Amazon Forecast는 더 이상 신규 고객이 사용할 수 없습니다. Amazon Forecast의 기존 고객은 평소와 같이 서비스를 계속 사용할 수 있습니다. 자세히 알아보기
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
CNN-QR 알고리즘
Amazon Forecast CNN-QR(Convolution Neural Network - Quantile Regression)는 인과 컨벌루션 신경망(CNN)을 사용하여 스칼라(1차원적)를 예측하는 전용 기계 학습 알고리즘입니다. 이 지도 학습 알고리즘은 대규모 시계열 모음에서 하나의 글로벌 모델을 훈련하고 분위수 디코더를 사용하여 확률적 예측을 수행합니다.
CNN-QR 시작하기
CNN-QR을 사용하여 다음 두 가지 방법으로 예측기를 훈련할 수 있습니다.
-
CNN-QR 알고리즘 수동 선택.
-
AutoML 선택(CNN-QR은 AutoML의 일부입니다).
어떤 알고리즘을 사용해야 할지 잘 모르겠다면 AutoML을 선택하는 것이 좋습니다. Forecast는 CNN-QR이 데이터에 가장 정확한 알고리즘인 경우 CNN-QR을 선택합니다. CNN-QR이 가장 정확한 모델로 선택되었는지 확인하려면 DescribePredictor API를 사용하거나 콘솔에서 예측기 이름을 선택합니다.
CNN-QR의 몇 가지 주요 사용 사례는 다음과 같습니다.
-
데이터 세트가 크고 복잡한 예측 - CNN-QR은 크고 복잡한 데이터 세트로 훈련할 때 가장 효과적입니다. 신경망은 여러 데이터 세트에서 학습할 수 있으므로 관련 시계열과 항목 메타데이터가 있을 때 유용합니다.
-
과거 관련 시계열을 사용한 예측 - CNN-QR에서는 관련 시계열에 예측 기간 내의 데이터 포인트를 포함할 필요가 없습니다. 이러한 유연성이 추가되어 항목 가격, 이벤트, 웹 지표, 제품 범주와 같은 더 넓은 범위의 관련 시계열과 항목 메타데이터를 포함할 수 있습니다.
CNN-QR 작동 방식
CNN-QR은 확률적 예측을 위한 시퀀스 대 시퀀스(Seq2Seq) 모델로, 인코딩 시퀀스를 기준으로 예측이 디코딩 시퀀스를 얼마나 잘 재구성하는지 테스트합니다.
이 알고리즘은 인코딩 시퀀스와 디코딩 시퀀스에서 서로 다른 특성을 허용하므로 인코더에서 관련 시계열을 사용하고 디코더에서는 관련 시계열을 생략할 수 있습니다(반대의 경우도 마찬가지). 기본적으로 예측 기간에 데이터 포인트가 있는 관련 시계열이 인코더와 디코더 모두에 포함됩니다. 예측 기간에 데이터 포인트가 없는 관련 시계열은 인코더에만 포함됩니다.
CNN-QR은 학습 가능한 특성 추출기 역할을 하는 계층적 인과 관계 CNN을 사용하여 분위수 회귀를 수행합니다.
주말의 급증 같은 시간 의존적인 패턴을 쉽게 학습할 수 있도록 CNN-QR은 시계열 세분 수준을 기반으로 특성 시계열을 자동으로 생성합니다. 예를 들어 CNN-QR은 주간 시계열 빈도로 두 개의 특성 시계열(월중 날짜 및 연중 날짜)을 생성합니다. 이 알고리즘은 이 파생된 특성 시계열을 훈련 및 추론 중에 제공하는 사용자 지정 특성 시계열과 함께 사용합니다. 다음 예제는 대상 시계열 zi,t와 두 개의 파생 시계열 특성을 보여줍니다. ui,1,t는 하루 중 시간을 나타내고 ui,2,t는 요일을 나타냅니다.

CNN-QR은 데이터 빈도 및 훈련 데이터의 크기를 기반으로 이러한 특성 시계열을 자동으로 포함합니다. 다음 표는 지원되는 기본 시간 주기마다 파생될 수 있는 기능을 나열합니다.
| 시계열의 빈도 | 파생 요인(feature) |
|---|---|
| 분 | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| 시간 | hour-of-day, day-of-week, day-of-month, day-of-year |
| 일 | day-of-week, day-of-month, day-of-year |
| 주 | week-of-month, week-of-year |
| 월 | month-of-year |
훈련 중에 훈련 데이터 세트의 각 시계열은 인접 컨텍스트와 미리 정의된 길이가 고정된 예측 기간의 쌍으로 구성됩니다. 이것이 아래 그림에 나와 있습니다. 컨텍스트 기간은 녹색으로, 예측 기간은 파란색으로 표시됩니다.
주어진 훈련 세트에서 훈련된 모델을 사용하여 훈련 세트의 시계열 및 다른 시계열에 대한 예측을 생성할 수 있습니다. 훈련 데이터 세트는 대상 시계열로 구성되며, 대상 시계열은 관련 시계열 및 항목 메타데이터 목록에 연결될 수 있습니다.
다음 예제는 i로 색인화된 훈련 데이터 세트의 요소에서 어떻게 작동하는지 보여줍니다. 훈련 데이터 세트는 대상 시계열 zi,t과 두 개의 연결된 관련 시계열 xi,1,t 및 xi,2,t로 구성됩니다. 첫 번째 관련 시계열 xi,1,t는 미래 예측 시계열이고 두 번째 관련 시계열 xi,2,t는 과거 시계열입니다.
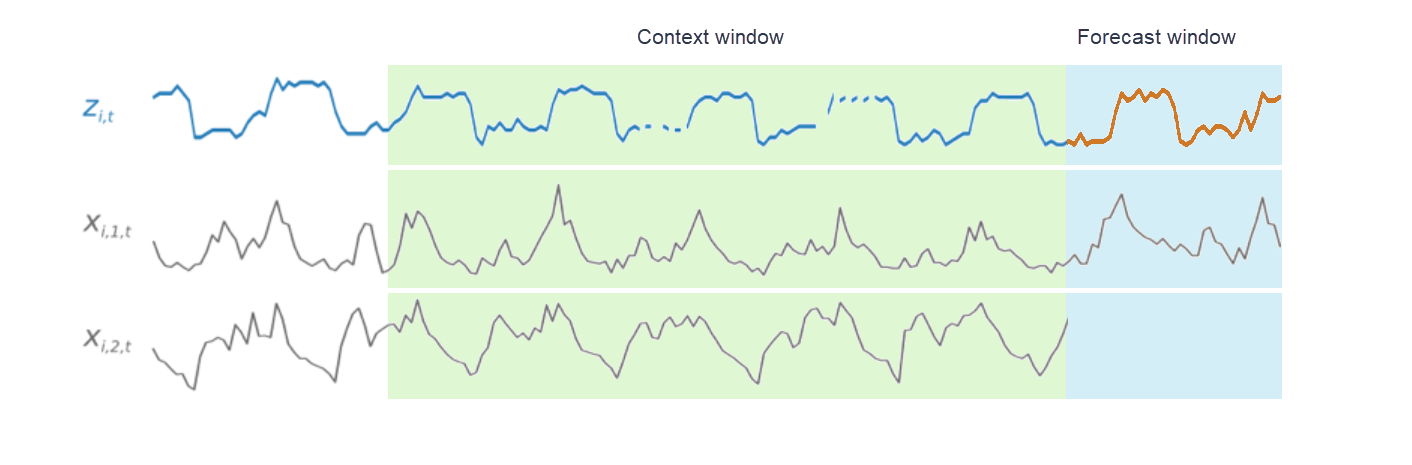
CNN-QR은 대상 시계열 zi,t와 관련 시계열 xi,1,t 및 xi,2,t에 걸쳐 학습하여 주황색 선으로 표시된 예측 기간에서 예측을 생성합니다.
CNN-QR에서 관련 데이터 사용
CNNQR은 과거 및 미래 예측 관련 시계열 데이터 세트를 모두 지원합니다. 미래 예측 관련 시계열 데이터 세트를 제공하는 경우 누락된 값은 앞으로 채우기 방법을 사용하여 채워집니다. 과거 및 미래 예측 관련 시계열에 대한 자세한 내용은 관련 시계열 데이터 세트 사용을 참조하세요.
CNN-QR에서 항목 메타데이터 데이터 세트를 사용할 수도 있습니다. 이것은 대상 시계열의 항목에 대한 정적 정보가 포함된 데이터 세트입니다. 항목 메타데이터는 과거 데이터가 거의 또는 전혀 없는 콜드 스타트 예측 시나리오에 특히 유용합니다. 항목 메타데이터에 대한 자세한 내용은 항목 메타데이터를 참조하세요.
CNN-QR 하이퍼파라미터
Amazon Forecast는 선택된 하이퍼파라미터에서 CNN-QR 모델을 최적화합니다. CNN-QR을 수동으로 선택하는 경우 이러한 하이퍼파라미터를 위한 훈련 파라미터를 전달할 수 있습니다. 다음 표에는 CNN-QR 알고리즘의 튜닝 가능한 하이퍼파라미터가 나열되어 있습니다.
| 파라미터 이름 | 값 | 설명 |
|---|---|---|
context_length |
|
예측을 하기 전에 모델이 읽는 시점의 수입니다. 일반적으로 CNN-QR의
|
use_related_data |
|
모델에 포함할 관련 시계열 데이터의 종류를 결정합니다. 다음 네 가지 옵션 중 하나를 선택하세요.
|
use_item_metadata |
|
모델에 항목 메타데이터가 포함되는지 여부를 결정합니다. 다음 두 가지 옵션 중 하나를 선택하세요.
|
epochs |
|
훈련 데이터에 통해 과정을 이수한 최대 횟수입니다. 데이터 세트가 작을수록 더 많은 에포크가 필요합니다.
|
하이퍼파라미터 최적화(HPO)
하이퍼파라미터 최적화(HPO)는 특정 학습 목표에 최적인 하이퍼파라미터를 선택하는 작업입니다. Forecast를 사용하면 다음 두 가지 방법으로 이 프로세스를 자동화할 수 있습니다.
-
AutoML을 선택하면 HPO가 CNN-QR을 위해 자동으로 실행됩니다.
-
CNN-QR을 수동으로 선택하고
PerformHPO = TRUE를 설정합니다.
관련 시계열 및 항목 메타데이터가 추가된다고 해서 CNN-QR 모델의 정확도가 항상 향상되는 것은 아닙니다. AutoML을 실행하거나 HPO를 활성화하면 CNN-QR은 제공된 관련 시계열 및 항목 메타데이터를 사용/사용하지 않고 모델의 정확도를 테스트하여 정확도가 가장 높은 모델을 선택합니다.
Amazon Forecast는 HPO 중에 다음 세 가지 하이퍼파라미터를 자동으로 최적화하고 최종 훈련된 값을 제공합니다.
-
context_length - 신경망이 얼마나 먼 과거까지 볼 수 있는지 결정합니다. HPO 프로세스는 훈련 시간을 고려하면서 모델 정확도를 극대화하는
context_length값을 자동으로 설정합니다. -
use_related_data - 모델에 포함할 관련 시계열 데이터의 형식을 결정합니다. HPO 프로세스는 관련 시계열 데이터가 모델을 개선하는지 여부를 자동으로 확인하고 최적의 설정을 선택합니다.
-
use_item_metadata - 모델에 항목 메타데이터를 포함할지 여부를 결정합니다. HPO 프로세스는 항목 메타데이터가 모델을 개선하는지 여부를 자동으로 확인하고 최적의 설정을 선택합니다.
참고
Holiday 보완 특성이 선택되었을 때 use_related_data가 NONE 또는 HISTORICAL로 설정된 경우 공휴일 데이터를 포함해도 모델 정확도가 향상되지 않습니다.
수동 선택 중에 PerformHPO = TRUE를 설정한 경우 context_length 하이퍼파라미터에 대한 HPO 구성을 설정할 수 있습니다. 하지만 AutoML을 선택하면 HPO 구성의 어떤 측면도 변경할 수 없습니다. HPO 구성에 대한 자세한 내용은 IntergerParameterRange API를 참조하세요.
팁과 모범 사례
큰 ForecastHorizon 값을 사용하지 마세요 - 100을 초과하는 ForecastHorizon 값을 사용하면 훈련 시간이 늘어나고 모델 정확도가 떨어질 수 있습니다. 앞으로 더 예측하기를 원한다면 더 높은 빈도로 집계하는 것을 고려하십시오. 예를 들어 1min 대신 5min을 사용하세요.
CNN은 더 긴 컨텍스트 길이를 허용합니다 - CNN은 일반적으로 RNN보다 더 효율적이므로 CNN-QR을 사용하면 DeepAR+보다 약간 높은 context_length를 설정할 수 있습니다.
관련 데이터의 특성 추출 - 모델을 훈련할 때 관련 시계열 및 항목 메타데이터를 다양하게 조합하여 실험하고 추가 정보가 정확도를 향상시키는지 평가하세요. 관련 시계열 및 항목 메타데이터를 다양하게 조합하고 변환하면 결과가 달라집니다.
CNN-QR은 평균 분위수에서 예측하지 않습니다 - CreateForecast API를 사용하여 ForecastTypes를 mean으로 설정하면 대신 중앙값 분위수(0.5 또는P50)에서 예측이 생성됩니다.
