Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Risoluzione dei problemi relativi alle configurazioni in Lambda
Le impostazioni di configurazione delle funzioni possono avere un impatto sulle prestazioni e sul comportamento complessivi della funzione Lambda. Queste potrebbero non causare errori di funzionamento effettivi, ma possono causare timeout e risultati imprevisti.
Negli argomenti seguenti vengono forniti suggerimenti per la risoluzione dei problemi relativi a problemi comuni che potrebbero verificarsi relativi alle impostazioni di configurazione delle funzioni Lambda.
Argomenti
Configurazioni della memoria
È possibile configurare una funzione Lambda per utilizzare quantità compresa tra 128 MB e 10.240 MB. Per impostazione predefinita, a qualsiasi funzione creata nella console viene assegnata la quantità di memoria minima. Molte funzioni Lambda offrono prestazioni ottimali con questa impostazione minima. Tuttavia, se si importano librerie di codici di grandi dimensioni o si completano attività che richiedono molta memoria, 128 MB non sono sufficienti.
Se le funzioni funzionano molto più lentamente del previsto, il primo passaggio consiste nell'aumentare l'impostazione della memoria. Per le funzioni collegate alla memoria, ciò risolve il collo di bottiglia e può migliorare le prestazioni della tua funzione.
Configurazioni collegate alla CPU
Per le operazioni a elaborazione intensiva, se le prestazioni della funzione Lambda sono più lente del previsto, ciò potrebbe essere dovuto al fatto che la funzione è vincolata alla CPU. In questo caso, la capacità di calcolo della funzione non può tenere il passo con il lavoro.
Sebbene Lambda non consenta di modificare direttamente la configurazione della CPU, la CPU viene controllata indirettamente tramite le impostazioni della memoria. Il servizio Lambda alloca proporzionalmente più CPU virtuale man mano che si alloca più memoria. Con 1,8 GB di memoria, una funzione Lambda ha un'intera vCPU allocata e, al di sopra di questo livello, ha accesso a più di un core vCPU. Con 10.240 MB, ha 6 vCPU disponibili. In questi casi, è possibile migliorare le prestazioni aumentando l'allocazione di memoria, anche se la funzione non utilizza tutta la memoria.
Timeout
I timeout per le funzioni Lambda possono essere impostati tra 1 e 900 secondi (15 minuti). Per impostazione predefinita, la console Lambda imposta questo valore su 3 secondi. Il valore di timeout è una valvola di sicurezza che garantisce che le funzioni non funzionino all'infinito. Una volta raggiunto il valore di timeout, Lambda interrompe la chiamata della funzione.
Se un valore di timeout viene impostato vicino alla durata media di una funzione, aumenta il rischio che la funzione scada inaspettatamente. La durata di una funzione può variare in base alla quantità di trasferimento ed elaborazione dei dati e alla latenza dei servizi con cui interagisce la funzione. Alcune cause comuni di timeout includono:
-
Quando si scaricano dati da bucket S3 o altri archivi di dati, il download è più grande o richiede più tempo della media.
-
Una funzione invia una richiesta a un altro servizio, che impiega più tempo a rispondere.
-
I parametri forniti a una funzione richiedono una maggiore complessità computazionale della funzione, il che fa sì che l'invocazione richieda più tempo.
Nel testare l'applicazione, assicurati che i test riflettano accuratamente la dimensione e la quantità di dati e valori realistici dei parametri. È importante sottolineare che utilizza set di dati al limite massimo di quanto ragionevolmente previsto per il carico di lavoro.
Laddove possibile, implementa limiti massimi nel tuo carico di lavoro. In questo esempio, l'applicazione potrebbe utilizzare un limite di dimensione massima per ogni tipo di file. È quindi possibile testare le prestazioni dell'applicazione per una gamma di dimensioni di file previste, fino ai limiti massimi inclusi.
Perdita di memoria tra invocazioni
Le variabili e gli oggetti globali memorizzati nella fase INIT di una invocazione Lambda mantengono il loro stato tra le invocazioni a caldo. Vengono ripristinate completamente solo quando l'ambiente di esecuzione viene eseguito per la prima volta (noto anche come "avvio a freddo"). Tutte le variabili memorizzate nell'handler vengono distrutte quando l'handler viene terminato. È consigliabile utilizzare la fase INIT per configurare connessioni al database, caricare librerie, creare cache e caricare risorse immutabili.
Quando utilizzi librerie di terze parti per più invocazioni nello stesso ambiente di esecuzione, assicurati di consultare la relativa documentazione per l'utilizzo in un ambiente di elaborazione serverless. Alcune librerie di connessione e registrazione al database possono salvare risultati di invocazione intermedi e altri dati. Ciò fa sì che l'utilizzo della memoria di queste librerie aumenti con le successive invocazioni a caldo. Nei casi in cui la memoria cresce rapidamente, è possibile che la funzione Lambda esaurisca la memoria, anche se il codice personalizzato elimina le variabili correttamente.
Questo problema riguarda le invocazioni che si verificano in ambienti di esecuzione a caldo. Ad esempio, il seguente codice crea una perdita di memoria tra le invocazioni. La funzione Lambda consuma memoria aggiuntiva ad ogni invocazione aumentando le dimensioni di un array globale:
let a = []
exports.handler = async (event) => {
a.push(Array(100000).fill(1))
}
Configurata con 128 MB di memoria, dopo aver richiamato questa funzione 1.000 volte, la scheda Monitoraggio della funzione Lambda mostra le tipiche modifiche nelle invocazioni, nella durata e nel conteggio degli errori quando si verifica una perdita di memoria:

-
Invocazioni: un tasso di transazione costante viene interrotto periodicamente man mano che le invocazioni impiegano più tempo per essere completate. Durante lo stato stazionario, la perdita di memoria non consuma tutta la memoria allocata alla funzione. Man mano che le prestazioni peggiorano, il sistema operativo utilizza la memoria locale per adattarla alla crescente quantità di memoria richiesta dalla funzione, il che comporta un minor numero di transazioni completate.
-
Durata: prima che la funzione esaurisca la memoria, termina le invocazioni a una velocità costante di due millisecondi. Man mano che si verifica la paginazione, la durata aumenta di un ordine di grandezza.
-
Numero di errori: quando la perdita di memoria supera la memoria allocata, alla fine la funzione subisce errori dovuti al superamento del timeout di calcolo o l'ambiente di esecuzione arresta la funzione.
Dopo l'errore, il servizio Lambda riavvia l'ambiente di esecuzione, il che spiega perché in tutti e tre i grafici i parametri tornano allo stato originale. L'espansione dei parametri di CloudWatch per la durata fornisce maggiori dettagli per le statistiche sulla durata minima, massima e media:

Per trovare gli errori generati nelle 1.000 invocazioni, puoi utilizzare il linguaggio di query di CloudWatch Insights. La seguente query esclude i log informativi per riportare solo gli errori:
fields @timestamp, @message | sort @timestamp desc | filter @message not like 'EXTENSION' | filter @message not like 'Lambda Insights' | filter @message not like 'INFO' | filter @message not like 'REPORT' | filter @message not like 'END' | filter @message not like 'START'
Se eseguita sul gruppo di log per questa funzione, ciò dimostra che i timeout erano responsabili degli errori periodici:

Risultati asincroni restituiti a una invocazione successiva
Per il codice di funzione che utilizza modelli asincroni, è possibile che i risultati di callback di una invocazione vengano restituiti in una invocazione futura. Questo esempio utilizza Node.js ma la stessa logica può essere applicata ad altri runtime utilizzando modelli asincroni. La funzione utilizza la tradizionale sintassi di callback in JavaScript. Richiama una funzione asincrona con un contatore incrementale che tiene traccia del numero di invocazioni:
let seqId = 0 exports.handler = async (event, context) => { console.log(`Starting: sequence Id=${++seqId}`) doWork(seqId, function(id) { console.log(`Work done: sequence Id=${id}`) }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
Quando vengono richiamati più volte in successione, i risultati dei callback si verificano nelle invocazioni successive:

-
Il codice richiama la funzione doWork, fornendo una funzione di callback come ultimo parametro.
-
Il completamento della funzione doWork richiede un certo periodo di tempo prima di richiamare il callback.
-
La registrazione della funzione indica che la chiamata termina prima che la funzione DoWork termini l'esecuzione. Inoltre, dopo l'avvio di un'iterazione, vengono elaborati i callback delle iterazioni precedenti, come mostrato nei log.
In JavaScript, i callback asincroni vengono gestiti con un ciclo di eventi
Ciò crea la possibilità che i dati privati di una invocazione precedente vengano visualizzati in una invocazione successiva. Esistono due modi per prevenire o rilevare questo comportamento. Innanzitutto, JavaScript fornisce le parole chiave async e await
let seqId = 0 exports.handler = async (event) => { console.log(`Starting: sequence Id=${++seqId}`) const result = await doWork(seqId) console.log(`Work done: sequence Id=${result}`) } function doWork(id) { return new Promise(resolve => { setTimeout(() => resolve(id), 4000) }) }
L'utilizzo di questa sintassi impedisce all'handler di uscire prima che la funzione asincrona sia terminata. In questo caso, se il callback impiega più tempo del timeout della funzione Lambda, la funzione genererà un errore invece di restituire il risultato del callback in una invocazione successiva:

-
Il codice richiama la funzione doWork asincrona utilizzando la parola chiave await nell'handler.
-
Il completamento della funzione doWork richiede un certo periodo di tempo prima di risolvere la promessa.
-
La funzione scade perché doWork impiega più tempo del limite di timeout consentito e il risultato del callback non viene restituito in una invocazione successiva.
Di solito, è necessario accertarsi che tutti i processi in background e le callback nel codice vengano completate prima che il codice sia terminato. Se ciò non è possibile nel tuo caso d'uso, puoi utilizzare un identificatore per assicurarti che il callback appartenga all'invocazione corrente. A tale scopo, è possibile utilizzare l'awsRequestId fornito dall'oggetto del contesto. Passando questo valore al callback asincrono, è possibile confrontare il valore passato con il valore corrente per rilevare se il callback ha avuto origine da un'altra invocazione:
let currentContext exports.handler = async (event, context) => { console.log(`Starting: request id=$\{context.awsRequestId}`) currentContext = context doWork(context.awsRequestId, function(id) { if (id != currentContext.awsRequestId) { console.info(`This callback is from another invocation.`) } }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
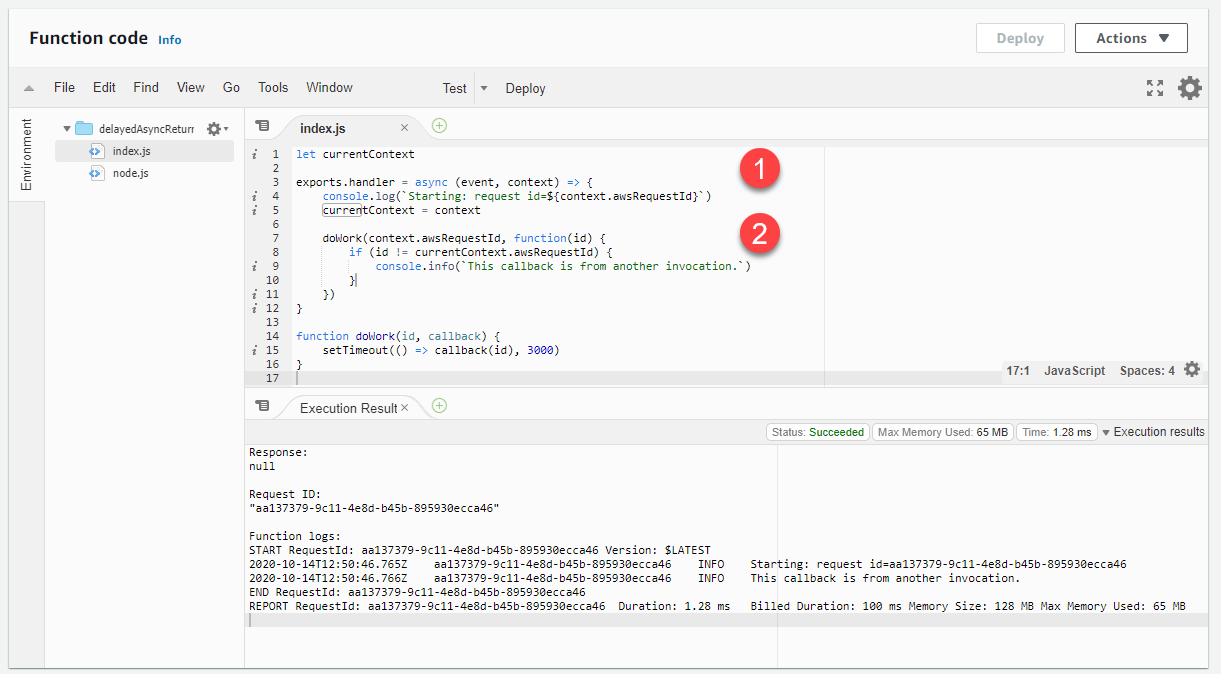
-
L'handler della funzione Lambda accetta il parametro context, che fornisce l'accesso a un ID di richiesta di invocazione univoco.
-
awsRequestId viene passato alla funzione doWork. Nel callback, l'ID viene confrontato con l'awsRequestId dell'invocazione corrente. Se questi valori sono diversi, il codice può agire di conseguenza.
