O Amazon Forecast não está mais disponível para novos clientes. Os clientes existentes do Amazon Forecast podem continuar usando o serviço normalmente. Saiba mais
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Avaliação da precisão do preditor
O Amazon Forecast produz métricas de precisão para avaliar preditores e ajudar você a escolher quais usar para gerar previsões. O Forecast avalia os preditores usando as métricas Root Mean Square Error (RMSE), Weighted Quantile Loss (wQL), Mean Absolute Percentage Error (MAPE), Mean Absolute Scaled Error (MASE) e Weighted Absolute Percentage Error (WAPE).
O Amazon Forecast usa backtesting para ajustar parâmetros e produzir métricas de precisão. Durante o backtesting, o Forecast divide automaticamente seus dados de séries temporais em dois conjuntos: um conjunto de treinamento e um conjunto de testes. O conjunto de treinamento é usado para treinar um modelo e gerar previsões para pontos de dados no conjunto de testes. O Forecast avalia a precisão do modelo comparando os valores previstos com os valores observados no conjunto de testes.
O Forecast permite avaliar preditores usando diferentes tipos de previsão, que podem ser um conjunto de previsões de quantil e a previsão média. A previsão média fornece uma estimativa pontual, enquanto as previsões de quantil normalmente fornecem um intervalo de resultados possíveis.
Cadernos Python
Para obter um step-by-step guia sobre como avaliar métricas preditoras, consulte Métricas de computação usando backtests em nível de item
Tópicos
Interpretação de métricas de precisão
O Amazon Forecast fornece as métricas Root Mean Square Error (RMSE), Weighted Quantile Loss (wQL), Average Weighted Quantile Loss (Average wQL), Mean Absolute Scaled Error (MASE), Mean Absolute Percentage Error (MAPE) e Weighted Absolute Percentage Error (WAPE) para avaliar seus preditores. Junto com as métricas do preditor geral, o Forecast calcula as métricas de cada janela de backtest.
Você pode visualizar as métricas de precisão dos preditores usando o kit de desenvolvimento de software (SDK) e o console do Amazon Forecast.
nota
Na média das métricas Average wQL, wQL, RMSE, MASE, MAPE e WAPE, um valor menor indica um modelo superior.
Tópicos
Weighted Quantile Loss (wQL)
A métrica Weighted Quantile Loss (wQL) mede a precisão de um modelo em um quantil especificado. É particularmente útil quando há custos diferentes de subprevisão e superprevisão. Ao definir o peso (τ) da função wQL, você pode incorporar automaticamente diferentes penalidades por subprevisão e superprevisão.
A função de perda é calculada da seguinte forma.
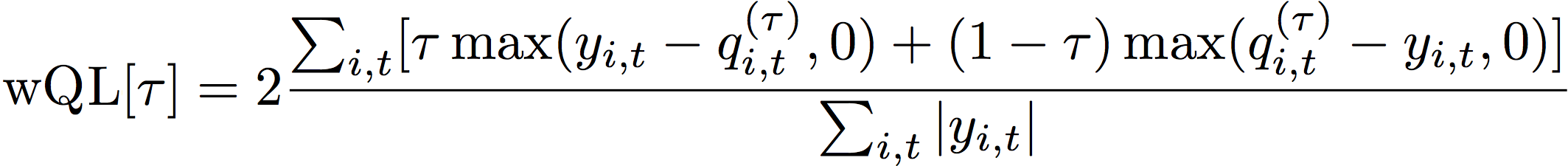
- Em que:
-
τ - um quantil no conjunto {0.01, 0.02, ..., 0.99}
qi,t(τ) - o quantil τ que o modelo prevê.
yi,t - o valor observado no ponto (i,t)
Os quantis (τ) de wQL podem variar de 0.01 (P1) a 0.99 (P99). A métrica wQL não pode ser calculada para a previsão média.
Por padrão, o Forecast calcula a wQL em 0.1 (P10), 0.5 (P50) e 0.9 (P90).
-
P10 (0.1): espera-se que o valor verdadeiro seja menor do que o valor previsto 10% do tempo.
-
P50 (0.5): espera-se que o valor verdadeiro seja menor do que o valor previsto 50% do tempo. Isso também é conhecido como previsão mediana.
-
P90 (0.9): espera-se que o valor verdadeiro seja menor do que o valor previsto 90% do tempo.
No varejo, o custo de estar com estoque insuficiente é geralmente maior do que o custo de estar com excesso de estoque . Portanto, a previsão em P75 (τ = 0.75) pode ser mais informativa do que a previsão no quantil médio (P50). Nesses casos, wQL[0.75] atribui um peso de penalidade maior à subprevisão (0,75) e um peso de penalidade menor à superprevisão (0,25).
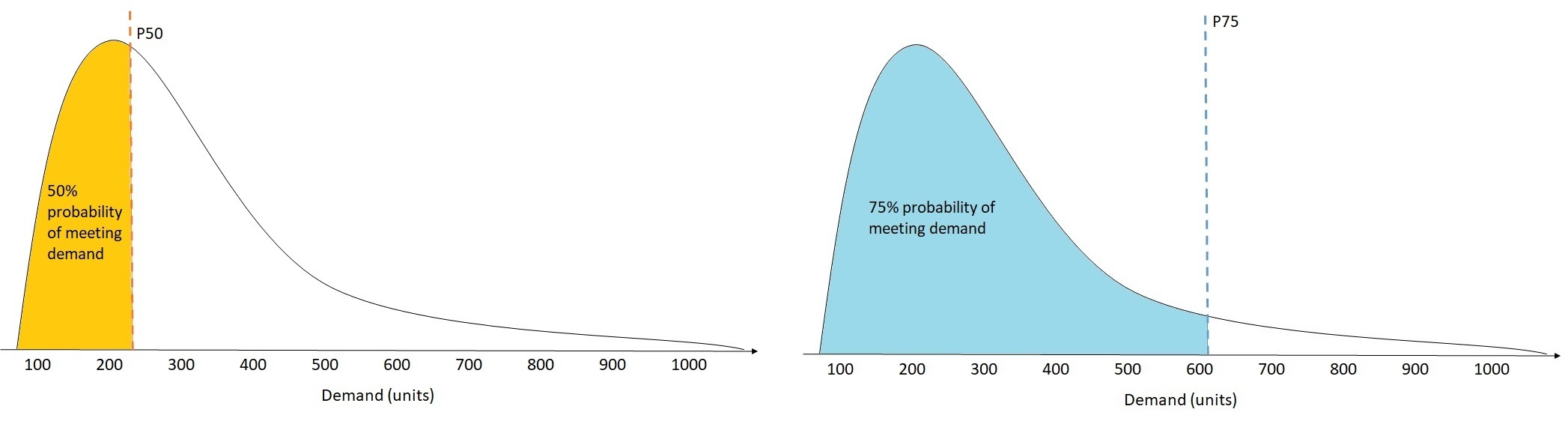
A figura acima mostra as diferentes previsões de demanda em wQL[0.50] e wQL[0.75]. O valor previsto em P75 é significativamente maior do que o valor previsto em P50 porque se espera que a previsão P75 atenda à demanda 75% do tempo, enquanto a previsão P50 só atenda à demanda 50% do tempo.
Quando a soma dos valores observados em todos os itens e pontos no tempo for aproximadamente zero em determinada janela de backtest, a expressão de perda de quantil ponderada será indefinida. Nesse caso, o Forecast gera a perda de quantil não ponderada, que é o numerador na expressão wQL acima.
O Forecast também calcula o wQL médio, que é o valor médio das perdas de quantil ponderadas em todos os quantis especificados. Por padrão, essa será a média de wQL[0.10], wQL[0.50] e wQL[0.90].
Weighted Absolute Percentage Error (WAPE)
A métrica Weighted Absolute Percentage Error (WAPE) mede o desvio geral dos valores previstos a partir dos valores observados. O WAPE é calculado tomando a soma dos valores observados e a soma dos valores previstos e calculando o erro entre esses dois valores. Um valor mais baixo indica um modelo mais preciso.
Quando a soma dos valores observados em todos os itens e pontos no tempo for aproximadamente zero em determinada janela de backtest, a expressão de erro de perda de quantil ponderada será indefinida. Nesse caso, o Forecast gera a soma de erros absolutos não ponderados, que é o numerador na expressão WAPE.
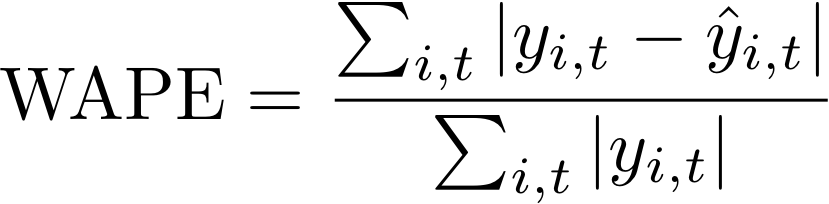
- Em que:
-
yi,t - o valor observado no ponto (i,t)
ŷi,t - o valor previsto no ponto (i,t)
O Forecast usa a previsão média como valor previsto, ŷi,t.
O WAPE é mais robusto a valores discrepantes do que o Root Mean Square Error (RMSE) porque usa o erro absoluto em vez do erro quadrático.
Anteriormente, a Amazon Forecast se referia à métrica WAPE como Mean Absolute Percentage Error (MAPE) e usava a previsão mediana (P50) como valor previsto. O Forecast agora usa a previsão média para calcular o WAPE. A métrica wQL[0.5] é equivalente à métrica WAPE[median], conforme mostrado abaixo:
![Mathematical equation showing the equivalence of wQL[0.5] and WAPE[median] metrics.](images/wql-to-wape.PNG)
Root Mean Square Error (RMSE)
A métrica Root Mean Square Error (RMSE) é a raiz quadrada da média dos erros quadrados e, portanto, é mais sensível a valores discrepantes do que outras métricas de precisão. Um valor mais baixo indica um modelo mais preciso.
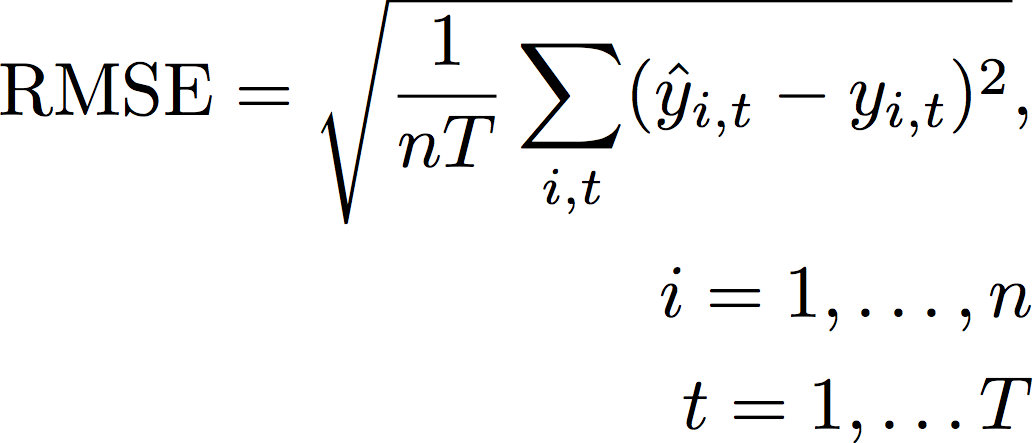
- Em que:
-
yi,t - o valor observado no ponto (i,t)
ŷi,t - o valor previsto no ponto (i,t)
nT - o número de pontos de dados em um conjunto de testes
O Forecast usa a previsão média como valor previsto, ŷi,t. Ao calcular as métricas do preditor, nT é o número de pontos de dados em uma janela de backtest.
O RMSE usa o valor quadrático dos resíduos, o que aumenta o impacto dos valores discrepantes. Nos casos de uso em que apenas algumas grandes previsões erradas podem ser muito caras, o RMSE é a métrica mais relevante.
Os preditores criados antes de 11 de novembro de 2020 calcularam o RMSE usando o quantil de 0,5 (P50) por padrão. O Forecast agora usa a previsão média.
Mean Absolute Percentage Error (MAPE)
A métrica Mean Absolute Percentage Error (MAPE) toma o valor absoluto do erro percentual entre os valores observados e previstos para cada unidade de tempo e, em seguida, calcula a média desses valores. Um valor mais baixo indica um modelo mais preciso.
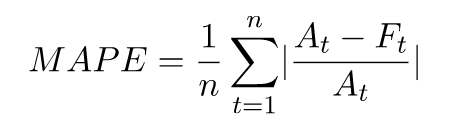
- Em que:
-
At - o valor observado no ponto t
Ft - o valor previsto no ponto t
n - o número de pontos de dados na série temporal
O Forecast usa a previsão média como valor previsto, Ft.
O MAPE é útil nos casos em que os valores diferem significativamente entre os pontos no tempo e os valores discrepantes têm um impacto significativo.
Mean Absolute Scaled Error (MASE)
A métrica Mean Absolute Scaled Error (MASE) é calculada dividindo o erro médio por um fator de escalabilidade. Esse fator de escalabilidade depende do valor da sazonalidade, m, que é selecionado com base na frequência da previsão. Um valor mais baixo indica um modelo mais preciso.
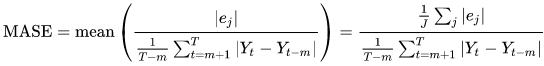
- Em que:
-
Yt - o valor observado no ponto t
Yt-m - o valor observado no ponto t-m
e j - o erro no ponto j (valor observado - valor previsto)
m - o valor da sazonalidade
O Forecast usa a previsão média como valor previsto.
O MASE é ideal para conjuntos de dados de natureza cíclica ou com propriedades sazonais. Por exemplo, a previsão de itens com alta demanda durante o verão e com baixa demanda durante o inverno pode se beneficiar ao considerar o impacto sazonal.
Exportação de métricas de precisão
nota
Os arquivos de exportação podem retornar diretamente informações da importação do conjunto de dados. Isso tornará os arquivos vulneráveis à injeção de CSV se os dados importados contiverem fórmulas ou comandos. Por esse motivo, os arquivos exportados poderão gerar avisos de segurança. Para evitar atividades mal intencionadas, desabilite os links e as macros ao realizar a leitura de arquivos exportados.
O Forecast permite que você exporte os valores previstos e as métricas de precisão gerados durante o backtesting.
Você pode usar essas exportações para avaliar itens específicos em pontos no tempo e quantis específicos e entender melhor seu preditor. As exportações de backtest são enviadas para um local específico do S3 e contêm duas pastas:
-
forecasted-values: contém arquivos CSV ou Parquet com valores previstos em cada tipo de previsão para cada backtest.
-
accuracy-metrics-values: contém arquivos CSV ou Parquet com métricas para cada backtest, junto com a média de todos os backtests. Essas métricas incluem métrica wQL de cada quantil, bem como a média de wQL, RMSE, MASE, MAPE e WAPE.
A pasta forecasted-values contém valores previstos em cada tipo de previsão para cada janela de backtest. Também inclui informações sobre itens IDs, dimensões, registros de data e hora, valores-alvo e horários de início e término da janela de backtest.
A pasta accuracy-metrics-values contém métricas de precisão para cada janela de backtest, bem como a média das métricas em todas as janelas de backtest. Ela contém a métrica wQL de cada quantil especificado, bem como a média das métricas wQL, RMSE, MASE, MAPE e WAPE.
Os arquivos em ambas as pastas seguem a convenção de nomenclatura: <ExportJobName>_<ExportTimestamp>_<PartNumber>.csv.
Você pode exportar as métricas de precisão usando o kit de desenvolvimento de software (SDK) e o console do Amazon Forecast.
Como escolher os tipos de previsão
O Amazon Forecast usa tipos de previsão para criar previsões e avaliar preditores. Os tipos de previsão do Forecast são fornecidos de duas maneiras:
-
Tipo de previsão média: uma previsão que usa a média como valor esperado. Normalmente usado como previsões pontuais em um determinado ponto no tempo.
-
Tipo de previsão de quantil: uma previsão em um quantil especificado. Normalmente usado para fornecer um intervalo de previsão, que é uma faixa de valores possíveis para contabilizar a incerteza da previsão. Por exemplo, uma previsão no quantil
0.65estimará um valor menor do que o valor observado 65% do tempo.
Por padrão, o Forecast usa os seguintes valores para os tipos de previsão de preditor: 0.1 (P10), 0.5 (P50) e 0.9 (P90). Você pode escolher até cinco tipos de previsão personalizados, incluindo mean e quantis que variam de 0.01 (P1) a 0.99 (P99).
Os quantis podem fornecer um limite superior e inferior para previsões. Por exemplo, o uso dos tipos de previsão 0.1 (P10) e 0.9 (P90) fornece uma faixa de valores conhecida como intervalo de confiança de 80%. Espera-se que o valor observado seja menor que o valor P10 em 10% do tempo e que o valor P90 seja maior que o valor observado em 90% do tempo. Ao gerar previsões em p10 e P90, espera-se que o valor verdadeiro fique entre esses limites 80% do tempo. Essa faixa de valores é representada pela região sombreada entre P10 e P90 na figura abaixo.
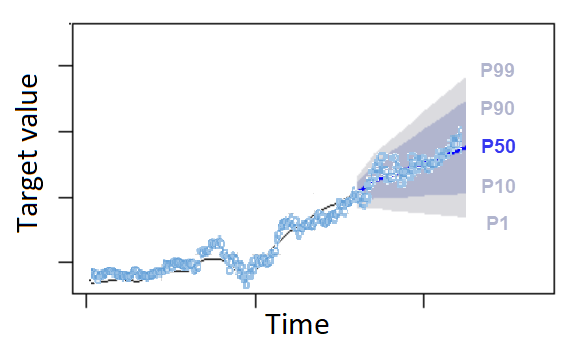
Você também pode usar uma previsão de quantil como previsão pontual quando o custo da subprevisão diferir do custo da superprevisão. Por exemplo, em alguns casos de varejo, o custo de ter um estoque insuficiente é maior do que o custo de ter um estoque excessivo. Nesses casos, a previsão em 0,65 (P65) é mais informativa do que a previsão mediana (P50) ou média.
Ao treinar um preditor, você pode escolher tipos de previsão personalizados usando o kit de desenvolvimento de software (SDK) e o console do Amazon Forecast.
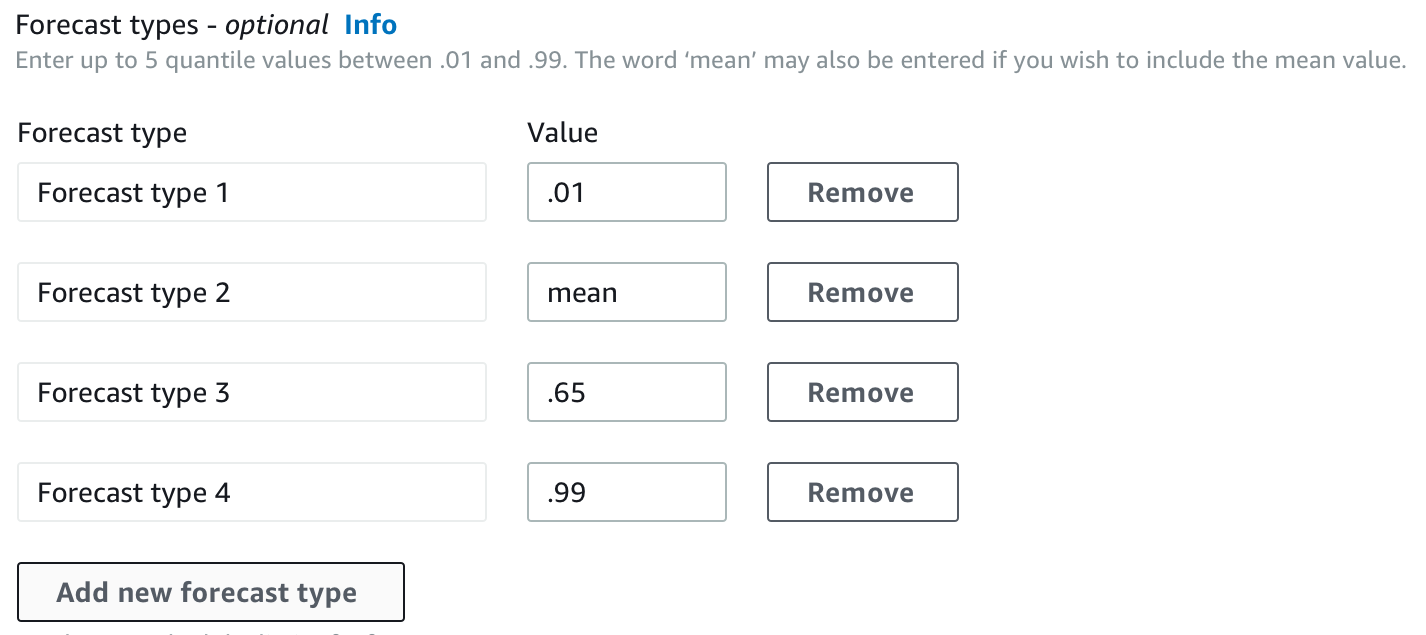
Como trabalhar com preditores antigos
Definição de parâmetros de backtesting
O Forecast usa o backtesting para calcular métricas de precisão. Se você executar vários backtests, o Forecast calculará a média de cada métrica em todas as janelas de backtest. Por padrão, o Forecast calcula um backtest assumindo que o tamanho da janela do backtest (conjunto de testes) é igual ao comprimento do horizonte de previsão (janela de previsão). Você pode definir o tamanho da janela de backtest e o número de cenários de backtest ao treinar um preditor.
O Forecast omite os valores preenchidos do processo de backtesting, e qualquer item com valores preenchidos em uma determinada janela de backtest será excluído desse backtest. Isso ocorre porque o Forecast só compara os valores previstos com os valores observados durante o backtesting, e os valores preenchidos não são valores observados.
A janela de backtest deve ter, no mínimo, o comprimento do horizonte de previsão e ser menor que a metade do comprimento de todo o conjunto de dados de séries temporais de destino. Você pode escolher entre 1 e 5 backtests.
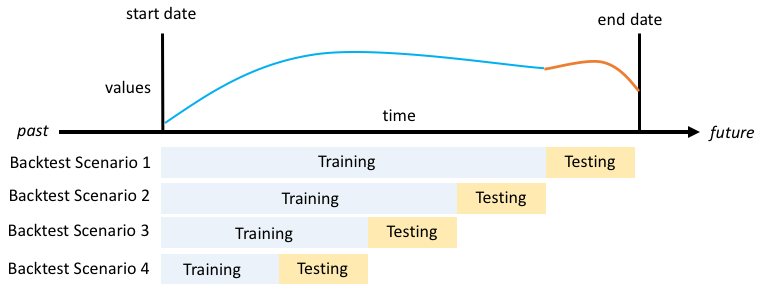
Geralmente, aumentar o número de backtests produz métricas de precisão mais confiáveis, já que uma parte maior da série temporal é usada durante o teste e o Forecast é capaz de calcular a média das métricas em todos os backtests.
Você pode definir os parâmetros de backtesting usando o kit de desenvolvimento de software (SDK) e o console do Amazon Forecast.

HPO e AutoML
Por padrão, o Amazon Forecast usa os quantis 0.1 (P10), 0.5 (P50) e 0.9 (P90) para ajuste de hiperparâmetros durante a otimização de hiperparâmetros (HPO) e para seleção de modelos durante o AutoML. Se você especificar tipos de previsão personalizados ao criar um preditor, o Forecast usará esses tipos de previsão durante o HPO e o AutoML.
Se forem especificados tipos de previsão personalizados, o Forecast usará esses tipos de previsão especificados para determinar os melhores resultados durante o HPO e o AutoML. Durante o HPO, o Forecast usa a primeira janela de backtest para encontrar os valores ideais dos hiperparâmetros. Durante o AutoML, o Forecast usa as médias em todas as janelas de backtest e os valores ideais dos hiperparâmetros do HPO para encontrar o algoritmo ideal.
Para o AutoML e o HPO, o Forecast escolhe a opção que minimiza as perdas médias nos tipos de previsão. Você também pode otimizar seu preditor durante o AutoML e o HPO com uma das seguintes métricas de precisão: Average Weighted Quantile loss (Average wQL), Weighted Absolute Percentage Error (WAPE), Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE) ou Mean Absolute Scaled Error (MASE).
Você pode escolher a métrica de otimização usando o kit de desenvolvimento de software (SDK) e o console do Amazon Forecast.
