기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Managed Grafana를 사용하여 Amazon EKS 인프라 모니터링을 위한 솔루션
Amazon Elastic Kubernetes Service 인프라 모니터링은 Amazon Managed Grafana에서 사용되는 가장 일반적인 시나리오 중 하나입니다. 이 페이지에서는 해당 시나리오에 대한 템플릿을 제공하는 솔루션을 설명합니다. 솔루션은 AWS Cloud Development Kit (AWS CDK) 또는 Terraform
이 솔루션은 다음을 구성합니다.
-
Amazon Managed Service for Prometheus 워크스페이스는 Amazon EKS 클러스터의 지표를 저장하고, 지표를 스크레이핑하여 해당 워크스페이스로 푸시하는 관리형 수집기를 생성합니다. 자세한 내용은 AWS 관리형 수집기를 사용하여 지표 수집을 참조하세요.
-
CloudWatch 에이전트를 사용하여 Amazon EKS 클러스터에서 로그 수집. 로그는 CloudWatch에 저장되며 Amazon Managed Grafana에서 쿼리됩니다. 자세한 내용은 Logging for Amazon EKS를 참조하세요.
-
Amazon Managed Grafana 워크스페이스는 이러한 로그 및 지표를 가져오고 클러스터를 모니터링하는 데 도움이 되는 대시보드 및 알림을 생성합니다.
이 솔루션을 적용하면 다음과 같은 대시보드 및 알림이 생성됩니다.
-
전체 Amazon EKS 클러스터 상태를 평가합니다.
-
Amazon EKS 컨트롤 플레인의 상태와 성능을 보여줍니다.
-
Amazon EKS 데이터 플레인의 상태와 성능을 보여줍니다.
-
여러 Kubernetes 네임스페이스에서 Amazon EKS 워크로드에 대한 인사이트를 표시합니다.
-
CPU, 메모리, 디스크 및 네트워크 사용량을 포함하여 여러 네임스페이스에서 리소스 사용량을 표시합니다.
이 솔루션 소개
이 솔루션에서는 Amazon EKS 클러스터에 대한 지표를 제공하도록 Amazon Managed Grafana 워크스페이스를 구성합니다. 지표는 대시보드 및 알림을 생성하는 데 사용됩니다.
지표는 Kubernetes 컨트롤 및 데이터 플레인의 상태와 성능에 대한 인사이트를 제공하여 Amazon EKS 클러스터를 더 효과적으로 운영하는 데 도움이 됩니다. 자세한 리소스 사용량 모니터링을 비롯하여 노드 수준에서 포드, Kubernetes 수준까지 Amazon EKS 클러스터를 파악할 수 있습니다.
이 솔루션은 예상 및 수정 기능을 모두 제공합니다.
-
예상 기능의 특성:
-
예약 결정을 주도하여 리소스 효율성을 관리합니다. 예를 들어 Amazon EKS 클러스터의 내부 사용자에게 성능 및 신뢰성 SLA를 제공하기 위해 과거 사용량 추적을 기반으로 워크로드에 충분한 CPU 및 메모리 리소스를 할당할 수 있습니다.
-
사용량 예측: 노드, Amazon EBS에서 지원하는 영구 볼륨 또는 Application Load Balancer와 같은 Amazon EKS 클러스터 리소스의 현재 사용률을 기준으로 수요가 유사한 새 제품 또는 프로젝트에 대해 미리 계획할 수 있습니다.
-
잠재적 문제 조기에 감지: 예를 들어 Kubernetes 네임스페이스 수준에서 리소스 소비 추세를 분석하여 워크로드 사용량의 계절성을 이해할 수 있습니다.
-
-
수정 기능의 특성:
-
인프라 및 Kubernetes 워크로드 수준에서 문제의 평균 탐지 시간(MTTD)을 줄입니다. 예를 들어 문제 해결 대시보드를 보면 무엇이 잘못되었는지에 대한 가설을 빠르게 테스트하고 문제가 되는 요소를 제거할 수 있습니다.
-
스택에서 문제가 발생하는 위치를 확인합니다. 예를 들어 Amazon EKS 컨트롤 플레인은에서 완전히 관리 AWS 되며 API 서버에 과부하가 걸리거나 연결이 영향을 받는 경우 Kubernetes 배포 업데이트와 같은 특정 작업이 실패할 수 있습니다.
-
다음 이미지에서는 솔루션의 대시보드 폴더 샘플을 보여줍니다.
대시보드를 선택하여 자세한 내용을 볼 수 있습니다. 예를 들어 워크로드에 대한 리소스 계산을 보려고 선택하면 다음 이미지와 같은 대시보드가 표시됩니다.
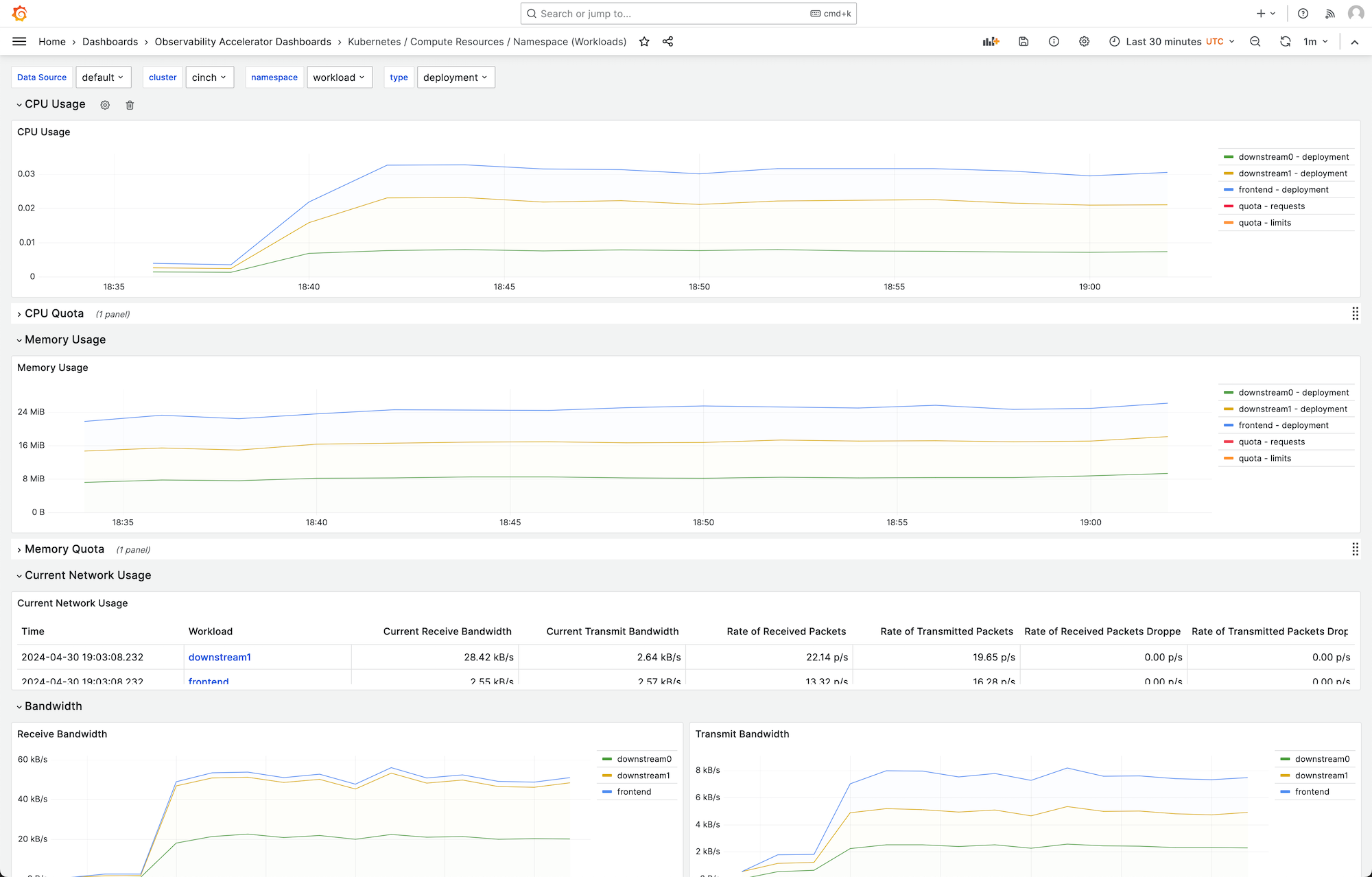
지표는 스크레이프 간격 1분으로 스크레이핑됩니다. 대시보드는 특정 지표를 기반으로 1분, 5분 또는 그 이상으로 집계된 지표를 표시합니다.
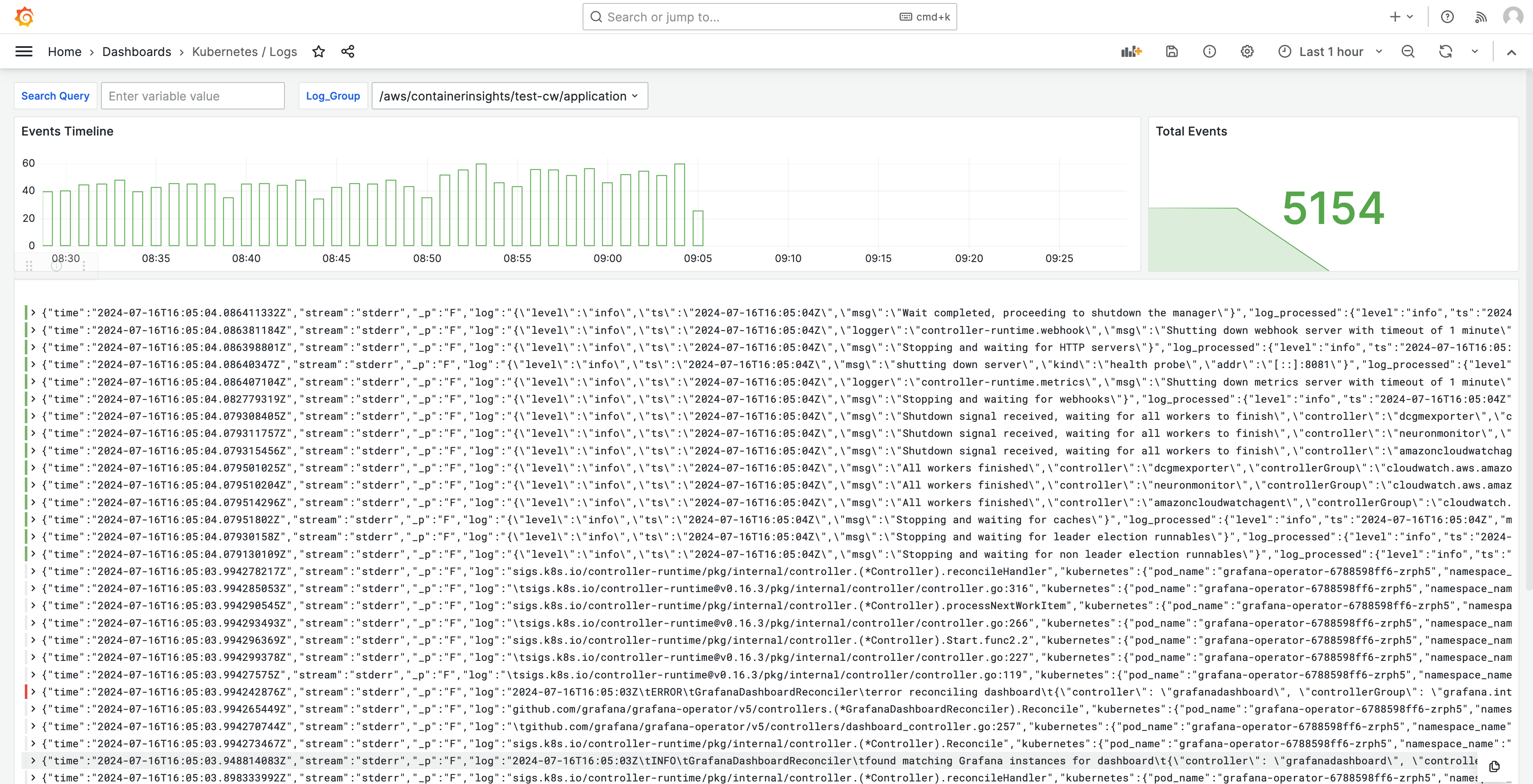
로그는 대시보드에도 표시되므로 로그를 쿼리하고 분석하여 문제의 근본 원인을 찾을 수 있습니다. 다음 이미지에서는 로그 대시보드를 보여줍니다.
이 솔루션으로 추적되는 지표 목록은 추적된 지표 목록 섹션을 참조하세요.
솔루션에서 생성된 알림 목록은 생성된 알림 목록 섹션을 참조하세요.
비용
이 솔루션은 워크스페이스에서 리소스를 생성하고 사용합니다. 다음을 포함하여 생성된 리소스의 표준 사용에 대한 요금이 부과됩니다.
-
사용자의 Amazon Managed Grafana 워크스페이스 액세스. 요금에 대한 자세한 내용은 Amazon Managed Grafana 요금
을 참조하세요. -
Amazon Managed Service for Prometheus의 에이전트 없는 수집기 사용 및 지표 분석(쿼리 샘플 처리)을 포함한 Amazon Managed Service for Prometheus 지표 수집 및 스토리지. 이 솔루션에서 사용하는 지표 수는 Amazon EKS 클러스터 구성 및 사용량에 따라 달라집니다.
CloudWatch를 사용하여 Amazon Managed Service for Prometheus에서 수집 및 스토리지 지표를 볼 수 있습니다. 자세한 내용은 Amazon Managed Service for Prometheus 사용 설명서의 CloudWatch metrics를 참조하세요.
Amazon Managed Service for Prometheus 요금
페이지에서 요금 계산기를 사용하여 비용을 예측할 수 있습니다. 지표 수는 클러스터의 노드 수 및 애플리케이션이 생성하는 지표에 따라 달라집니다. -
CloudWatch Logs 수집, 스토리지 및 분석. 기본적으로 로그 보존은 만료되지 않도록 설정됩니다. CloudWatch에서 이 항목을 조정할 수 있습니다. 요금에 대한 자세한 내용은 Amazon CloudWatch 요금
을 참조하세요. -
네트워킹 비용. 교차 가용 영역, 리전 또는 기타 트래픽에 대해 표준 AWS 네트워크 요금이 발생할 수 있습니다.
각 제품의 요금 페이지에서 사용할 수 있는 요금 계산기는 솔루션의 잠재적 비용을 이해하는 데 도움이 될 수 있습니다. 다음 정보는 Amazon EKS 클러스터와 동일한 가용 영역에서 실행되는 솔루션에 대한 기본 비용을 얻는 데 도움이 될 수 있습니다.
| 제품 | 계산기 지표 | 값 |
|---|---|---|
– Amazon Managed Service for Prometheus |
활성 시리즈 |
8,000(기본) 15,000(노드당) |
평균 수집 간격 |
60(초) |
|
Amazon Managed Service for Prometheus(관리형 수집기) |
수집기 수 |
1 |
샘플 수 |
15(기본) 150(노드당) |
|
규칙 수 |
161 |
|
평균 규칙 추출 간격 |
60(초) |
|
Amazon Managed Grafana |
활성 편집자/관리자 수 |
1 이상, 사용자 기준 |
CloudWatch(Logs) |
표준 로그: 수집된 데이터 |
24.5GB(기본) 0.5GB(노드당) |
로그 스토리지/아카이브(표준 및 벤딩 로그) |
예, 로그 저장: 1개월 보존 가정 |
|
스캔된 예상 로그 데이터 |
Grafana의 각 로그 인사이트 쿼리는 지정된 기간 그룹의 모든 로그 콘텐츠를 스캔합니다. |
이 숫자는 추가 소프트웨어 없이 EKS를 실행하는 솔루션의 기본 숫자입니다. 이렇게 하면 기본 비용을 예측할 수 있습니다. 또한 Amazon Managed Grafana 워크스페이스, Amazon Managed Service for Prometheus 워크스페이스 및 Amazon EKS 클러스터가 동일한 가용 영역에 있는지 여부 AWS 리전, VPN에 따라 달라지는 네트워크 사용 비용을 제외합니다.
참고
이 테이블의 항목에 리소스당 값(예: (per node)) 및 (base) 값이 포함된 경우 해당 리소스에서 보유한 수에 리소스당 값을 곱한 숫자에 기본 값을 더해야 합니다. 예를 들어 평균 활성 시계열에 숫자(8000 + the number of nodes in your cluster * 15,000)를 입력합니다. 노드가 2개인 경우 38,000(8000 + ( 2 * 15,000 ))을 입력합니다.
사전 조건
이 솔루션을 사용하려면 솔루션을 사용하기 전에 다음을 수행해야 합니다.
-
모니터링하려는 Amazon Elastic Kubernetes Service 클러스터가 있거나 생성되어야 하며, 클러스터에는 하나 이상의 노드가 있어야 합니다. 프라이빗 액세스를 포함하려면 클러스터에 API 서버 엔드포인트 액세스가 설정되어 있어야 합니다(퍼블릭 액세스도 허용 가능).
인증 모드에 API 액세스가 포함되어야 합니다(
API또는API_AND_CONFIG_MAP으로 설정 가능). 이 경우 솔루션 배포에서 액세스 항목을 사용할 수 있습니다.클러스터에 다음을 설치해야 합니다(콘솔을 통해 클러스터를 생성할 때 기본적으로 true이지만 AWS API 또는를 사용하여 클러스터를 생성하는 경우 추가해야 함 AWS CLI). AWS CNI, CoreDNS 및 Kube-proxy AddOns.
나중에 지정하도록 클러스터 이름을 저장합니다. Amazon EKS 콘솔의 클러스터 세부 정보에서 확인할 수 있습니다.
참고
Amazon EKS 클러스터를 생성하는 방법에 대한 자세한 내용은 Amazon EKS 시작하기를 참조하세요.
-
Amazon EKS 클러스터와 동일한에서 Amazon Managed Service for Prometheus 워크스페이스를 생성해야 합니다. AWS 계정 자세한 내용은 Amazon Managed Service for Prometheus 사용 설명서의 Create a workspace를 참조하세요.
나중에 지정하도록 Amazon Managed Service for Prometheus 워크스페이스 ARN을 저장합니다.
-
Amazon EKS 클러스터와 동일한에서 Grafana 버전 9 이상을 사용하여 Amazon Managed Grafana 워크스페이스를 생성해야 합니다. AWS 리전 새 워크스페이스 생성에 대한 자세한 내용은 Amazon Managed Grafana 워크스페이스 생성 섹션을 참조하세요.
워크스페이스 역할에는 Amazon Managed Service for Prometheus 및 Amazon CloudWatch API에 액세스하는 권한이 필요합니다. 이를 수행하는 가장 쉬운 방법은 서비스 관리형 권한을 사용하고 Amazon Managed Service for Prometheus 및 CloudWatch를 선택하는 것입니다. AmazonPrometheusQueryAccess 및 AmazonGrafanaCloudWatchAccess 정책을 워크스페이스 IAM 역할에 수동으로 추가할 수도 있습니다.
나중에 지정하도록 Amazon Managed Grafana 워크스페이스 ID 및 엔드포인트를 저장합니다. ID는
g-123example양식입니다. ID 및 엔드포인트는 Amazon Managed Grafana 콘솔에서 찾을 수 있습니다. 엔드포인트는 워크스페이스의 URL이며 ID를 포함합니다. 예를 들어https://g-123example.grafana-workspace.<region>.amazonaws.com/입니다. -
Terraform을 사용하여 솔루션을 배포하는 경우 계정에서 액세스할 수 있는 Amazon S3 버킷을 생성해야 합니다. 배포를 위해 Terraform 상태 파일을 저장하는 데 사용됩니다.
나중에 지정하도록 Amazon S3 버킷 ID를 저장합니다.
-
Amazon Managed Service for Prometheus 알림 규칙을 보려면 Amazon Managed Grafana 워크스페이스에 대해 Grafana 알림을 활성화해야 합니다.
또한 Amazon Managed Grafana에는 Prometheus 리소스에 대한 다음과 같은 권한이 있어야 합니다. AWS 데이터 소스에 대한 Amazon Managed Grafana 권한 및 정책에 설명된 서비스 관리형 또는 고객 관리형 정책에 추가해야 합니다.
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
참고
솔루션을 설정하는 데 반드시 필요한 것은 아니지만 사용자가 생성된 대시보드에 액세스하기 전에 Amazon Managed Grafana 워크스페이스에서 사용자 인증을 설정해야 합니다. 자세한 내용은 Amazon Managed Grafana 워크스페이스에서 사용자 인증 단원을 참조하십시오.
이 솔루션 사용
이 솔루션은 Amazon EKS 클러스터의 보고 및 모니터링 지표를 지원하도록 AWS 인프라를 구성합니다. AWS Cloud Development Kit (AWS CDK) 또는 Terraform
추적된 지표 목록
이 솔루션은 Amazon EKS 클러스터에서 지표를 수집하는 스크레이퍼를 생성합니다. 이러한 지표는 Amazon Managed Service for Prometheus에 저장된 다음, Amazon Managed Grafana 대시보드에 표시됩니다. 기본적으로 스크레이퍼는 클러스터에서 공개되는 모든 Prometheus 호환 지표를 수집합니다. 더 많은 지표를 생성하는 소프트웨어를 클러스터에 설치하면 수집되는 지표가 증가합니다. 원하는 경우 지표를 필터링하는 구성으로 스크레이퍼를 업데이트하여 지표 수를 줄일 수 있습니다.
다음 지표는 추가 소프트웨어가 설치되지 않은 기본 Amazon EKS 클러스터 구성에서 이 솔루션으로 추적됩니다.
| 지표 | 설명/목적 |
|---|---|
|
|
사용할 수 없는 항목으로 표시된 APIServices 게이지(APIServices 이름으로 분류됨). |
|
|
관리 웹후크 지연 시간 히스토그램(초 단위, 이름으로 식별되고 각 작업 및 API 리소스와 유형(검증 또는 승인)에 대해 분류됨). |
|
|
마지막 순간에 요청 종류당 이 apiserver에서 현재 사용된 이동 중인 요청 제한에 대한 최대 수. |
|
|
현재 캐시된 DEK에서 차지하는 캐시 슬롯 비율. |
|
|
API Priority and Fairness 하위 시스템에서 초기(WATCH의 경우) 또는 임의(WATCH가 아닌 경우) 실행 단계의 요청 수. |
|
|
API Priority and Fairness 하위 시스템에서 초기(WATCH의 경우) 또는 임의(WATCH가 아닌 경우) 실행 단계의 거부된 요청 수. |
|
|
각 우선순위 수준에 대해 구성된 공칭 실행 시트 수. |
|
|
API Priority and Fairness 하위 시스템에서 요청 실행의 초기 단계(WATCH의 경우) 또는 임의 단계(WATCH가 아닌 경우)에 대한 지속 시간의 버킷화된 히스토그램. |
|
|
API Priority and Fairness 하위 시스템에서 요청 실행의 초기 단계(WATCH의 경우) 또는 임의 단계(WATCH가 아닌 경우)에 대한 수. |
|
|
API 서버 요청을 나타냅니다. |
|
|
요청되었지만 더 이상 사용되지 않는 API의 게이지(API 그룹, 버전, 리소스, 하위 리소스, removed_release로 분류됨). |
|
|
각 동사, 드라이 런 값, 그룹, 버전, 리소스, 하위 리소스, 범위 및 구성 요소에 대한 응답 지연 시간 분포(초 단위). |
|
|
각 동사, 드라이 런 값, 그룹, 버전, 리소스, 하위 리소스, 범위 및 구성 요소에 대한 응답 지연 시간 분포의 버킷화된 히스토그램(초 단위). |
|
|
각 동사, 드라이 런 값, 그룹, 버전, 리소스, 하위 리소스, 범위 및 구성 요소에 대한 서비스 수준 목표(SLO) 응답 지연 시간 분포(초 단위). |
|
|
자체 방어로 apiserver에서 종료한 요청 수. |
|
|
각 동사, 드라이 런 값, 그룹, 버전, 리소스, 범위, 구성 요소 및 HTTP 응답 코드에 대해 분류된 apiserver 요청의 카운터. |
|
|
누적 CPU 소비 시간. |
|
|
누적 읽기 바이트 수. |
|
|
완료된 누적 읽기 수. |
|
|
작성된 누적 바이트 수. |
|
|
완료된 누적 쓰기 수. |
|
|
총 페이지 캐시 메모리. |
|
|
RSS의 크기. |
|
|
컨테이너 스왑 사용량. |
|
|
현재 작업 중 세트. |
|
|
수신된 누적 바이트 수. |
|
|
수신 중 삭제된 누적 패킷 수. |
|
|
수신된 누적 패킷 수. |
|
|
전송된 누적 바이트 수. |
|
|
전송 중 삭제된 누적 패킷 수. |
|
|
전송된 누적 패킷 수. |
|
|
각 작업 및 객체 유형에 대한 etcd 요청 지연 시간의 버킷화된 히스토그램(초 단위). |
|
|
현재 존재하는 goroutines 수. |
|
|
생성된 OS 스레드 수. |
|
|
cgroup manager 작업에 대한 버킷화된 히스토그램(초 단위). 메서드에 따라 분류됩니다. |
|
|
cgroup manager 작업에 대한 지속 시간(초 단위). 메서드에 따라 분류됩니다. |
|
|
이 지표는 노드에서 구성 관련 오류가 발생하는 경우 참(1)이고, 그렇지 않으면 거짓(0)입니다. |
|
|
노드의 이름. 수는 항상 1입니다. |
|
|
PLEG에서 포드를 다시 나열하기 위한 버킷화된 히스토그램(초 단위). |
|
|
PLEG에서 포드를 다시 나열하기 위한 지속 시간 수(초 단위). |
|
|
PLEG에서 다시 나열 작업 간격의 버킷화된 히스토그램(초 단위). |
|
|
kubelet에서 포드를 처음 확인한 시점부터 포드 실행이 시작된 시점까지의 지속 시간 수(초 단위). |
|
|
단일 포드를 동기화하기 위한 버킷화된 히스토그램(초 단위). 작업 유형별(즉, 생성, 업데이트 또는 동기화)로 분류됩니다. |
|
|
단일 포드를 동기화하기 위한 지속 시간 수(초 단위). 작업 유형별(즉, 생성, 업데이트 또는 동기화)로 분류됩니다. |
|
|
현재 실행 중인 컨테이너 수. |
|
|
실행 중인 포드 샌드박스가 있는 포드 수. |
|
|
런타임 작업에 대한 지속 시간의 버킷화된 히스토그램(초 단위). 작업 유형별로 분류되었습니다. |
|
|
작업 유형별 누적 런타임 작업 오류 수. |
|
|
작업 유형별 누적 런타임 작업 수. |
|
|
포드에 대해 할당 가능한 리소스의 양(시스템 대몬에 대해 일부 예약 후). |
|
|
노드에 대해 사용 가능한 총 리소스 수. |
|
|
컨테이너별로 요청된 제한 리소스 수. |
|
|
컨테이너별로 요청된 제한 리소스 수. |
|
|
컨테이너별 요청된 요청 리소스 수. |
|
|
컨테이너별 요청된 요청 리소스 수. |
|
|
포드 소유자에 대한 정보. |
|
|
Kubernetes의 리소스 할당량은 네임스페이스 내의 CPU, 메모리 및 스토리지와 같은 리소스에 사용 제한을 적용합니다. |
|
|
코어당 사용량 및 총 사용량을 포함한 노드의 CPU 사용량 지표. |
|
|
각 모드에서 소비한 CPU(초 단위). |
|
|
노드가 디스크에서 I/O 작업을 수행하는 데 소요한 누적 시간. |
|
|
노드가 디스크에서 I/O 작업을 수행하는 데 소요한 총 시간. |
|
|
노드별로 디스크에서 읽은 총 바이트 수. |
|
|
노드별로 디스크에 쓴 총 바이트 수. |
|
|
Kubernetes 클러스터에 있는 노드의 파일 시스템에서 사용 가능한 공간의 바이트 수. |
|
|
노드에서 파일 시스템의 총 크기. |
|
|
노드 CPU 사용량의 1분 로드 평균. |
|
|
노드 CPU 사용량의 15분 로드 평균. |
|
|
노드 CPU 사용량의 5분 로드 평균. |
|
|
노드의 운영 체제에서 버퍼 캐싱에 사용되는 메모리의 양. |
|
|
노드의 운영 체제에서 디스크 캐싱에 사용되는 메모리의 양. |
|
|
애플리케이션 및 캐시에서 사용 가능한 메모리의 양. |
|
|
호스트에서 사용 가능한 메모리의 양. |
|
|
노드에서 사용 가능한 총 물리적 메모리의 양. |
|
|
포드에서 네트워크를 통해 수신된 총 바이트 수. |
|
|
포드에서 네트워크를 통해 전송된 총 바이트 수. |
|
|
소비된 총 사용자 및 시스템 CPU 시간(초 단위). |
|
|
상주 메모리 크기(바이트 단위). |
|
|
상태 코드, 메서드 및 호스트로 분할된 HTTP 요청 수. |
|
|
요청 지연 시간의 버킷화된 히스토그램(초 단위). 동사 및 호스트별로 분류됩니다. |
|
|
스토리지 작업 지속 시간의 버킷화된 히스토그램. |
|
|
스토리지 작업 지속 시간 수. |
|
|
스토리지 작업 중 누적 오류 수. |
|
|
모니터링된 대상(예: 노드)이 가동 및 실행 중인지 여부를 나타내는 지표. |
|
|
볼륨 관리자가 관리하는 총 볼륨 수. |
|
|
작업 대기열에서 처리한 총 추가 수. |
|
|
현재 작업 대기열 깊이. |
|
|
항목이 요청 전에 작업 대기열에 머무는 시간의 버킷화된 히스토그램(초 단위). |
|
|
작업 대기열에서 항목을 처리하는 데 걸리는 시간의 버킷화된 히스토그램(초 단위). |
생성된 알림 목록
다음 표에는 이 솔루션에서 생성된 알림이 나열되어 있습니다. 알림은 Amazon Managed Service for Prometheus에서 규칙으로 생성되며 Amazon Managed Grafana 워크스페이스에 표시됩니다.
Amazon Managed Service for Prometheus 워크스페이스에서 규칙 구성 파일을 편집하여 규칙 추가 또는 삭제를 포함해 규칙을 수정할 수 있습니다.
이 두 알림은 일반적인 알림와 약간 다르게 처리되는 특수 알림입니다. 문제를 알리는 대신 시스템을 모니터링하는 데 사용되는 정보를 제공합니다. 설명에는 이러한 알림을 사용하는 방법에 대한 세부 정보가 포함되어 있습니다.
| Alert | 설명 및 사용 |
|---|---|
|
전체 알림 파이프라인이 작동하는지 확인하기 위한 알림입니다. 이 알림은 항상 실행 중이므로 항상 Alertmanager에서 항상 실행 중이고, 항상 수신기에서 실행되어야 합니다. 알림 메커니즘과 통합하여 이 알림이 실행 중이 아닐 때 알림을 보낼 수 있습니다. 예를 들어 PagerDuty에서 DeadMansSnitch 통합을 사용할 수 있습니다. |
|
정보 알림을 금지하는 데 사용되는 알림입니다. 정보 수준 알림 자체는 매우 번거로울 수 있지만 다른 알림과 결합할 때 관련이 있습니다. 이 알림은 |
다음 알림은 시스템에 대한 정보 또는 경고를 제공합니다.
| Alert | 심각도 | 설명 |
|---|---|---|
|
|
warning |
네트워크 인터페이스에서 상태를 변경하는 경우가 많습니다. |
|
|
warning |
파일 시스템에서는 향후 24시간 이내에 공간 부족이 예상됩니다. |
|
|
critical |
파일 시스템에서는 향후 4시간 이내에 공간 부족이 예상됩니다. |
|
|
warning |
파일 시스템의 남은 공간이 5% 미만입니다. |
|
|
critical |
파일 시스템의 남은 공간이 3% 미만입니다. |
|
|
warning |
파일 시스템에서는 향후 24시간 이내에 Inodes 부족이 예상됩니다. |
|
|
critical |
파일 시스템에서는 향후 4시간 이내에 Inodes 부족이 예상됩니다. |
|
|
warning |
파일 시스템의 남은 Inodes가 5% 미만입니다. |
|
|
critical |
파일 시스템의 남은 Inodes가 3% 미만입니다. |
|
|
warning |
네트워크 인터페이스에서 많은 수신 오류를 보고하고 있습니다. |
|
|
warning |
네트워크 인터페이스에서 많은 전송 오류를 보고하고 있습니다. |
|
|
warning |
conntrack 항목 수가 제한에 근접하고 있습니다. |
|
|
warning |
Node Exporter 텍스트 파일 수집기에서 스크레이핑하지 못했습니다. |
|
|
warning |
시계 왜곡이 감지되었습니다. |
|
|
warning |
시계가 동기화되지 않습니다. |
|
|
critical |
RAID 배열 성능이 저하됨 |
|
|
warning |
RAID 배열에서 실패한 디바이스 |
|
|
warning |
커널에서 곧 파일 설명자 제한을 소진할 것으로 예상됩니다. |
|
|
critical |
커널에서 곧 파일 설명자 제한을 소진할 것으로 예상됩니다. |
|
|
warning |
노드가 준비되지 않았습니다. |
|
|
warning |
노드에 연결할 수 없습니다. |
|
|
info |
Kubelet에서 용량으로 실행 중입니다. |
|
|
warning |
노드 준비 상태가 플래핑 중입니다. |
|
|
warning |
Kubelet 포드 수명 주기 이벤트 생성기에서 다시 나열하는 데 너무 오래 걸립니다. |
|
|
warning |
Kubelet Pod 시작 지연 시간이 너무 깁니다. |
|
|
warning |
Kubelet 클라이언트 인증서가 곧 만료됩니다. |
|
|
critical |
Kubelet 클라이언트 인증서가 곧 만료됩니다. |
|
|
warning |
Kubelet 서버 인증서가 곧 만료됩니다. |
|
|
critical |
Kubelet 서버 인증서가 곧 만료됩니다. |
|
|
warning |
Kubelet에서 클라이언트 인증서를 갱신하지 못했습니다. |
|
|
warning |
Kubelet에서 서버 인증서를 갱신하지 못했습니다. |
|
|
critical |
Prometheus 대상 검색에서 대상이 사라졌습니다. |
|
|
warning |
실행 중인 Kubernetes 구성 요소의 다양한 시맨틱 버전. |
|
|
warning |
Kubernetes API 서버 클라이언트에서 오류가 발생했습니다. |
|
|
warning |
클라이언트 인증서가 곧 만료됩니다. |
|
|
critical |
클라이언트 인증서가 곧 만료됩니다. |
|
|
warning |
Kubernetes 집계 API에서 오류를 보고했습니다. |
|
|
warning |
Kubernetes 집계 API가 중단었습니다. |
|
|
critical |
Prometheus 대상 검색에서 대상이 사라졌습니다. |
|
|
warning |
kubernetes apiserver에서 수신 요청의 {{ $value | humanizePercentage }}을(를) 종료했습니다. |
|
|
critical |
영구 볼륨이 채워지는 중입니다. |
|
|
warning |
영구 볼륨이 채워지는 중입니다. |
|
|
critical |
영구 볼륨 Inodes가 채워지는 중입니다. |
|
|
warning |
영구 볼륨 Inodes가 채워지는 중입니다. |
|
|
critical |
영구 볼륨에 프로비저닝 관련 문제가 있습니다. |
|
|
warning |
클러스터에 CPU 리소스 요청이 과도하게 커밋되었습니다. |
|
|
warning |
클러스터에 메모리 리소스 요청이 과도하게 커밋되었습니다. |
|
|
warning |
클러스터에 CPU 리소스 요청이 과도하게 커밋되었습니다. |
|
|
warning |
클러스터에 메모리 리소스 요청이 과도하게 커밋되었습니다. |
|
|
info |
네임스페이스 할당량이 가득 찰 예정입니다. |
|
|
info |
네임스페이스 할당량이 완전히 사용되었습니다. |
|
|
warning |
네임스페이스 할당량이 제한을 초과했습니다. |
|
|
info |
프로세스에서 CPU 스로틀링이 높아졌습니다. |
|
|
warning |
포드에서 충돌 루프가 발생합니다. |
|
|
warning |
포드가 15분 넘게 준비되지 않은 상태입니다. |
|
|
warning |
잠재적 롤백으로 인한 배포 생성 불일치 |
|
|
warning |
배포가 예상 복제본 수와 일치하지 않습니다. |
|
|
warning |
StatefulSet가 예상 복제본 수와 일치하지 않습니다. |
|
|
warning |
잠재적 롤백으로 인한 StatefulSet 생성 불일치 |
|
|
warning |
StatefulSet 업데이트가 롤아웃되지 않았습니다. |
|
|
warning |
DaemonSet 롤아웃이 멈췄었습니다. |
|
|
warning |
1시간 넘게 대기 중인 포드 컨테이너 |
|
|
warning |
DaemonSet 포드가 예약되지 않았습니다. |
|
|
warning |
DaemonSet 포드의 예약이 잘못되었습니다. |
|
|
warning |
작업이 제시간에 완료되지 않음 |
|
|
warning |
작업을 완료하지 못했습니다. |
|
|
warning |
HPA가 원하는 복제본 수와 일치하지 않습니다. |
|
|
warning |
HPA가 최대 복제본에서 실행 중임 |
|
|
critical |
kube-state-metrics에서 목록 작업에 오류가 발생했습니다. |
|
|
critical |
kube-state-metrics에서 감시 작업에 오류가 발생했습니다. |
|
|
critical |
kube-state-metrics 샤딩이 잘못 구성되었습니다. |
|
|
critical |
kube-state-metrics 샤드가 누락되었습니다. |
|
|
critical |
API 서버에서 너무 많은 오류 예산을 소모하고 있습니다. |
|
|
critical |
API 서버에서 너무 많은 오류 예산을 소모하고 있습니다. |
|
|
warning |
API 서버에서 너무 많은 오류 예산을 소모하고 있습니다. |
|
|
warning |
API 서버에서 너무 많은 오류 예산을 소모하고 있습니다. |
|
|
warning |
하나 이상의 대상이 중단되었습니다. |
|
|
critical |
Etcd 클러스터에 멤버가 부족합니다. |
|
|
warning |
Etcd 클러스터에서 리더 변경 횟수가 많습니다. |
|
|
critical |
Etcd 클러스터에 리더가 없습니다. |
|
|
warning |
Etcd 클러스터에서 실패한 gRPC 요청 수가 많습니다. |
|
|
critical |
Etcd 클러스터에서 gRPC 요청이 느립니다. |
|
|
warning |
Etcd 클러스터에서 멤버 통신이 느립니다. |
|
|
warning |
Etcd 클러스터에서 실패한 제안 수가 많습니다. |
|
|
warning |
Etcd 클러스터에서 fsync 지속 시간이 높습니다. |
|
|
warning |
Etcd 클러스터에서 예상 커밋 지속 시간보다 깁니다. |
|
|
warning |
Etcd 클러스터에서 HTTP 요청에 실패했습니다. |
|
|
critical |
Etcd 클러스터에서 실패한 HTTP 요청 수가 많습니다. |
|
|
warning |
Etcd 클러스터에서 HTTP 요청이 느립니다. |
|
|
warning |
호스트 클럭이 동기화되지 않습니다. |
|
|
warning |
호스트 OOM 삭제가 감지되었습니다. |
문제 해결
프로젝트 설정이 실패할 수 있는 몇 가지 조건이 있습니다. 다음을 확인해야 합니다.
-
솔루션을 설치하기 전에 모든 사전 조건을 완료해야 합니다.
-
솔루션을 생성하거나 지표에 액세스하기 전에 클러스터에 하나 이상의 노드가 있어야 합니다.
-
Amazon EKS 클러스터에는
AWS CNI,CoreDNS및kube-proxy추가 기능이 설치되어 있어야 합니다. 설치되지 않으면 솔루션이 제대로 작동하지 않습니다. 콘솔을 통해 클러스터를 생성할 때 기본적으로 설치됩니다. 클러스터가 AWS SDK를 통해 생성된 경우 설치해야 할 수 있습니다. -
Amazon EKS 포드 설치의 제한 시간이 초과되었습니다. 사용 가능한 노드 용량이 충분하지 않은 경우 발생할 수 있습니다. 이러한 문제의 원인은 다음을 포함하여 여러 가지가 있습니다.
-
Amazon EC2 대신 Fargate로 Amazon EKS 클러스터가 초기화되었습니다. 이 프로젝트에는 Amazon EC2가 필요합니다.
-
노드가 테인트되어 사용할 수 없습니다.
kubectl describe node를 사용하여 테인트를 확인할 수 있습니다. 그런 다음,NODENAME| grep Taintskubectl taint node을 통해 테인트를 제거합니다. 테인트 이름 뒤에NODENAMETAINT_NAME--를 포함해야 합니다. -
노드에서 용량 제한에 도달했습니다. 이 경우 새 노드를 생성하거나 용량을 늘릴 수 있습니다.
-
-
Grafana에 대시보드가 표시되지 않음: 잘못된 Grafana 워크스페이스 ID 사용.
다음 명령을 실행하여 노드에 대한 정보를 가져옵니다.
kubectl describe grafanas external-grafana -n grafana-operator올바른 워크스페이스 URL에 대한 결과를 확인할 수 있습니다. 예상과 다른 경우 올바른 워크스페이스 ID로 다시 배포합니다.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
Grafana에 대시보드가 표시되지 않음: 만료된 API 키를 사용하고 있습니다.
이 사례를 확인하려면 Grafana 연산자를 가져와 로그에 오류가 있는지 확인해야 합니다. 이 명령을 사용하여 Grafana 연산자의 이름을 가져옵니다.
kubectl get pods -n grafana-operator그러면 연산자 이름을 반환합니다. 예를 들어 다음과 같습니다.
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2m다음 명령에서 연산자 이름을 사용합니다.
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operator다음과 같은 오류 메시지는 만료된 API 키를 나타냅니다.
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).Reconcile이 경우 새 API 키를 생성하고 솔루션을 다시 배포합니다. 문제가 지속되면 재배포하기 전에 다음 명령을 사용하여 강제 동기화할 수 있습니다.
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
CDK installs – 누락된 SSM 파라미터. 다음과 같은 오류가 표시되면
cdk bootstrap을 실행하고 다시 시도합니다.Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
OIDC 제공업체가 이미 있는 경우 배포에 실패할 수 있습니다. 다음과 같은 오류가 표시됩니다(여기에서는 CDK 설치의 경우).
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.이 경우 IAM 포털로 이동하여 OIDC 제공업체를 삭제하고 다시 시도합니다.
-
Terraform installs -
cluster-secretstore-sm failed to create kubernetes rest client for update of resource및failed to create kubernetes rest client for update of resource를 포함하는 오류 메시지가 표시됩니다.이 오류는 일반적으로 외부 보안 암호 연산자가 Kubernetes 클러스터에 설치되거나 활성화되지 않았음을 나타냅니다. 이는 솔루션 배포의 일부로 설치되지만 솔루션에 필요할 때 준비되지 않는 경우도 있습니다.
다음 명령을 사용하여 설치되었는지 확인합니다.
kubectl get deployments -n external-secrets설치한 경우 연산자가 완전히 사용할 준비가 되는 데 시간이 걸릴 수 있습니다. 다음 명령을 실행하여 필요한 사용자 지정 리소스 정의(CRD)의 상태를 확인할 수 있습니다.
kubectl get crds|grep external-secrets이 명령은
clustersecretstores.external-secrets.io및externalsecrets.external-secrets.io를 포함하여 외부 보안 암호 연산자와 관련된 CRD를 나열해야 합니다. 목록에 없는 경우 몇 분 정도 기다렸다가 다시 확인합니다.CRD가 등록되면 다시
terraform apply를 실행하여 솔루션을 배포할 수 있습니다.
