |
Amazon Athena ワークグループ |
GlueDatabaseName-AmazonChimeSDKDataAnalytics – クエリの実行時にアクセス可能なリソースを制御するための論理的なユーザーグループ。 |
通話分析、音声分析 |
