翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Transcribe は、動画のサブタイトルとして使用するために WebVTT (*.vtt) および SubRip (*.srt) 出力をサポートします。バッチビデオ文字起こしジョブを設定するときに、1 つまたは両方のファイルタイプを選択できます。字幕機能を使用すると、選択した文字起こしファイルと通常の文字起こしファイル (追加情報を含む) が生成されます。字幕と文字起こしファイルは、同じ出力先に出力されます。
字幕は、テキストが話されると同時に表示され、自然な一時停止があるか、スピーカーが話しかけるまで表示され続けます。文字起こしリクエストで字幕を有効にしても、音声に会話が含まれていない場合、字幕ファイルは作成されないことに注意してください。
重要
Amazon Transcribe は、字幕出力0に のデフォルトの開始インデックスを使用します。これは、 のより広く使用されている値とは異なります1。の開始インデックスが必要な場合は1、 OutputStartIndexパラメータを使用して、 AWS Management Console または API リクエストで指定できます。
誤った開始インデックスを使用すると、他のサービスとの互換性エラーが発生する可能性があるため、字幕を作成する前に、どの開始インデックスが必要かを確認してください。どの値を使うべきかわからない場合は、1 を選択することをおすすめします。詳細については、「Subtitles」を参照してください。
字幕でサポートされる機能は次のとおりです。
-
コンテンツのリダクション — 編集されたコンテンツは、字幕と通常の文字起こし出力ファイルで「
PII」として反映されます。音声は変更されません。 -
語彙フィルター — 字幕ファイルは文字起こしファイルから生成されるため、標準の文字起こし出力でフィルタリングした単語も字幕でフィルタリングされます。フィルタされたコンテンツは文字起こしと字幕ファイルに空白 または
***として表示されます。音声は変更されません。 -
話者ダイアライゼーション — 特定の字幕セグメントに複数のスピーカーがある場合、ダッシュを使用して各スピーカーを区別します。これは WebVTT 形式と subRip 形式の両方に適用されます。次に例を示します。
— 人によって話されるテキスト 1
— 人によって話されるテキスト 2
字幕ファイルは、文字起こし出力と同じ Amazon S3 場所に保存されます。
字幕作成のビデオチュートリアルについては、以下を参照してください。
字幕ファイルの生成
AWS Management Console、AWS CLI、または AWS SDK を使用して字幕ファイルを作成できます。次の例を参照してください。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで、[文字起こしジョブ] を選択後、[ジョブの作成] (右上) を選択します。これにより、「ジョブの詳細を指定」ページが開きます。字幕オプションは、出力データ パネルにあります。
-
字幕ファイルに必要な形式を選択し、開始インデックスの値を選択します。 Amazon Transcribe デフォルトは ですが
0、1より広く使用されていることに注意してください。どの値を使うべきかわからない場合は、他のサービスとの互換性が向上する可能性があるため、1を選択することをおすすめします。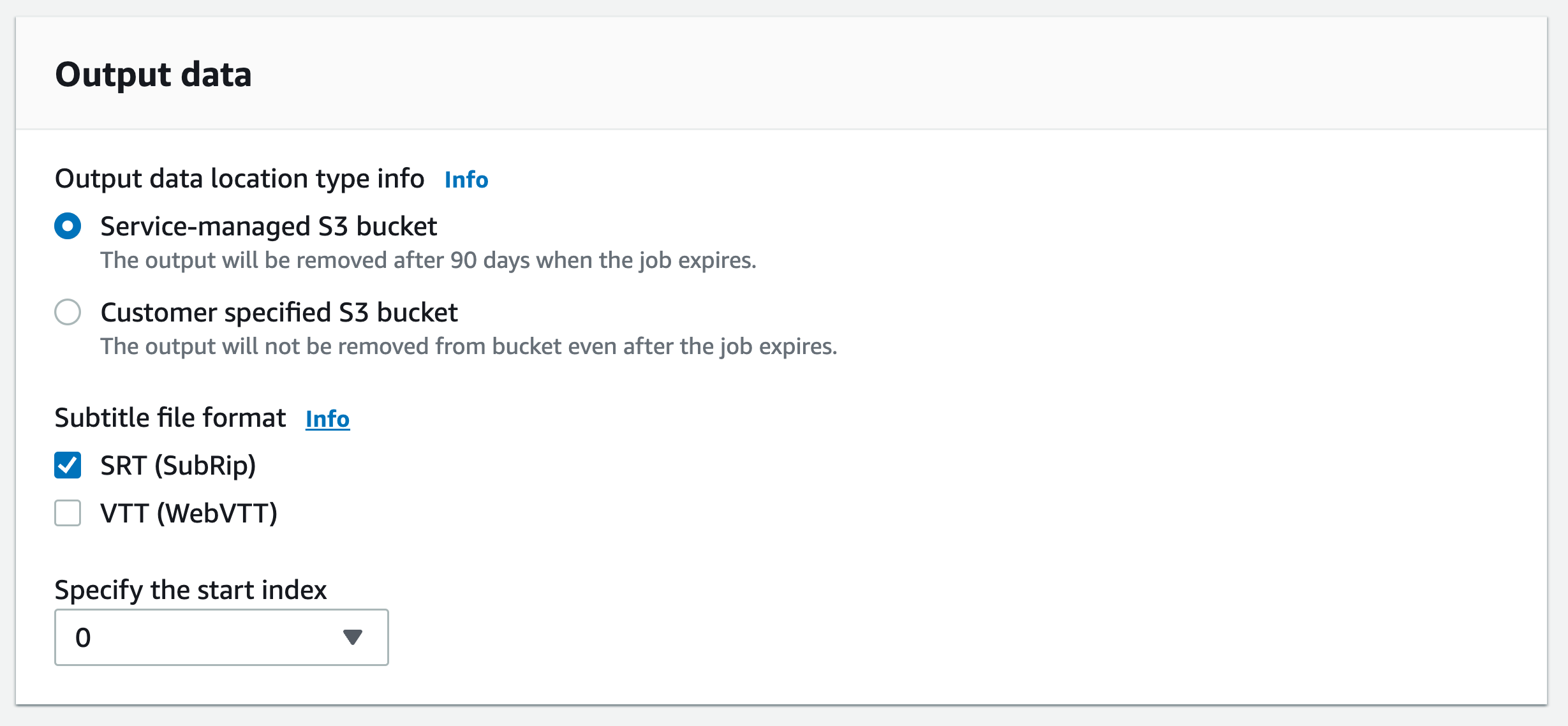
-
ジョブの詳細を指定ページに追加したいその他のフィールドに入力し、「次へ」を選択します。これにより、ジョブの設定 - オプションページへ移動します。
-
[ジョブの作成] を選択して、文字起こしジョブを実行します。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで、[文字起こしジョブ] を選択後、[ジョブの作成] (右上) を選択します。これにより、「ジョブの詳細を指定」ページが開きます。字幕オプションは、出力データ パネルにあります。
-
字幕ファイルに必要な形式を選択し、開始インデックスの値を選択します。 Amazon Transcribe デフォルトは ですが
0、1より広く使用されていることに注意してください。どの値を使うべきかわからない場合は、他のサービスとの互換性が向上する可能性があるため、1を選択することをおすすめします。
-
ジョブの詳細を指定ページに追加したいその他のフィールドに入力し、「次へ」を選択します。これにより、ジョブの設定 - オプションページへ移動します。
-
[ジョブの作成] を選択して、文字起こしジョブを実行します。
この例では、start-transcription-jobSubtitles パラメータを使用します。詳細については、StartTranscriptionJobおよびSubtitlesを参照してください。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --subtitles Formats=vtt,srt,OutputStartIndex=1
別の例として、文字起こしジョブの開始
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-subtitle-job.json
ファイル my-first-subtitle-job.json には、次のリクエストボディが入含まれています。
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Subtitles": {
"Formats": [
"vtt","srt"
],
"OutputStartIndex": 1
}
}この例では、 を使用して AWS SDK for Python (Boto3) 、start_transcription_jobSubtitles引数を使用して字幕を追加します。詳細については、StartTranscriptionJobおよびSubtitlesを参照してください。
機能固有の例、シナリオ例、クロスサービス例など、 AWS SDKsSDK を使用した Amazon Transcribe のコード例 AWS SDKs「」章を参照してください。
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Subtitles = {
'Formats': [
'vtt','srt'
],
'OutputStartIndex': 1
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)