Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Partitionnement des locuteurs (diarisation)
Grâce à la diarisation des haut-parleurs, vous pouvez faire la distinction entre les différents locuteurs dans votre sortie de transcription. Amazon Transcribe peut différencier un maximum de 30 locuteurs uniques et étiqueter le texte de chaque locuteur avec une valeur unique (spk_0jusqu'àspk_29).
Outre les sections de transcription standard (transcripts et items), les demandes pour lesquelles le partitionnement des locuteurs est activé incluent une section speaker_labels. Cette section est regroupée par locuteur et contient des informations sur chaque énoncé, notamment l’étiquette du locuteur et des horodatages.
"speaker_labels": { "channel_label": "ch_0", "speakers": 2, "segments": [ { "start_time": "4.87", "speaker_label": "spk_0", "end_time": "6.88", "items": [ { "start_time": "4.87", "speaker_label": "spk_0", "end_time": "5.02" },...{ "start_time": "8.49", "speaker_label": "spk_1", "end_time": "9.24", "items": [ { "start_time": "8.49", "speaker_label": "spk_1", "end_time": "8.88" },
Pour consulter un exemple de transcription complet avec partitionnement des locuteurs (pour deux locuteurs), consultez la section Exemple de sortie de diarisation (lot).
Partitionnement des locuteurs dans une transcription par lots
Pour partitionner des locuteurs dans une transcription par lots, consultez les exemples suivants :
-
Connectez-vous à la Console de gestion AWS
. -
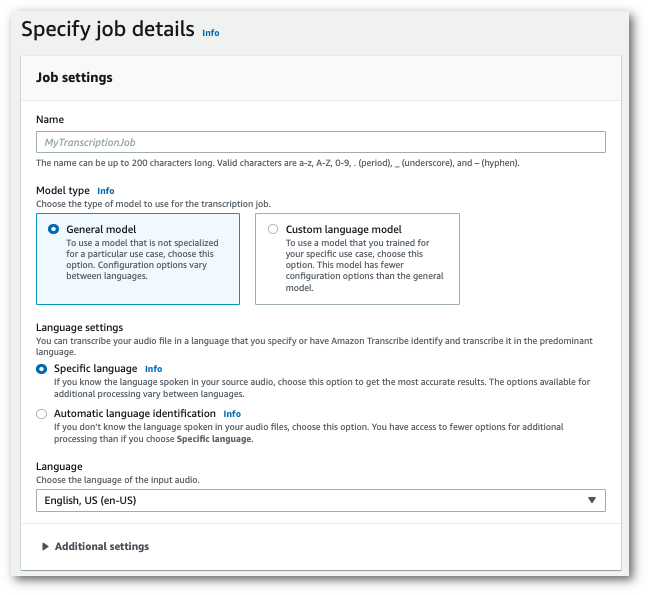
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre.
-
Renseignez les champs que vous souhaitez inclure sur la page Spécifier les détails de la tâche, puis sélectionnez Suivant. Vous accédez alors à la page Configurer la tâche - facultatif.
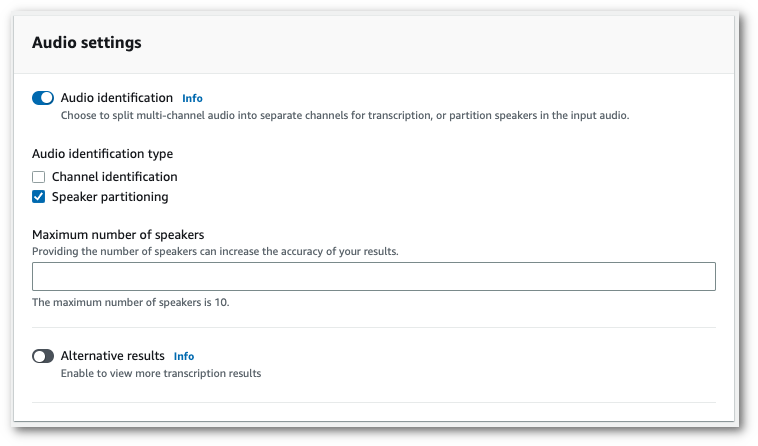
Pour activer le partitionnement des haut-parleurs, dans les paramètres audio, choisissez Identification audio. Choisissez ensuite Partitionnement des haut-parleurs et spécifiez le nombre de haut-parleurs.
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
Cet exemple utilise la commande start-transcription-jobStartTranscriptionJob.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ShowSpeakerLabels=true,MaxSpeakerLabels=3
Voici un autre exemple utilisant la commande start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-transcription-job.json
Le fichier my-first-transcription-job.json contient le corps de requête suivant.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ShowSpeakerLabels": 'TRUE', "MaxSpeakerLabels":3}
Cet exemple utilise le AWS SDK pour Python (Boto3) pour identifier les canaux à l'aide de la méthode start_transcription_job
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'ShowSpeakerLabels': True, 'MaxSpeakerLabels':3} ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Partitionnement des locuteurs dans une transcription en streaming
Pour partitionner des locuteurs dans une transcription en streaming, consultez les exemples suivants :
-
Connectez-vous à la Console de gestion AWS
. -
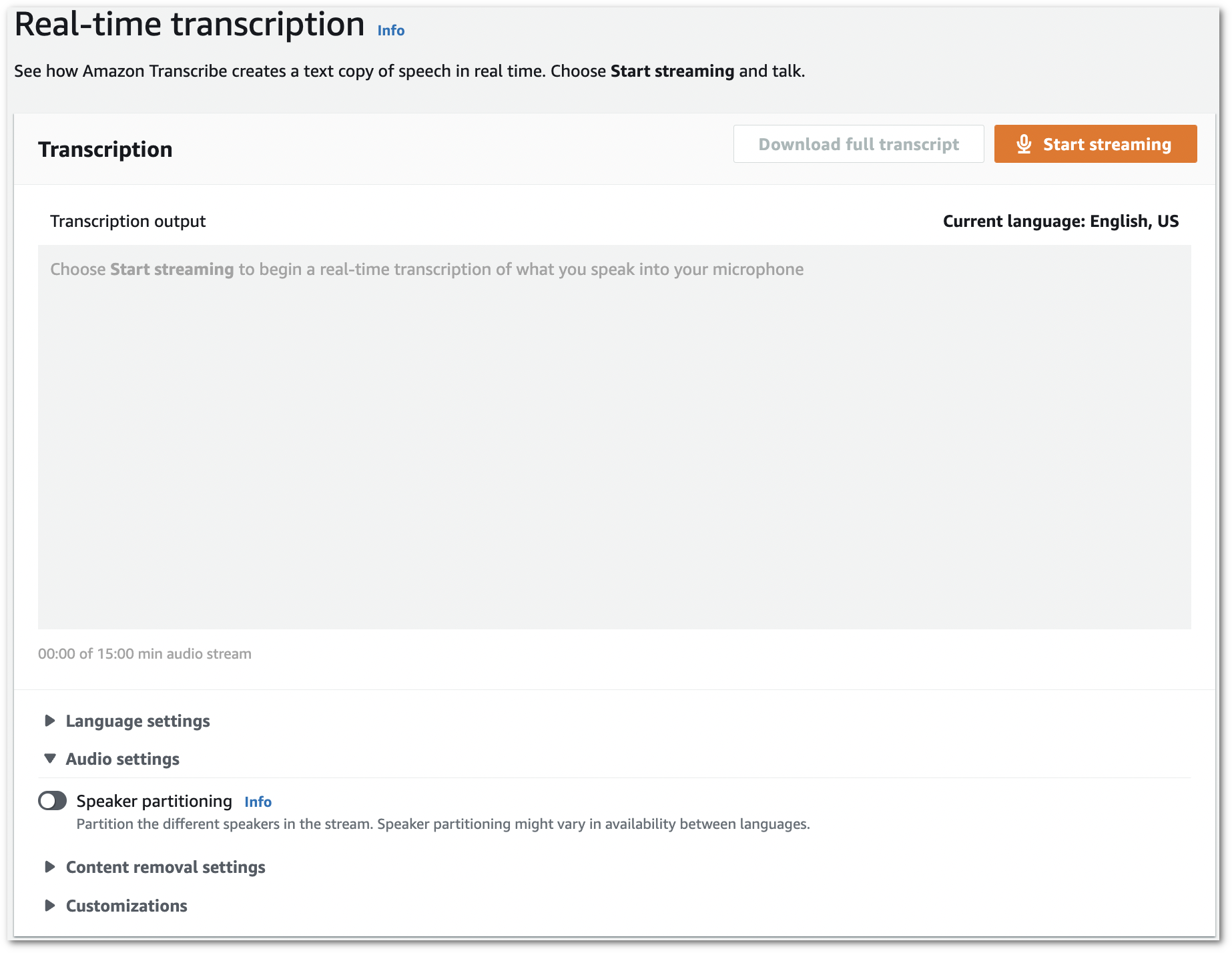
Dans le volet de navigation, choisissez Real-time Transcription. Faites défiler jusqu’à Paramètres audio et développez ce champ s’il est réduit.
-
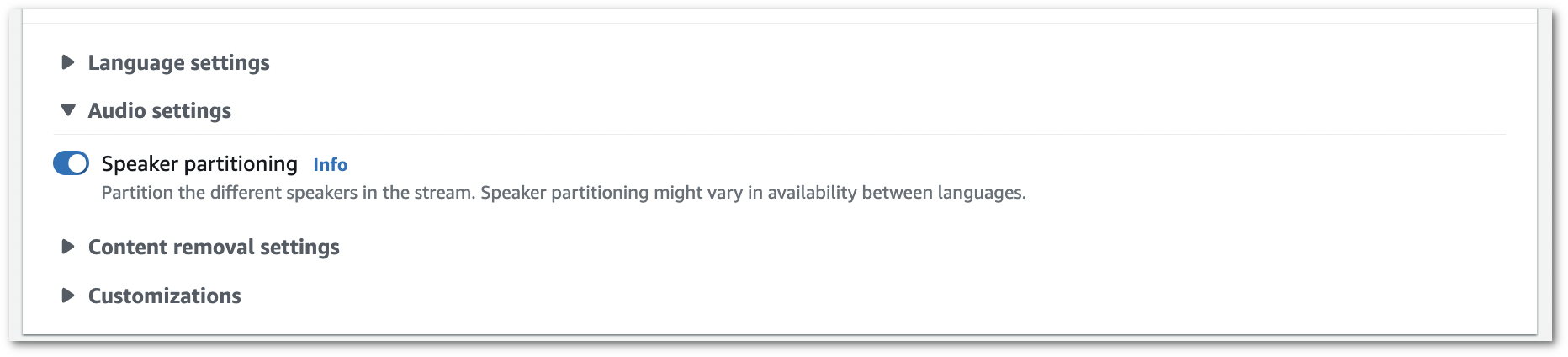
Activez Partitionnement des locuteurs.
-
Vous êtes prêt à transcrire votre flux. Sélectionnez Démarrer le streaming et commencez à parler. Pour mettre fin à votre dictée, sélectionnez Arrêter le streaming.
Cet exemple crée une HTTP/2 demande qui partitionne les haut-parleurs dans votre sortie de transcription. Pour plus d'informations sur l'utilisation du HTTP/2 streaming avec Amazon Transcribe, consultezConfiguration d'un HTTP/2 stream. Pour plus de détails sur les paramètres et les en-têtes spécifiques à Amazon Transcribe, consultez la section StartStreamTranscription.
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-show-speaker-label: true transfer-encoding: chunked
Les définitions des paramètres se trouvent dans la référence d'API ; les paramètres communs à toutes les opérations d' AWS API sont répertoriés dans la section Paramètres communs.
Cet exemple crée une URL présignée qui sépare les locuteurs dans votre sortie de transcription. Les sauts de ligne ont été ajoutés pour faciliter la lecture. Pour plus d'informations sur l'utilisation WebSocket des flux avec Amazon Transcribe, consultezConfiguration d'un WebSocket stream. Pour plus de détails sur les paramètres, consultez la section StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US &specialty=PRIMARYCARE&type=DICTATION&media-encoding=flac&sample-rate=16000&show-speaker-label=true
Les définitions des paramètres se trouvent dans la référence d'API ; les paramètres communs à toutes les opérations d' AWS API sont répertoriés dans la section Paramètres communs.
