Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisez l’identification des langues par lots pour identifier automatiquement la ou les langues de votre fichier multimédia.
Si votre fichier multimédia ne contient qu’une seule langue, vous pouvez activer l’identification d’une langue unique, qui identifie la langue dominante parlée dans votre fichier multimédia et crée votre transcription en utilisant uniquement cette langue.
Si votre fichier multimédia contient plusieurs langues, vous pouvez activer l’identification multilingue, qui identifie toutes les langues parlées dans votre fichier multimédia et crée votre transcription en utilisant chaque langue identifiée. Notez qu’une transcription multilingue est produite. Vous pouvez utiliser d'autres services Amazon Translate, tels que la traduction de votre relevé de notes.
Reportez-vous au tableau des langues prises en charge pour obtenir la liste complète des langues prises en charge et des codes de langue associés.
Pour de meilleurs résultats, assurez-vous que votre fichier multimédia contient au moins 30 secondes de parole.
Pour des exemples d'utilisation avec le SDK AWS Management Console AWS CLI,, et AWS Python, consultezUtilisation de l’identification des langues avec des transcriptions par lots.
Identification des langues dans un audio multilingue
L’identification multilingue est destinée aux fichiers multimédias multilingues. Elle fournit une transcription qui reflète toutes les langues prises en charge parlées dans votre média. Cela signifie que si les locuteurs changent de langue en cours de conversation, ou si chaque participant parle une langue différente, votre sortie de transcription détecte et transcrit correctement chaque langue. Par exemple, si votre média contient un locuteur bilingue qui alterne entre l’anglais américain (en-US) et l’hindi (hi-IN), l’identification multilingue peut identifier et transcrire l’anglais américain comme en-US et l’hindi parlé comme hi-IN.
Cela diffère de l’identification dans d’une seule langue, où une seule langue dominante est utilisée pour créer une transcription. Dans ce cas, toute langue parlée qui n’est pas la langue dominante est incorrectement transcrite.
Note
L’expurgation et les modèles de langue personnalisés ne sont actuellement pas pris en charge avec l’identification multilingue.
Note
Les langues suivantes sont actuellement prises en charge avec une identification multilingue : en-AB, en-AU, en-GB, en-IE, en-NZ, en-US, en-WL, en-ZA, es-ES, es-US, fr-CA, fr-FR, zh-CN, zh-TW, pt-BR, pt-PT, de-CH, de-DE, af-ZA, ar-AE, da-DK, he-IL, hi-in, ID-ID, Fa-ir, It-it, Ja-JP, Ko-KR, MS-My, NL-NL, Ru-ru, Ta-in, Te-in, Th-TH, TR-TR
Les transcriptions multilingues fournissent un récapitulatif des langues détectées et le temps total pendant lequel chaque langue est parlée dans vos médias. Voici un exemple :
"results": {
"transcripts": [
{
"transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す"
}
],
...
"language_codes": [
{
"language_code": "en-US",
"duration_in_seconds": 2.45
},
{
"language_code": "hi-IN",
"duration_in_seconds": 5.325
},
{
"language_code": "ja-JP",
"duration_in_seconds": 4.15
}
]
}Amélioration de la précision de l’identification des langues
L’identification des langues vous permet d’inclure la liste des langues que vous pensez être présentes dans vos médias. L'inclusion des options de langue (LanguageOptions) limite Amazon Transcribe l'utilisation des seules langues que vous spécifiez lorsque vous associez votre audio à la bonne langue, ce qui peut accélérer l'identification de la langue et améliorer la précision associée à l'attribution du dialecte linguistique approprié.
Si vous choisissez d’inclure des codes de langue, vous devez en inclure au moins deux. Il n’y a aucune limite quant au nombre de codes de langue que vous pouvez inclure, mais nous vous recommandons d’en utiliser entre deux et cinq pour une efficacité et une précision optimales.
Note
Si vous incluez des codes de langue dans votre demande et qu'aucun des codes de langue que vous fournissez ne correspond à la langue ou aux langues identifiées dans votre audio, Amazon Transcribe sélectionne la langue la plus proche parmi les codes de langue que vous avez spécifiés. Une transcription dans cette langue est ensuite générée. Par exemple, si votre contenu multimédia est en anglais américain (en-US) et que vous Amazon Transcribe fournissez les codes de languezh-CN, et fr-FRde-DE, Amazon Transcribe il est probable que votre contenu corresponde à l'allemand (de-DE) et produira une transcription en allemand. La non-concordance entre les codes de langue et les langues parlées peut entraîner une transcription inexacte. Nous vous recommandons donc de faire preuve de prudence lorsque vous incluez des codes de langue.
Combinaison de l’identification des langues avec d’autres fonctionnalités Amazon Transcribe
Vous pouvez utiliser l’identification des langues par lots en combinaison avec toute autre fonctionnalité Amazon Transcribe . Si vous associez l’identification des langues à d’autres fonctionnalités, vous êtes limité aux langues prises en charge par ces fonctionnalités. Par exemple, si vous utilisez l'identification de la langue pour la rédaction de contenu, vous êtes limité à l'anglais américain (en-US) ou à l'espagnol américain (es-US), car il s'agit de la seule langue disponible pour la rédaction. Pour plus d’informations, consultez la section Langues prises en charge et fonctionnalités spécifiques aux langues.
Important
Si vous utilisez l'identification automatique de la langue avec la rédaction de contenu activée et que votre fichier audio contient des langues autres que l'anglais américain (en-US) ou l'espagnol américain (es-US), seul le contenu en anglais américain ou en espagnol américain est expurgé dans votre transcription. Les autres langues ne peuvent pas être expurgées et il n’y a aucun avertissement ni échec de la tâche.
Modèles de langue personnalisés, vocabulaires personnalisés et filtres de vocabulaires personnalisés
Si vous souhaitez ajouter un ou plusieurs modèles de langue personnalisés, vocabulaires personnalisés ou filtres de vocabulaires personnalisés à votre demande d’identification des langues, vous devez inclure le paramètre LanguageIdSettings. Vous pouvez ensuite spécifier un code de langue avec un modèle de langue personnalisé, un vocabulaire personnalisé et un filtre de vocabulaire personnalisé correspondants. Notez que l’identification multilingue ne prend pas en charge les modèles de langue personnalisés.
Il est recommandé d’inclure LanguageOptions lorsque vous utilisez LanguageIdSettings pour vous assurer que le bon dialecte linguistique est identifié. Par exemple, si vous spécifiez un vocabulaire en-US personnalisé, mais que vous Amazon Transcribe déterminez que c'est la langue parlée dans vos médiasen-AU, votre vocabulaire personnalisé n'est pas appliqué à votre transcription. Si vous incluez LanguageOptions et spécifiez en-US comme seul dialecte de langue anglaise, votre vocabulaire personnalisé est appliqué à votre transcription.
Pour des exemples LanguageIdSettingsdans une demande, reportez-vous à l'option 2 dans les panneaux AWS SDKsdéroulants AWS CLIet dans la Utilisation de l’identification des langues avec des transcriptions par lots section.
Utilisation de l’identification des langues avec des transcriptions par lots
Vous pouvez utiliser l'identification automatique de la langue dans une tâche de transcription par lots à l'aide du AWS Management ConsoleAWS CLI, ou AWS SDKs; consultez les exemples suivants :
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre.
-
Dans le volet Paramètres de la tâche, recherchez la section Paramètres de langue et sélectionnez Identification automatique des langues ou Identification automatique de plusieurs langues.
Vous pouvez sélectionner plusieurs options de langue (dans la liste déroulante Sélectionner les langues) si vous connaissez les langues présentes dans votre fichier audio. La sélection d’options de langue peut améliorer la précision, mais n’est pas obligatoire.
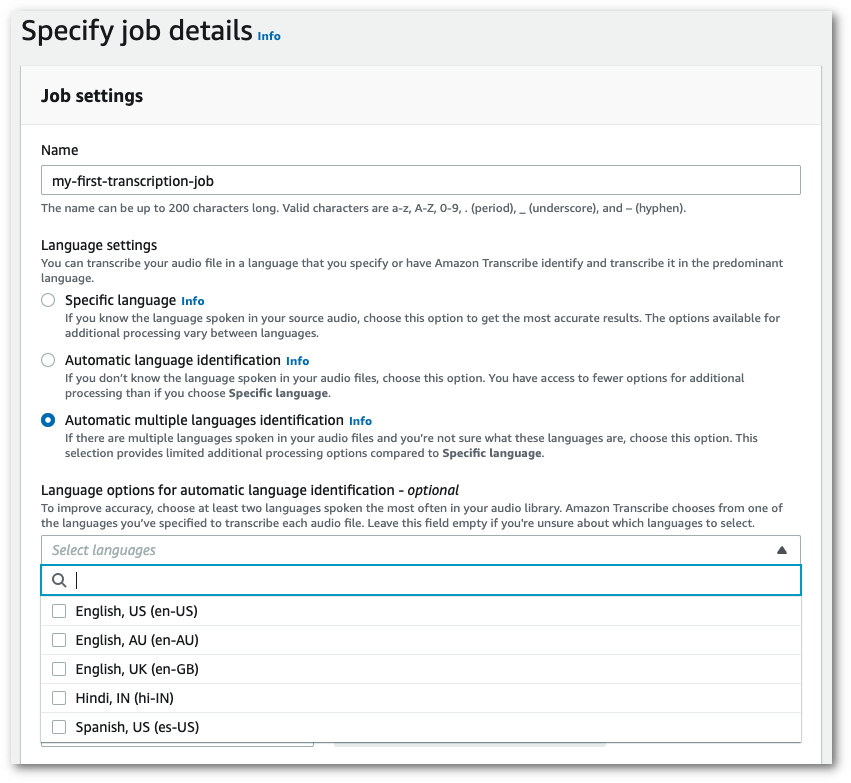
-
Renseignez les autres champs que vous souhaitez inclure sur la page Spécifier les détails de la tâche, puis sélectionnez Suivant. Vous accédez alors à la page Configurer la tâche - facultatif.
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre.
-
Dans le volet Paramètres de la tâche, recherchez la section Paramètres de langue et sélectionnez Identification automatique des langues ou Identification automatique de plusieurs langues.
Vous pouvez sélectionner plusieurs options de langue (dans la liste déroulante Sélectionner les langues) si vous connaissez les langues présentes dans votre fichier audio. La sélection d’options de langue peut améliorer la précision, mais n’est pas obligatoire.
-
Renseignez les autres champs que vous souhaitez inclure sur la page Spécifier les détails de la tâche, puis sélectionnez Suivant. Vous accédez alors à la page Configurer la tâche - facultatif.
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
Cet exemple utilise la start-transcription-jobIdentifyLanguage paramètre. Pour plus d’informations, consultez StartTranscriptionJob et LanguageIdSettings.
Option 1 : Sans le paramètre language-id-settings. Utilisez cette option si vous n’incluez pas de modèle de langue personnalisé, de vocabulaire personnalisé ou de filtre de vocabulaire personnalisé dans votre demande. language-options est facultative, mais recommandée.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
Option 2 : Avec le paramètre language-id-settings. Utilisez cette option si vous incluez un modèle de langue personnalisé, un vocabulaire personnalisé ou un filtre de vocabulaire personnalisé dans votre demande.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
Voici un autre exemple d'utilisation de la start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
Le fichier my-first-language-id-job.json contient le corps de requête suivant.
Option 1 : Sans le paramètre LanguageIdSettings. Utilisez cette option si vous n’incluez pas de modèle de langue personnalisé, de vocabulaire personnalisé ou de filtre de vocabulaire personnalisé dans votre demande. LanguageOptions est facultative, mais recommandée.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"IdentifyLanguage": true, (or "IdentifyMultipleLanguages": true),
"LanguageOptions": [
"en-US", "hi-IN"
]
}Option 2 : Avec le paramètre LanguageIdSettings. Utilisez cette option si vous incluez un modèle de langue personnalisé, un vocabulaire personnalisé ou un filtre de vocabulaire personnalisé dans votre demande.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"IdentifyLanguage": true, (or "IdentifyMultipleLanguages": true)
"LanguageOptions": [
"en-US", "hi-IN"
],
"LanguageIdSettings": {
"en-US" : {
"LanguageModelName": "my-en-US-language-model",
"VocabularyFilterName": "my-en-US-vocabulary-filter",
"VocabularyName": "my-en-US-vocabulary"
},
"hi-IN": {
"VocabularyName": "my-hi-IN-vocabulary",
"VocabularyFilterName": "my-hi-IN-vocabulary-filter"
}
}
}Cet exemple utilise le AWS SDK for Python (Boto3) pour identifier la langue de votre fichier à l'aide de l'IdentifyLanguageargument de la méthode start_transcription_jobStartTranscriptionJob et LanguageIdSettings.
Pour des exemples supplémentaires utilisant le AWS SDKs, notamment des exemples spécifiques aux fonctionnalités, des scénarios et des exemples multiservices, reportez-vous au chapitre. Exemples de code pour Amazon Transcribe à l'aide de AWS SDKs
Option 1 : Sans le paramètre LanguageIdSettings. Utilisez cette option si vous n’incluez pas de modèle de langue personnalisé, de vocabulaire personnalisé ou de filtre de vocabulaire personnalisé dans votre demande. LanguageOptions est facultative, mais recommandée.
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
MediaFormat = 'flac',
IdentifyLanguage = True, (or IdentifyMultipleLanguages = True),
LanguageOptions = [
'en-US', 'hi-IN'
]
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)Option 2 : Avec le paramètre LanguageIdSettings. Utilisez cette option si vous incluez un modèle de langue personnalisé, un vocabulaire personnalisé ou un filtre de vocabulaire personnalisé dans votre demande.
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
MediaFormat='flac',
IdentifyLanguage=True, (or IdentifyMultipleLanguages=True)
LanguageOptions = [
'en-US', 'hi-IN'
],
LanguageIdSettings={
'en-US': {
'VocabularyName': 'my-en-US-vocabulary',
'VocabularyFilterName': 'my-en-US-vocabulary-filter',
'LanguageModelName': 'my-en-US-language-model'
},
'hi-IN': {
'VocabularyName': 'my-hi-IN-vocabulary',
'VocabularyFilterName': 'my-hi-IN-vocabulary-filter'
}
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)