Amazon Forecast non è più disponibile per i nuovi clienti. I clienti esistenti di Amazon Forecast possono continuare a utilizzare il servizio normalmente. Scopri di più»
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Algoritmo DeepAR+
Amazon Forecast Deepar+ è un algoritmo di apprendimento supervisionato per la previsione di serie temporali scalari (unidimensionali) utilizzando reti neurali ricorrenti (). RNNs I metodi di previsione tradizionali, ad esempio il Modello autoregressivo integrato a media mobile (ARIMA) o il Livellamento esponenziale (ETS, Exponential Smoothing), associano un singolo modello a ogni serie temporale individuale, quindi utilizzano tale modello per estrapolare le serie temporali nel futuro. In molte applicazioni, tuttavia, sono presenti molte serie temporali simili in un set di unità trasversali. Questi raggruppamenti di serie temporali richiedono prodotti, carichi server e richieste diverse per le pagine Web. In questo caso, può essere utile eseguire il training di un singolo modello su tutte le serie temporali. DeepAR+adotta questo approccio. Quando il set di dati contiene centinaia di serie temporali delle caratteristiche, l'algoritmo DeepAR+ supera i metodi ARIMA ed ETS standard. Puoi inoltre utilizzare il modello addestrato per generare previsioni per nuove serie temporali che sono simili a quelle utilizzate per eseguire il training.
Quaderni in Python
Per una step-by-step guida sull'uso dell'algoritmo Deepar+, consulta Guida introduttiva a Deepar+
Funzionamento di DeepAR+
Durante il training, DeepAR+ utilizza un set di dati di training e un set di dati di test opzionale. Utilizza il set di dati di test per valutare il modello addestrato. In generale, i set di dati di training e di test non devono contenere lo stesso set di serie temporali. Puoi utilizzare un modello addestrato su un determinato set di addestramento per generare previsioni per il futuro della serie temporale nel set di addestramento e per altre serie temporali. Entrambi i set di dati di training e di test sono costituiti da serie temporali target (preferibilmente più di una). Facoltativamente, possono essere associati a un vettore di serie temporali di funzionalità e a un vettore di caratteristiche categoriali (per i dettagli, consulta DeepAR Input/Output Interface nella AI Developer Guide). SageMaker L'esempio seguente mostra il funzionamento per un elemento di un set di dati di training indicizzato da i. Il set di dati di training è costituito da una serie temporale target, zi,t, e due serie temporali delle caratteristiche associate, xi,1,t e xi,2,t.
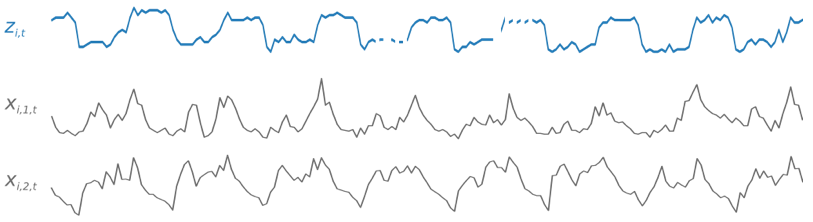
La serie temporale target potrebbe non contenere alcuni valori (indicati nei grafici da interruzioni nelle serie temporali). DeepAR+ supporta solo serie temporali delle caratteristiche che sono note in futuro. Questo consente di eseguire scenari ipotetici "what-if" controfattuali. Ad esempio, "Cosa accade se modifico il prezzo di un prodotto?"
Ogni serie temporale di target può anche essere associata a una serie di caratteristiche di categoria. che puoi utilizzare per codificare che una serie temporale appartiene a raggruppamenti specifici. L'uso di caratteristiche categoriche consente al modello di apprendere il comportamento tipico per tali raggruppamenti, che può aumentare la precisione. Questo viene implementato da un modello apprendendo un vettore di incorporamento per ciascun gruppo che acquisisce le proprietà comuni di tutte le serie temporali nel gruppo.
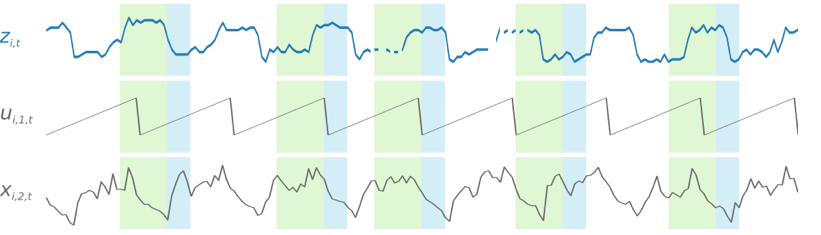
Per semplificare i modelli di apprendimento dipendenti dal tempo, ad esempio i picchi nei weekend, DeepAR+crea automaticamente serie temporali delle caratteristiche basate sulla granularità di serie temporali. Ad esempio, DeepAR+crea due serie temporali delle caratteristiche (giorno del mese e giorno dell'anno) a una frequenza serie temporale settimanale. e utilizza queste serie temporali delle caratteristiche derivate insieme alle serie temporali delle caratteristiche personalizzate fornite durante il training e l'inferenza. L'esempio seguente mostra due serie temporali delle caratteristiche derivate: ui,1,t rappresenta l'ora del giorno e ui,2,t il giorno della settimana.

DeepAR+ include automaticamente queste serie temporali delle caratteristiche in base alla frequenza dei dati e alle dimensioni dei dati di training. Nella tabella seguente vengono elencate le caratteristiche che possono essere derivate per ogni frequenza temporale di base supportata.
| Frequenza delle serie temporali | Caratteristiche derivate |
|---|---|
| Minuto | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| Ora | hour-of-day, day-of-week, day-of-month, day-of-year |
| Day (Giorno) | day-of-week, day-of-month, day-of-year |
| Settimana | week-of-month, week-of-year |
| Mese | month-of-year |
Il training del modello DeepAR+ viene eseguito campionando in maniera causale diversi esempi di training di ciascuna delle serie temporali nel set di dati di training. Ogni esempio di addestramento è costituito da una coppia di finestre di contesto e di previsione adiacenti con lunghezze predefinite fisse. L'iperparametro context_length controlla quanto indietro nel passato la rete è in grado di vedere e il parametro ForecastHorizon controlla quanto avanti nel futuro è possibile fare previsioni. Durante il training, Amazon Forecast ignora gli elementi nel set di dati di training con serie temporali più brevi della lunghezza di previsione specificata. L'esempio seguente mostra cinque campioni, con una lunghezza del contesto (evidenziata in verde) di 12 ore e una lunghezza di previsione (evidenziata in blu) di 6 ore, disegnati dall'elemento i. Per motivi di sintesi, abbiamo escluso le serie temporali delle caratteristiche xi,1,t e ui,2,t.
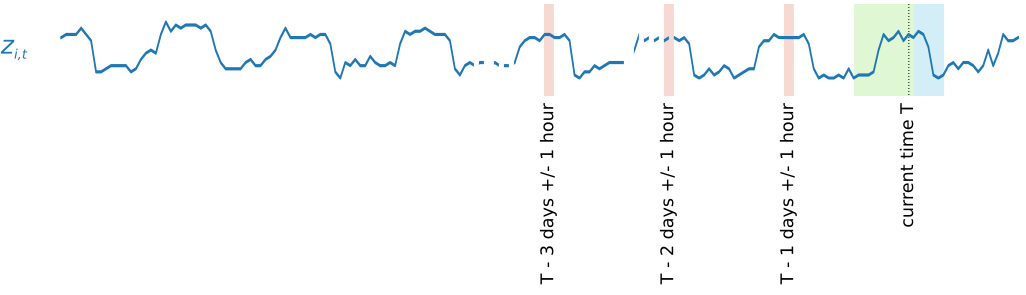
Per acquisire modelli di stagionalità, DeepAR+ immette inoltre automaticamente valori ritardati (periodo passato) di serie temporali di target. Nell'esempio di campioni acquisiti a una frequenza oraria, per ogni indice temporale t = T, il modello espone i valori zi,t, che si sono verificati circa uno, due e tre giorni nel passato (evidenziati in rosa).
Per inferenza, il modello addestrato accetta come input le serie temporali target, che possono o meno essere state utilizzate durante il training e prevede una distribuzione di probabilità per i valori ForecastHorizon successivi. Poiché DeepAR+ è addestrato sull'intero set di dati, la previsione tiene conto dei modelli appresi da serie temporali simili.
Per informazioni sulla matematica dietro DeepAR+, consulta DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
Iperparametri DeepAR+
Nella tabella seguente sono elencati gli iperparametri che puoi utilizzare nell'algoritmo DeepAR+. I parametri in grassetto partecipano all'ottimizzazione degli iperparametri (HPO).
| Nome parametro | Descrizione |
|---|---|
context_length |
Il numero di punti temporali letti dal modello prima di effettuare la previsione. Il valore di questo parametro deve essere più o meno lo stesso di
|
epochs |
Numero massimo di passaggi necessari per i dati di training. Il valore ottimale dipende dalle dimensioni dei dati e dalla velocità di apprendimento. I set di dati più piccoli e le velocità di apprendimento più basse richiedono entrambi più epoche per ottenere buoni risultati.
|
learning_rate |
Velocità di apprendimento utilizzata durante l’addestramento.
|
learning_rate_decay |
La velocità alla quale diminuisce l'apprendimento. Al massimo, la velocità di apprendimento viene ridotta di
|
likelihood |
Il modello genera una previsione probabilistica e può fornire quantili della distribuzione e restituire campioni. A seconda dei dati, scegli una probabilità appropriata (modello di rumore) utilizzata per le stime di incertezza. Valori validi
|
max_learning_rate_decays |
Il numero massimo di riduzioni della velocità di apprendimento che devono verificarsi.
|
num_averaged_models |
In DeepAR +, un percorso di training può incontrare più modelli. Ogni modello potrebbe avere punti di forza e di debolezza di previsione diversi. DeepAR+ può eseguire la media dei comportamenti del modello per sfruttare i punti di forza di tutti i modelli.
|
num_cells |
Numero di celle da utilizzare in ciascun livello nascosto delle reti neurali ricorrenti (RNN).
|
num_layers |
Numero di livelli nascosti nelle reti neurali ricorrenti (RNN).
|
Ottimizzazione dei modelli DeepAR+
Per ottimizzare modelli DeepAR+ di Amazon Forecast, segui questi suggerimenti per ottimizzare il processo di training e la configurazione hardware.
Best practice per l'ottimizzazione del processo
Per ottenere risultati ottimali, seguire questi suggerimenti:
-
Tranne quando si suddividono i set di dati di training e di test, fornire sempre serie temporali complete per il training e il test e quando si chiama il modello per inferenza. A prescindere da come si imposta
context_length, non dividere la serie temporale né fornirne solo una parte. Il modello utilizzerà punti dati ancora più vecchi dicontext_lengthper la caratteristica valori ritardati. -
Per l'ottimizzazione del modello, puoi suddividere il set di dati in set di dati di training e di test. In uno scenario di valutazione tipico, è opportuno testare il modello sulla stessa serie temporale utilizzata nel training, ma sui punti temporali
ForecastHorizonfuturi immediatamente dopo l'ultimo punto temporale visibile durante il training. Per creare set di dati di training e di test che soddisfano questi criteri, utilizza l'intero set di dati (tutta la serie temporale) come un set di dati di test e rimuovi gli ultimi puntiForecastHorizonda ciascuna serie temporale per il training. In questo modo, durante il training, il modello non vede i valori target per punti temporali su cui viene valutato durante il test. Nella fase di test, gli ultimi puntiForecastHorizondi ciascuna serie temporale nel set di dati di test vengono trattenuti e viene generata una previsione. La previsione viene quindi confrontata con i valori effettivi degli ultimi puntiForecastHorizon. Puoi creare valutazioni più complesse ripetendo serie temporali più volte nel set di dati di test, ma tagliandoli in corrispondenza di endpoint diversi. Questo produce parametri di precisione che vengono mediati su più previsioni da diversi punti temporali. -
Evitare l'uso di valori molto grandi (> 400) per
ForecastHorizonperché questo rallenta il modello e lo rende meno preciso. Se si desidera prevedere più avanti nel futuro, valutare se eseguire l'aggregazione a una frequenza più elevata. Ad esempio, utilizza5minanziché1min. -
A causa dei ritardi, il modello può guardare più indietro di
context_length. Pertanto, non è necessario impostare questo parametro su un valore elevato. Un buon punto di partenza per questo parametro è lo stesso valore diForecastHorizon. -
Eseguire il training di modelli DeepAR+ con tutte le serie temporali disponibili. Anche se un modello DeepAR+ addestrato su una singola serie temporale potrebbe già andare bene, i modelli di previsione standard come ARIMA o ETS potrebbero essere più precisi e più mirati a questo caso d'uso. DeepAR+ inizia a superare i metodi standard quando il set di dati contiene centinaia di serie temporali delle caratteristiche. Al momento, DeepAR+ richiede che il numero totale di osservazioni disponibili, tra tutte le serie temporali di training, sia di almeno 300.
