As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
nota
O Amazon Neptune envia métricas somente quando elas têm CloudWatch um valor diferente de zero.
Para todas as métricas do Neptune, a granularidade da agregação é de cinco minutos.
Métricas de Neptune CloudWatch
A tabela a seguir lista as CloudWatch métricas suportadas pelo Neptune.
nota
Todas as métricas cumulativas são zeradas sempre que o servidor é reiniciado, seja para manutenção, reinicialização ou recuperação de uma falha.
| Métrica | Descrição |
|---|---|
|
A quantidade total do armazenamento de backup, em bytes, usada para oferecer compatibilidade na janela de retenção do backup do cluster de banco de dados do Neptune. Incluído no total relatado pela métrica |
|
A porcentagem de solicitações atendidas pelo cache de buffer. Essa métrica pode ser útil para diagnosticar a latência da consulta, porque as falhas de cache induzem uma latência significativa. Se a taxa de acertos do cache estiver abaixo de 99,9, pense em atualizar o tipo de instância para armazenar mais dados na memória. |
|
Para uma réplica de leitura, o tempo de atraso ao replicar atualizações da instância primária, em milissegundos. |
|
O tempo máximo de atraso entre a instância principal e cada instância de banco de dados do Neptune no cluster de banco de dados, em milissegundos. |
|
O tempo mínimo de atraso entre a instância principal e cada instância de banco de dados do Neptune no cluster de banco de dados, em milissegundos. |
|
O número de créditos de CPU acumulados por uma instância, relatados em intervalos de 5 minutos. É possível usar essa métrica para determinar quanto tempo uma instância de banco de dados pode ser intermitente além do nível de performance da linha de base a uma taxa específica. |
|
O número de créditos de CPU consumidos durante o período especificado, relatados em intervalos de 5 minutos. Essa métrica mede a quantidade de tempo durante o qual as instruções físicas CPUs foram usadas para processar instruções por CPUs alocação virtual para a instância de banco de dados. |
|
O número de créditos excedentes gastos por uma instância ilimitada quando seu valor |
|
O número de créditos excedentes gastos que não são pagos pelos créditos de CPU ganhos e incorrem em uma cobrança adicional. |
|
O percentual de utilização da CPU. |
|
A quantidade de tempo em que a instância está executando, em segundos. |
|
A quantidade de memória de acesso aleatório disponível, em bytes. |
|
O número de bytes de dados de redo log transferidos do primário Região da AWS para o secundário Região da AWS em um banco de dados global do Neptune. |
|
O número de operações de E/S de gravação replicadas da região principal da Região da AWS para o volume do cluster em uma região secundária da Região da AWS. Os cálculos de cobrança para cada cluster de banco de dados em um banco de dados global do Neptune usam a métrica |
|
O número de milissegundos em que um cluster secundário está atrás do cluster principal para transações de usuário e transações do sistema. |
|
Número de erros no lado do cliente por segundo em travessias do Gremlin. |
|
Número de erros no lado do servidor por segundo em travessias do Gremlin. |
|
Número de solicitações por segundo para o mecanismo Gremlin. |
|
O número de WebSocket conexões abertas com Neptune. |
|
Número de erros no lado do cliente por segundo de solicitações do carregador. |
|
Número de solicitações do carregador por segundo. |
|
Número de erros no lado do servidor do carregador por segundo. |
|
O número de solicitações na fila de entrada que aguardam execução. O Neptune começa a controlar a utilização das solicitações quando elas excedem a capacidade máxima da fila. |
|
Aplicável somente a uma instância de banco de dados ou um cluster de banco de dados do Neptune Serverless. No nível da instância, relata uma porcentagem calculada como o número de unidades de capacidade do Neptune NCUs () usadas atualmente pela instância em questão, dividido pela configuração de capacidade máxima da NCU para o cluster. Uma NCU, ou unidade de capacidade do Neptune, consiste em 2 GiB (gibibyte) de memória (RAM), junto com a capacidade do processador virtual (vCPU) e a rede associadas. Em nível de cluster, |
|
A quantidade de throughput de rede recebida e transmitida aos clientes por cada instância no cluster de banco de dados do Neptune, em bytes por segundo. Esse throughput não inclui o tráfego de rede entre instâncias no cluster de banco de dados e o volume do cluster. |
|
A quantidade de throughput de rede recebida e transmitida aos clientes por cada instância no cluster de banco de dados do Neptune, em bytes por segundo. Esse throughput não inclui o tráfego de rede entre instâncias no cluster de banco de dados e o volume do cluster. |
NumIndexDeletesPerSec |
Número de exclusões de índices individuais. As exclusões de cada índice são contadas individualmente. Isso inclui as exclusões que podem ser revertidas se uma consulta encontrar um erro. |
NumIndexInsertsPerSec |
Número de inserções em índices individuais. As inserções em cada índice são contadas separadamente. Isso inclui as inserções que podem ser revertidas se uma consulta encontrar um erro. |
NumIndexReadsPerSec |
Número de declarações digitalizadas de qualquer índice. Qualquer padrão de acesso começa com uma pesquisa em um índice e a leitura de todas as declarações correspondentes. Um aumento nessa métrica pode causar um aumento nas latências de consulta ou na utilização da CPU. |
|
O número de erros OpenCypher do cliente por segundo. |
|
O número de OpenCypher solicitações por segundo. |
|
O número de erros OpenCypher do servidor por segundo. |
|
O número de solicitações enfileiradas por segundo. |
|
Número de acessos ao cache de resultados do Gremlin. |
|
Número de falhas no cache de resultados do Gremlin. |
|
O número de transações confirmadas com êxito por segundo. |
|
O número de transações abertas no servidor por segundo. |
|
Para consultas de gravação, o número de transações por segundo revertidas no servidor devido a erros. Para consultas somente leitura, essa métrica é igual ao número de transações somente leitura concluídas por segundo. |
NumUndoPagesPurged |
Essa métrica indica o número de lotes eliminados. Essa métrica é um indicador do progresso na limpeza. O valor é 0 para instâncias do leitor, e a métrica se aplica somente à instância do escritor. |
|
Número de solicitações por segundo (HTTPS e Bolt) para o mecanismo do openCypher. |
|
O número de conexões abertas do Bolt com o Neptune. |
|
Tamanho total estimado (em bytes) de todos os itens em cache no cache de resultados do Gremlin. |
|
Número de itens no cache de resultados do Gremlin. |
|
O timestamp do item mais antigo armazenado em cache no cache de resultados do Gremlin. |
|
O timestamp do item mais novo armazenado em cache no cache de resultados do Gremlin. |
|
Como uma métrica em nível de instância, Em nível de cluster, o |
|
A quantidade total de armazenamento de backup consumida por todos os snapshots para um cluster de banco de dados do Neptune fora da janela de retenção de backup, em bytes. Incluído no total relatado pela métrica |
|
O número de erros no lado do cliente por segundo em consultas do SPARQL. |
|
Número de solicitações para o mecanismo do SPARQL por segundo. |
|
O número de erros do servidor SPARQL por segundo. |
|
O número total de declarações verificadas para estatísticas do DFE desde a inicialização do servidor. Toda vez que o cálculo de estatísticas é acionado, esse número aumenta e, quando nenhum cálculo está acontecendo, ele permanece estático. Como resultado, se você representá-lo graficamente ao longo do tempo, poderá dizer quando a computação aconteceu e quando não aconteceu: 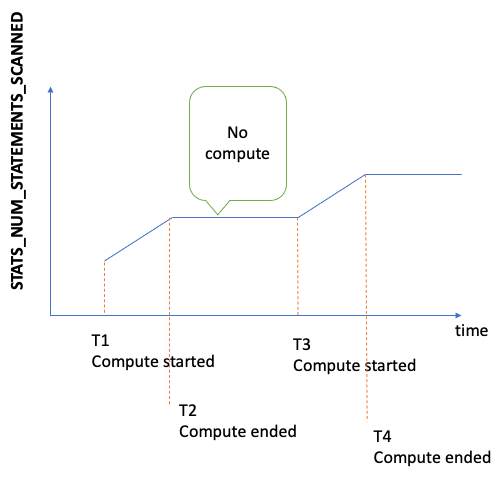
Ao observar a inclinação do grafo nos períodos em que a métrica está aumentando, você também pode ver a rapidez com que o cálculo estava ocorrendo. Se não houver essa métrica, isso significa que o atributo de estatísticas está desabilitado no cluster de banco de dados ou que a versão do mecanismo que você está executando não tem o atributo de estatísticas. Se o valor da métrica for zero, isso significa que não ocorreu nenhum cálculo de estatísticas. |
|
A quantidade de taxa de transferência de rede recebida do subsistema de armazenamento por cada instância no cluster de banco de dados Neptune. |
StorageNetworkThroughput |
A quantidade de taxa de transferência de rede recebida e enviada ao subsistema de armazenamento por cada instância no cluster de banco de dados Neptune. |
|
A quantidade de taxa de transferência de rede enviada ao subsistema de armazenamento por cada instância no cluster de banco de dados Neptune. |
|
A quantidade de espaço de troca usada. |
|
O número de IOPS para leitura e gravação no armazenamento local conectado à instância de banco de dados Neptune. Essa métrica representa uma contagem e é medida uma vez por segundo. |
|
A quantidade de dados transferidos de e para o armazenamento local associado à instância de banco de dados Neptune. Essa métrica é apresentada em bytes e é medida uma vez por segundo. |
|
A quantidade total de armazenamento de backup pela qual você é cobrado para determinado cluster de banco de dados do Neptune, em bytes. Inclui o armazenamento de backup medido pelas métricas |
|
O número total de solicitações por segundo para o servidor de todas as origens. |
|
O número total por segundo de solicitações que falharam devido a problemas no lado do cliente. |
|
O número total por segundo de solicitações que falharam no servidor devido a falhas internas. |
|
A contagem de undo logs na lista de undo logs. Os undo logs contêm registros de transações confirmadas que expiram quando todas as transações ativas são mais recentes do que o tempo de confirmação. Os registros expirados são eliminados periodicamente. Os registros das operações de exclusão podem levar mais tempo para serem eliminados do que os registros de outros tipos de transação. A limpeza é realizada exclusivamente pela instância de gravador do cluster de banco de dados, portanto, a taxa de limpeza depende do tipo de instância de gravador. Se o valor Além disso, se você estiver realizando a atualização para a versão |
|
A quantidade total de armazenamento alocada para o cluster de banco de dados do Neptune, em bytes. Este é o valor do armazenamento pelo qual você é cobrado. É a quantidade máxima de armazenamento alocada para seu cluster de banco de dados em qualquer ponto da sua existência, não a quantidade que você está usando atualmente (consulte Faturamento de armazenamento do Neptune). |
|
O número total de operações de E/S de leitura cobradas de um volume de cluster, relatado em intervalos de 5 minutos. As operações de leitura cobradas são calculadas em nível de volume do cluster, agregadas de todas as instâncias no cluster de banco de dados do Neptune e, depois, relatadas em intervalos de cinco minutos. |
VolumeWriteIOPs |
O número total de operações de E/S de disco de gravação no volume do cluster, relatado em intervalos de 5 minutos. |
CloudWatch Métricas que agora estão obsoletas no Neptune
O uso dessas métricas do Neptune agora está obsoleto. Eles ainda têm suporte, mas poderão ser eliminados no futuro à medida que novas e melhores métricas se tornarem disponíveis.
Métrica |
Descrição |
|---|---|
|
Número de respostas HTTP 1xx para o endpoint do Gremlin por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de respostas HTTP 2xx para o endpoint do Gremlin por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 4xx para o endpoint do Gremlin por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 5xx para o endpoint do Gremlin por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros em percursos do Gremlin. |
|
Número de solicitações para o mecanismo Gremlin. |
|
Número de WebSocket conexões bem-sucedidas com o endpoint Gremlin por segundo. |
|
Número de erros do WebSocket cliente no endpoint Gremlin por segundo. |
|
Número de erros WebSocket do servidor no endpoint do Gremlin por segundo. |
|
Número de WebSocket conexões potenciais atualmente disponíveis. |
|
Número de respostas HTTP 100 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de respostas HTTP 101 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de respostas HTTP 1xx para o endpoint por segundo. |
|
Número de respostas HTTP 200 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de respostas HTTP 2xx para o endpoint por segundo. |
|
Número de erros HTTP 400 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 403 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 405 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 413 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 429 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 4xx para o endpoint por segundo. |
|
Número de erros HTTP 500 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 501 para o endpoint por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 5xx para o endpoint por segundo. |
|
Número de erros de solicitações do carregador. |
|
Número de solicitações do carregador. |
|
Número de respostas HTTP 1xx para o endpoint do SPARQL por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de respostas HTTP 2xx para o endpoint do SPARQL por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 4xx para o endpoint do SPARQL por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros HTTP 5xx para o endpoint do SPARQL por segundo. Recomendamos o uso da nova métrica combinada |
|
Número de erros nas consultas do SPARQL. |
|
Número de solicitações para o mecanismo do SPARQL. |
|
Número de erros do endpoint de status. |
|
Número de solicitações para o endpoint de status. |
