Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Amazon Transcribe prend en charge les sorties WebVTT (*.vtt) SubRip et (*.srt) pour les utiliser comme sous-titres vidéo. Vous pouvez sélectionner un ou les deux types de fichiers lors de la configuration de votre tâche de transcription vidéo par lots. Lorsque vous utilisez la fonctionnalité de sous-titrage, le ou les fichiers de sous-titres sélectionnés et un fichier de transcription normal (contenant des informations supplémentaires) sont produits. Les fichiers de sous-titres et de transcription sont envoyés vers la même destination.
Les sous-titres s’affichent en même temps que le texte est prononcé et restent visibles jusqu’à ce qu’il y ait une pause naturelle ou que le locuteur ait fini de parler. Notez que si vous activez les sous-titres dans votre demande de transcription et que votre audio ne contient pas de paroles, aucun fichier de sous-titres n’est créé.
Important
Amazon Transcribe utilise un indice de départ par défaut de 0 pour la sortie des sous-titres, qui diffère de la valeur la plus couramment utilisée de1. Si vous avez besoin d'un index de départ de1, vous pouvez le spécifier dans AWS Management Console ou dans votre demande d'API à l'aide du OutputStartIndexparamètre.
L’utilisation d’un indice de départ incorrect peut entraîner des erreurs de compatibilité avec d’autres services. Assurez-vous donc de vérifier l’indice de départ dont vous avez besoin avant de créer vos sous-titres. Si vous n’êtes pas certain de la valeur à utiliser, nous vous recommandons de choisir 1. Pour plus d’informations, consultez la section Subtitles.
Fonctionnalités prises en charge avec les sous-titres :
-
Expurgation de contenu – Tout contenu expurgé est indiqué comme «
PII» dans vos fichiers de sortie de sous-titres et de transcription normale. L’audio n’est pas modifié. -
Filtres de vocabulaire – Les fichiers de sous-titres sont générés à partir du fichier de transcription, de sorte que tous les mots que vous filtrez dans votre sortie de transcription standard sont également filtrés dans vos sous-titres. Le contenu filtré est affiché sous forme d’espaces blancs ou «
***» dans vos fichiers de transcription et de sous-titres. L’audio n’est pas modifié. -
Diarisation du locuteur – Si un segment de sous-titre donné contient plusieurs locuteurs, des tirets sont utilisés pour distinguer chaque locuteur. Cela s'applique à la fois au WebVTT SubRip et aux formats ; par exemple :
-- Texte prononcé par la personne 1
-- Texte prononcé par la personne 2
Les fichiers de sous-titres sont stockés au même Amazon S3 endroit que votre sortie de transcription.
Pour une présentation vidéo de la création de sous-titres, voir :
Génération de fichiers de sous-titres
Vous pouvez créer des fichiers de sous-titres à l'aide du AWS Management ConsoleAWS CLI, ou AWS SDKs; consultez les exemples suivants :
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre. Les options de sous-titres se trouvent dans le volet Données de sortie.
-
Sélectionnez les formats souhaités pour vos fichiers de sous-titres, puis choisissez une valeur pour votre indice de départ. Notez que la Amazon Transcribe valeur par défaut est
0, mais1qu'elle est plus largement utilisée. Si vous ne savez pas quelle valeur utiliser, nous vous recommandons de choisir1, car cela peut améliorer la compatibilité avec d’autres services.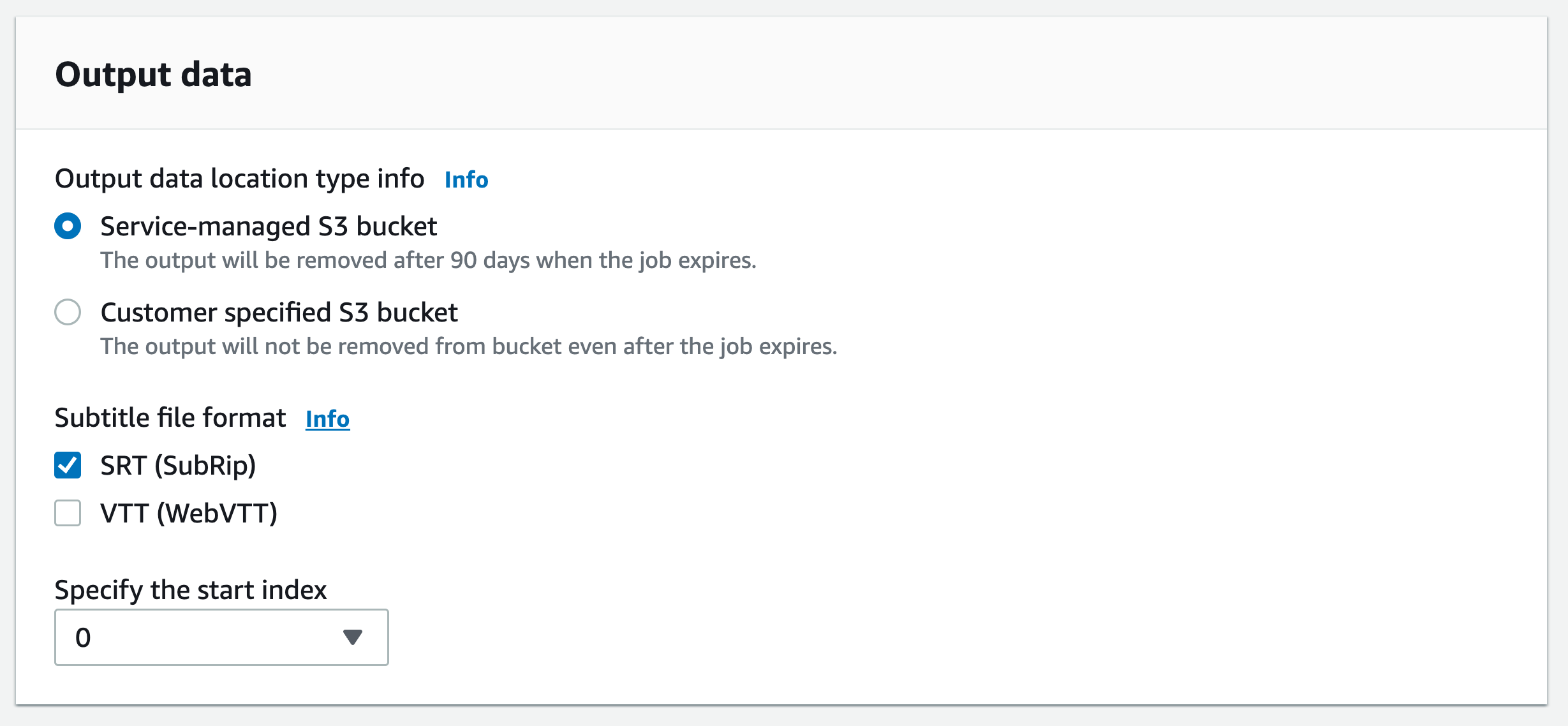
-
Renseignez les autres champs que vous souhaitez inclure sur la page Spécifier les détails de la tâche, puis sélectionnez Suivant. Vous accédez alors à la page Configurer la tâche - facultatif.
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre. Les options de sous-titres se trouvent dans le volet Données de sortie.
-
Sélectionnez les formats souhaités pour vos fichiers de sous-titres, puis choisissez une valeur pour votre indice de départ. Notez que la Amazon Transcribe valeur par défaut est
0, mais1qu'elle est plus largement utilisée. Si vous ne savez pas quelle valeur utiliser, nous vous recommandons de choisir1, car cela peut améliorer la compatibilité avec d’autres services.
-
Renseignez les autres champs que vous souhaitez inclure sur la page Spécifier les détails de la tâche, puis sélectionnez Suivant. Vous accédez alors à la page Configurer la tâche - facultatif.
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
Cet exemple utilise la start-transcription-jobSubtitles paramètre. Pour plus d’informations, consultez StartTranscriptionJob et Subtitles.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --subtitles Formats=vtt,srt,OutputStartIndex=1
Voici un autre exemple d'utilisation de la start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-subtitle-job.json
Le fichier my-first-subtitle-job.json contient le corps de requête suivant.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Subtitles": {
"Formats": [
"vtt","srt"
],
"OutputStartIndex": 1
}
}Cet exemple utilise le AWS SDK pour Python (Boto3) pour ajouter des sous-titres à l'aide de l'Subtitlesargument de la méthode start_transcription_jobStartTranscriptionJob et Subtitles.
Pour des exemples supplémentaires utilisant le AWS SDKs, notamment des exemples spécifiques aux fonctionnalités, des scénarios et des exemples multiservices, reportez-vous au chapitre. Exemples de code pour Amazon Transcribe à l'aide de AWS SDKs
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Subtitles = {
'Formats': [
'vtt','srt'
],
'OutputStartIndex': 1
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)