Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creare un'app di elaborazione file serverless
Uno dei casi d'uso più comuni di Lambda è l'esecuzione di attività di elaborazione dei file. Ad esempio, è possibile utilizzare una funzione Lambda per creare automaticamente file PDF da file o immagini HTML o per creare miniature quando un utente carica un'immagine.
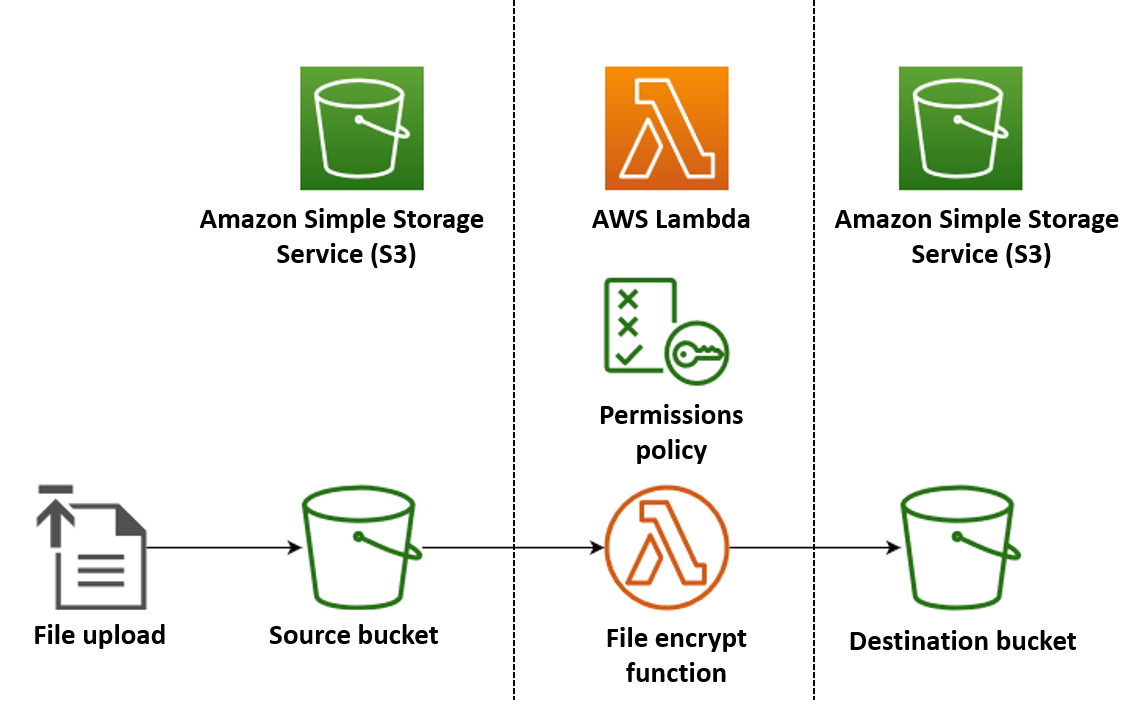
In questo esempio, viene creata un'app che crittografa automaticamente i file PDF quando vengono caricati in un bucket Amazon Simple Storage Service (Amazon S3). Per creare questa app, crea le risorse seguenti:
-
Un bucket S3 in cui gli utenti possono caricare i file PDF
-
Una funzione Lambda in Python che legge il file caricato e ne crea una versione crittografata e protetta da password
-
Un secondo bucket S3 per Lambda in cui salvare il file crittografato
È inoltre possibile creare una policy AWS Identity and Access Management (IAM) per consentire alla funzione Lambda di eseguire operazioni di lettura e scrittura sui bucket S3.
Suggerimento
Se non conosci Lambda, ti consigliamo di iniziare con il tutorial Crea la tua prima funzione Lambda prima di creare questa app di esempio.
Puoi distribuire l'app manualmente creando e configurando risorse con Console di gestione AWS o il AWS Command Line Interface ().AWS CLI Puoi anche distribuire l'app utilizzando (). AWS Serverless Application Model AWS SAM AWS SAM è uno strumento Infrastructure as Code (IaC). Con IaC, non vengono create risorse manualmente, ma le si definisce in codice e poi le si distribuisce automaticamente.
Se desideri saperne di più sull'utilizzo di Lambda con IaC prima di implementare questa app di esempio, consulta Utilizzo di Lambda con l'infrastructure as code (IaC).
Creare i file del codice sorgente della funzione Lambda
Crea i seguenti file nella directory del tuo progetto:
-
lambda_function.py: il codice della funzione Python per la funzione Lambda che esegue la crittografia del database -
requirements.txt: un file manifesto che definisce le dipendenze richieste dal codice della funzione Python
Espandi le seguenti sezioni per visualizzare il codice e per saperne di più sul ruolo di ogni file. Per creare i file sul tuo computer locale, copia e incolla il codice seguente o scarica i file dal repository GitHub aws-lambda-developer-guide
Copia e incolla il codice seguente in un nuovo file lambda_function.py.
from pypdf import PdfReader, PdfWriter import uuid import os from urllib.parse import unquote_plus import boto3 # Create the S3 client to download and upload objects from S3 s3_client = boto3.client('s3') def lambda_handler(event, context): # Iterate over the S3 event object and get the key for all uploaded files for record in event['Records']: bucket = record['s3']['bucket']['name'] key = unquote_plus(record['s3']['object']['key']) # Decode the S3 object key to remove any URL-encoded characters download_path = f'/tmp/{uuid.uuid4()}.pdf' # Create a path in the Lambda tmp directory to save the file to upload_path = f'/tmp/converted-{uuid.uuid4()}.pdf' # Create another path to save the encrypted file to # If the file is a PDF, encrypt it and upload it to the destination S3 bucket if key.lower().endswith('.pdf'): s3_client.download_file(bucket, key, download_path) encrypt_pdf(download_path, upload_path) encrypted_key = add_encrypted_suffix(key) s3_client.upload_file(upload_path, f'{bucket}-encrypted', encrypted_key) # Define the function to encrypt the PDF file with a password def encrypt_pdf(file_path, encrypted_file_path): reader = PdfReader(file_path) writer = PdfWriter() for page in reader.pages: writer.add_page(page) # Add a password to the new PDF writer.encrypt("my-secret-password") # Save the new PDF to a file with open(encrypted_file_path, "wb") as file: writer.write(file) # Define a function to add a suffix to the original filename after encryption def add_encrypted_suffix(original_key): filename, extension = original_key.rsplit('.', 1) return f'{filename}_encrypted.{extension}'
Nota
In questo codice di esempio, una password per il file crittografato (my-secret-password) è inserita nel codice della funzione. In un'applicazione di produzione, non includere informazioni sensibili come le password nel codice funzione. Invece, crea un AWS Secrets Manager segreto e poi usa l'estensione Lambda AWS Parameters and Secrets per recuperare le credenziali nella funzione Lambda.
Il codice della funzione python contiene tre funzioni: la funzione handler che Lambda esegue quando la funzione viene richiamata e due funzioni separate denominate add_encrypted_suffix e encrypt_pdf che l'handler chiama per eseguire la crittografia del PDF.
Quando la funzione viene richiamata da Amazon S3, Lambda passa un argomento di evento in formato JSON alla funzione che contiene dettagli sull'evento che ha causato l'invocazione. In questo caso, le informazioni includono il nome del bucket S3 e le chiavi oggetto per i file caricati. Per maggiori informazioni sul formato dell'oggetto evento per Amazon S3, consulta Elaborare le notifiche di eventi Amazon S3 con Lambda.
La funzione utilizza quindi il AWS SDK per Python (Boto3) per scaricare i file PDF specificati nell'oggetto evento nella relativa directory di archiviazione temporanea locale, prima di crittografarli utilizzando la libreria. pypdf
Infine, la funzione utilizza l'SDK Boto3 per archiviare il file crittografato nel bucket di destinazione S3.
Copia e incolla il codice seguente in un nuovo file requirements.txt.
boto3 pypdf
Per questo esempio, il codice della funzione ha solo due dipendenze che non fanno parte della libreria Python standard: l'SDK per Python (Boto3) e il pacchetto pypdf utilizzato dalla funzione per eseguire la crittografia PDF.
Nota
Una versione dell'SDK for Python (Boto3) è inclusa come parte del runtime Lambda, quindi il codice può essere eseguito senza aggiungere Boto3 al pacchetto di implementazione della funzione. Tuttavia, per mantenere il pieno controllo delle tue dipendenze ed evitare possibili problemi di disallineamento della versione, la best practice per Python è includere tutte le dipendenze della funzione nel pacchetto di implementazione della tua funzione. Per ulteriori informazioni, consulta Dipendenze di runtime in Python.
Distribuisci l'app
È possibile creare e distribuire le risorse per questa app di esempio manualmente o utilizzando. AWS SAM In un ambiente di produzione, si consiglia di utilizzare uno strumento IaC come quello AWS SAM per distribuire in modo rapido e ripetibile intere applicazioni serverless senza utilizzare processi manuali.
Per distribuire l'app manualmente:
-
Creare bucket Amazon S3 di origine e di destinazione
-
Creare una funzione Lambda che crittografa un file PDF e salva la versione crittografata in un bucket S3
-
Configurare un trigger Lambda che richiama la tua funzione quando gli oggetti vengono caricati nel bucket di origine
Prima di iniziare, assicurati che Python
Creare due bucket S3
Per prima cosa, crea due bucket S3. Il primo bucket è il bucket di origine in cui caricherai i tuoi file PDF. Il secondo bucket è utilizzato da Lambda per salvare il file crittografato quando richiami la tua funzione.
Creazione di un ruolo di esecuzione
Un ruolo di esecuzione è un ruolo IAM che concede a una funzione Lambda l'autorizzazione all' Servizi AWS accesso e alle risorse. Per concedere alla funzione l'accesso in lettura e scrittura ad Amazon S3, è necessario collegare la policy gestita da AWS AmazonS3FullAccess.
Creazione del pacchetto di implementazione della funzione
Per creare la funzione, occorre creare un pacchetto di implementazione contenente la funzione e le rispettive dipendenze. Per questa applicazione, il codice della funzione utilizza una libreria separata per la crittografia dei PDF.
Per creare il pacchetto di implementazione
-
Passa alla directory del progetto contenente i
requirements.txtfilelambda_function.pye che hai creato o scaricato in GitHub precedenza e crea una nuova directory denominata.package -
Installa le dipendenze specificate nel file
requirements.txtnella tua directorypackageeseguendo il comando seguente.pip install -r requirements.txt --target ./package/ -
Crea un file .zip contenente il codice dell'applicazione e le relative dipendenze. Su Linux o MacOS, esegui i comandi riportati di seguito dall'interfaccia della linea di comando.
cd package zip -r ../lambda_function.zip . cd .. zip lambda_function.zip lambda_function.pySu Windows, usa il tuo strumento di compressione preferito per creare il file
lambda_function.zip. Assicurati che il tuo filelambda_function.pye le cartelle contenenti le tue dipendenze si trovino tutti nella directory principale del file .zip.
Puoi creare il tuo pacchetto di implementazione anche utilizzando un ambiente virtuale Python. Per informazioni, consultare Utilizzo di archivi di file .zip per le funzioni Lambda in Python.
Creazione della funzione Lambda
Ora usi il pacchetto di implementazione creato nel passaggio precedente per implementare la tua funzione Lambda.
Configurare un trigger Amazon S3 per richiamare la funzione
Affinché la funzione Lambda venga eseguita quando carichi un file nel bucket di origine, devi configurare un trigger per la funzione. È possibile configurare il trigger Amazon S3 utilizzando la console Lambda o la AWS CLI.
Importante
Questa procedura configura il bucket S3 per richiamare la funzione ogni volta che un oggetto viene creato nel bucket. Assicurati di configurare questa opzione solo sul bucket di origine. Se la tua funzione Lambda crea oggetti nello stesso bucket che la richiama, la tua funzione può essere richiamata continuamente in un ciclo ricorsivo (loop)
Prima di iniziare, assicurati che Docker
-
Nella directory del progetto, copia e incolla il seguente codice in un file denominato
template.yaml. Sostituisci i nomi dei bucket segnaposto:-
Per il bucket di destinazione, sostituisci
amzn-s3-demo-bucket-encryptedcon<source-bucket-name>-encrypted, dove<source-bucket>è il nome che hai scelto per il bucket di origine.
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: EncryptPDFFunction: Type: AWS::Serverless::Function Properties: FunctionName: EncryptPDF Architectures: [x86_64] CodeUri: ./ Handler: lambda_function.lambda_handler Runtime: python3.12 Timeout: 15 MemorySize: 256 LoggingConfig: LogFormat: JSON Policies: - AmazonS3FullAccess Events: S3Event: Type: S3 Properties: Bucket: !Ref PDFSourceBucket Events: s3:ObjectCreated:* PDFSourceBucket: Type: AWS::S3::Bucket Properties: BucketName:amzn-s3-demo-bucketEncryptedPDFBucket: Type: AWS::S3::Bucket Properties: BucketName:amzn-s3-demo-bucket-encryptedIl AWS SAM modello definisce le risorse che crei per la tua app. In questo esempio, il modello definisce una funzione Lambda utilizzando il tipo
AWS::Serverless::Functione due bucket S3 che utilizzano il tipoAWS::S3::Bucket. I nomi dei bucket specificati nel modello sono segnaposti. Prima di distribuire l'app utilizzando AWS SAM, devi modificare il modello per rinominare i bucket con nomi univoci globali che soddisfino le regole di denominazione dei bucket S3. Questo passaggio viene spiegato ulteriormente in Distribuisci le risorse utilizzando AWS SAM.La definizione della risorsa della funzione Lambda configura un trigger per la funzione utilizzando la proprietà dell'evento
S3Event. Questo trigger fa sì che la funzione venga richiamata ogni volta che viene creato un oggetto nel bucket di origine.La definizione della funzione specifica anche una policy AWS Identity and Access Management (IAM) da allegare al ruolo di esecuzione della funzione. La policy gestita da AWS
AmazonS3FullAccessfornisce alla tua funzione le autorizzazioni necessarie per leggere e scrivere oggetti su Amazon S3. -
Eseguire il comando seguente nella directory in cui sono stati salvati i file
template.yaml,lambda_function.pyerequirements.txt.sam build --use-containerQuesto comando raccoglie gli artefatti di compilazione per l'applicazione e li colloca nel formato e nella posizione corretti per l'implementazione. Specificando l'
--use-containeropzione si crea la funzione all'interno di un Lambda-like contenitore Docker. Lo usiamo qui quindi non è necessario che Python 3.12 sia installato sul computer locale per far funzionare la build.Durante il processo di compilazione, AWS SAM cerca il codice della funzione Lambda nella posizione specificata con la
CodeUriproprietà nel modello. In questo caso, abbiamo specificato la directory corrente come posizione (./).Se è presente un
requirements.txtfile, lo AWS SAM usa per raccogliere le dipendenze specificate. Per impostazione predefinita, AWS SAM crea un pacchetto di distribuzione.zip con il codice della funzione e le dipendenze. Puoi anche scegliere di distribuire la tua funzione come immagine contenitore utilizzando la proprietà. PackageType -
Per distribuire l'applicazione e creare le risorse Lambda e Amazon S3 specificate nel modello, AWS SAM esegui il comando seguente.
sam deploy --guidedL'uso del
--guidedflag significa che ti AWS SAM verranno mostrate le istruzioni per guidarti attraverso il processo di distribuzione. Per questa implementazione, accetta le opzioni predefinite premendo Invio.
Durante il processo di distribuzione, AWS SAM crea le seguenti risorse nel tuo: Account AWS
-
Una CloudFormation pila denominata
sam-app -
Una funzione Lambda con il nome
EncryptPDF -
Due bucket S3 con i nomi che hai scelto quando hai modificato il file modello
template.yamlAWS SAM -
Un ruolo di esecuzione IAM per la tua funzione con il formato del nome
sam-app-EncryptPDFFunctionRole-2qGaapHFWOQ8
Al AWS SAM termine della creazione delle risorse, dovresti visualizzare il seguente messaggio:
Successfully created/updated stack - sam-app in us-east-2Esecuzione del test dell'app
Per testare l'app, carica un file PDF nel bucket di origine e conferma che Lambda crei una versione crittografata del file nel bucket di destinazione. In questo esempio, puoi testarlo manualmente utilizzando la console o il AWS CLI, oppure utilizzando lo script di test fornito.
Per le applicazioni di produzione, puoi utilizzare metodi e tecniche di test tradizionali, come il test di unità, per confermare il corretto funzionamento del codice di funzione Lambda. La best practice consiste anche nell'eseguire test come quelli dello script di test fornito, che eseguono test di integrazione con risorse reali basate sul cloud. I test di integrazione nel cloud confermano che l'infrastruttura è stata implementata correttamente e che gli eventi fluiscono tra i diversi servizi come previsto. Per ulteriori informazioni, consulta Come eseguire test di funzioni e applicazioni serverless.
Puoi testare la tua funzione manualmente aggiungendo un file PDF al bucket di origine Amazon S3. Quando aggiungi un file al bucket di origine, la tua funzione Lambda dovrebbe essere richiamata automaticamente e dovrebbe memorizzare una versione crittografata del file nel bucket di destinazione.
Crea i seguenti file nella directory del tuo progetto:
-
test_pdf_encrypt.py: uno script di test che puoi utilizzare per testare automaticamente l'applicazione -
pytest.ini: un file di configurazione per lo script di test
Espandi le seguenti sezioni per visualizzare il codice e per saperne di più sul ruolo di ogni file.
Copia e incolla il codice seguente in un nuovo file test_pdf_encrypt.py. Assicurati di sostituire i nomi dei bucket segnaposto:
-
Nella funzione
test_source_bucket_available, sostituisciamzn-s3-demo-bucketcon il nome del tuo bucket di origine. -
Nella funzione
test_encrypted_file_in_bucket, sostituisciamzn-s3-demo-bucket-encryptedconsource-bucket-encrypted, dovesource-bucket>è il nome del tuo bucket di origine. -
Nella
cleanupfunzione, sostituisciamzn-s3-demo-bucketcon il nome del bucket di origine e sostituisciamzn-s3-demo-bucket-encryptedcon il nome del bucket di destinazione.
import boto3 import json import pytest import time import os @pytest.fixture def lambda_client(): return boto3.client('lambda') @pytest.fixture def s3_client(): return boto3.client('s3') @pytest.fixture def logs_client(): return boto3.client('logs') @pytest.fixture(scope='session') def cleanup(): # Create a new S3 client for cleanup s3_client = boto3.client('s3') yield # Cleanup code will be executed after all tests have finished # Delete test.pdf from the source bucket source_bucket = 'amzn-s3-demo-bucket' source_file_key = 'test.pdf' s3_client.delete_object(Bucket=source_bucket, Key=source_file_key) print(f"\nDeleted {source_file_key} from {source_bucket}") # Delete test_encrypted.pdf from the destination bucket destination_bucket = 'amzn-s3-demo-bucket-encrypted' destination_file_key = 'test_encrypted.pdf' s3_client.delete_object(Bucket=destination_bucket, Key=destination_file_key) print(f"Deleted {destination_file_key} from {destination_bucket}") @pytest.mark.order(1) def test_source_bucket_available(s3_client): s3_bucket_name = 'amzn-s3-demo-bucket' file_name = 'test.pdf' file_path = os.path.join(os.path.dirname(__file__), file_name) file_uploaded = False try: s3_client.upload_file(file_path, s3_bucket_name, file_name) file_uploaded = True except: print("Error: couldn't upload file") assert file_uploaded, "Could not upload file to S3 bucket" @pytest.mark.order(2) def test_lambda_invoked(logs_client): # Wait for a few seconds to make sure the logs are available time.sleep(5) # Get the latest log stream for the specified log group log_streams = logs_client.describe_log_streams( logGroupName='/aws/lambda/EncryptPDF', orderBy='LastEventTime', descending=True, limit=1 ) latest_log_stream_name = log_streams['logStreams'][0]['logStreamName'] # Retrieve the log events from the latest log stream log_events = logs_client.get_log_events( logGroupName='/aws/lambda/EncryptPDF', logStreamName=latest_log_stream_name ) success_found = False for event in log_events['events']: message = json.loads(event['message']) status = message.get('record', {}).get('status') if status == 'success': success_found = True break assert success_found, "Lambda function execution did not report 'success' status in logs." @pytest.mark.order(3) def test_encrypted_file_in_bucket(s3_client): # Specify the destination S3 bucket and the expected converted file key destination_bucket = 'amzn-s3-demo-bucket-encrypted' converted_file_key = 'test_encrypted.pdf' try: # Attempt to retrieve the metadata of the converted file from the destination S3 bucket s3_client.head_object(Bucket=destination_bucket, Key=converted_file_key) except s3_client.exceptions.ClientError as e: # If the file is not found, the test will fail pytest.fail(f"Converted file '{converted_file_key}' not found in the destination bucket: {str(e)}") def test_cleanup(cleanup): # This test uses the cleanup fixture and will be executed last pass
Lo script di test automatizzato esegue tre funzioni di test per confermare il corretto funzionamento dell'app:
-
Il test
test_source_bucket_availableconferma che il bucket di origine è stato creato correttamente caricando un file PDF di prova nel bucket. -
Il test
test_lambda_invokedinterroga il flusso di log di CloudWatch Logs più recente della funzione per confermare che quando hai caricato il file di test, la funzione Lambda è stata eseguita e ha segnalato il successo. -
Il test
test_encrypted_file_in_bucketconferma che il bucket di destinazione contiene il file crittografatotest_encrypted.pdf.
Dopo l'esecuzione di tutti questi test, lo script esegue un ulteriore passaggio di pulizia per eliminare i file test.pdf e test_encrypted.pdf dai bucket di origine e di destinazione.
Come nel AWS SAM modello, i nomi dei bucket specificati in questo file sono segnaposto. Prima di eseguire il test, devi modificare questo file con i nomi reali dei bucket dell'app. Questo passaggio viene spiegato ulteriormente in Test dell'app con lo script automatico.
Copia e incolla il codice seguente in un nuovo file pytest.ini.
[pytest] markers = order: specify test execution order
È necessario per specificare l'ordine in cui vengono eseguiti i test nello script test_pdf_encrypt.py.
Per eseguire i test, procedere come segue:
-
Assicurati che il
pytestmodulo sia installato nel tuo ambiente locale. È possibile installarepytesteseguendo il comando seguente:pip install pytest -
Salva un file PDF denominato
test.pdfnella directory contenente ipytest.inifiletest_pdf_encrypt.pyand. -
Apri un programma di terminale o di shell ed esegui il comando sotto riportato dalla directory contenente i file di test.
pytest -s -vUna volta completato il test, l'output dovrebbe essere simile al seguente:
============================================================== test session starts ========================================================= platform linux -- Python 3.12.2, pytest-7.2.2, pluggy-1.0.0 -- /usr/bin/python3 cachedir: .pytest_cache hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/home/pdf_encrypt_app/.hypothesis/examples') Test order randomisation NOT enabled. Enable with --random-order or --random-order-bucket=<bucket_type> rootdir: /home/pdf_encrypt_app, configfile: pytest.ini plugins: anyio-3.7.1, hypothesis-6.70.0, localserver-0.7.1, random-order-1.1.0 collected 4 items test_pdf_encrypt.py::test_source_bucket_available PASSED test_pdf_encrypt.py::test_lambda_invoked PASSED test_pdf_encrypt.py::test_encrypted_file_in_bucket PASSED test_pdf_encrypt.py::test_cleanup PASSED Deleted test.pdf from amzn-s3-demo-bucket Deleted test_encrypted.pdf from amzn-s3-demo-bucket-encrypted =============================================================== 4 passed in 7.32s ==========================================================
Fasi successive
Ora che hai creato questa app di esempio, puoi utilizzare il codice fornito come base per creare altri tipi di applicazioni per l'elaborazione di file. Modifica il codice nel file lambda_function.py per implementare la logica di elaborazione dei file per il tuo caso d'uso.
Numerosi casi d'uso tipici dell'elaborazione di file riguardano l'elaborazione delle immagini. Quando si usa Python, le librerie di elaborazione delle immagini più popolari come pillow
Quando si distribuiscono le risorse con AWS SAM, è necessario adottare alcune misure aggiuntive per includere la corretta distribuzione dei sorgenti nel pacchetto di distribuzione. Poiché AWS SAM non installerà dipendenze per una piattaforma diversa dalla macchina di compilazione, specificare la corretta distribuzione del codice sorgente (.whlfile) nel requirements.txt file non funzionerà se la macchina di compilazione utilizza un sistema operativo o un'architettura diversi dall'ambiente di esecuzione Lambda. Invece, effettua una delle seguenti operazioni:
-
Usa l'opzione
--use-containerdurante l'esecuzione disam build. Quando specifichi questa opzione, AWS SAM scarica un'immagine di base del contenitore compatibile con l'ambiente di esecuzione Lambda e crea il pacchetto di distribuzione della funzione in un contenitore Docker utilizzando quell'immagine. Per ulteriori informazioni, consulta Creazione di una funzione Lambda all'interno di un container fornito. -
Crea tu stesso il pacchetto di distribuzione.zip della tua funzione utilizzando il file binario di distribuzione sorgente corretto e salva il file.zip nella directory specificata come nel modello.
CodeUriAWS SAM Per ulteriori informazioni sulla creazione di pacchetti di implementazione .zip per Python utilizzando distribuzioni binarie, consulta Creazione di un pacchetto di implementazione .zip con dipendenze e Creazione di un pacchetto di implementazione .zip con librerie native.
