As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Visão geral de como usar o atributo Neptune ML
O recurso do Neptune ML no Amazon Neptune fornece um fluxo de trabalho simplificado para aproveitar modelos de machine learning em um banco de dados de grafos. O processo envolve várias etapas essenciais: exportar dados do Neptune para o formato CSV, pré-processar os dados para prepará-los para o treinamento de modelo, treinar o modelo de machine learning usando o Amazon SageMaker AI, criar um endpoint de inferência para fornecer previsões e, em seguida, consultar o modelo diretamente das consultas do Gremlin. A bancada de trabalho do Neptune fornece comandos mágicos de linha e célula convenientes para ajudar a gerenciar e automatizar essas etapas. Ao integrar os recursos de machine learning diretamente ao banco de dados de grafos, o Neptune ML permite que os usuários obtenham informações valiosas e façam previsões usando os ricos dados relacionais armazenados no grafo do Neptune.
Iniciar o fluxo de trabalho para usar o Neptune ML
O uso do atributo Neptune ML no Amazon Neptune geralmente envolve estas cinco etapas para começar:
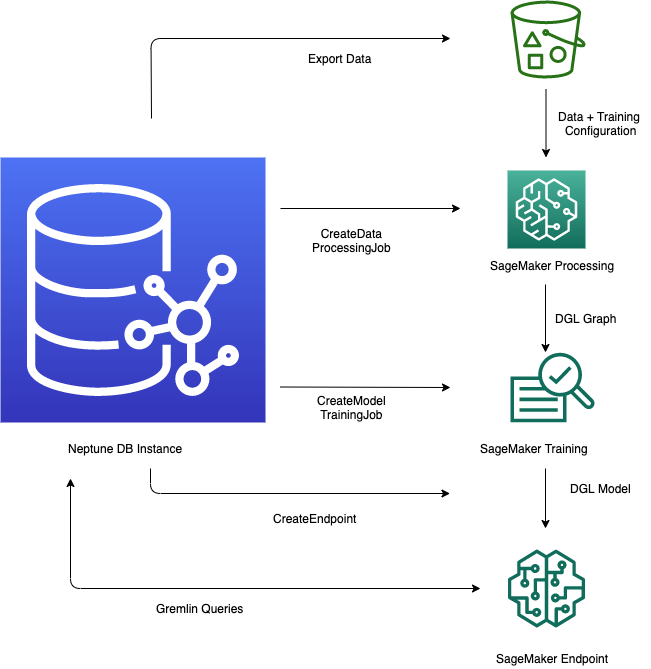
-
Exportação e configuração de dados: a etapa de exportação de dados usa o serviço Neptune-Export ou a ferramenta de linha de comando
neptune-exportpara exportar dados do Neptune para o Amazon Simple Storage Service (Amazon S3) em formato CSV. Um arquivo de configuração chamadotraining-data-configuration.jsoné gerado automaticamente ao mesmo tempo, o que especifica como os dados exportados podem ser carregados em um grafo treinável. -
Pré-processamento de dados: nessa etapa, o conjunto de dados exportado é pré-processado usando técnicas padrão para prepará-lo para o treinamento de modelos. A normalização de atributos pode ser realizada para dados numéricos e os atributos de texto podem ser codificados usando
word2vec. No final dessa etapa, um grafo DGL (biblioteca Deep Graph) é gerado a partir do conjunto de dados exportado para uso na etapa de treinamento de modelos.Essa etapa é implementada usando um trabalho de processamento do SageMaker AI na conta, e os dados resultantes são armazenados em um local do Amazon S3 especificado.
-
Treinamento de modelos: a etapa de treinamento de modelos treina o modelo de machine learning que será usado para previsões.
O treinamento de modelos é realizado em duas etapas:
A primeira etapa usa uma tarefa de processamento do SageMaker AI para gerar um conjunto de configurações da estratégia de treinamento de modelos que especifique o tipo de modelo e intervalos de hiperparâmetros que serão usados para o treinamento de modelos.
Depois, a segunda fase usa uma tarefa de ajuste de modelos do SageMaker AI para testar diferentes configurações de hiperparâmetros e selecionar a tarefa de treinamento que produziu o modelo com melhor desempenho. O trabalho de ajuste executa um número pré-especificado de testes de trabalho de treinamento de modelos nos dados processados. No final dessa etapa, os parâmetros do modelo treinado do melhor trabalho de treinamento são usados para gerar artefatos de modelo para inferência.
-
Criar um endpoint de inferência no Amazon SageMaker AI: o endpoint de inferência é uma instância de endpoint do SageMaker AI que é lançada com os artefatos do modelo produzidos pela melhor tarefa de treinamento. Cada modelo é vinculado a um único endpoint. O endpoint pode aceitar solicitações recebidas do banco de dados de grafos e exibir as previsões do modelo para entradas nas solicitações. Depois de criar o endpoint, ele permanece ativo até que você o exclua.
Consulta ao modelo de machine learning usando o Gremlin: é possível usar extensões à linguagem de consulta Gremlin para consultar previsões por meio do endpoint de inferência.
nota
A bancada de trabalho do Neptune contém uma magia de linha e uma magia de célula que podem proporcionar uma grande economia de tempo no gerenciamento dessas etapas, ou seja:
