As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Amazon Transcribe suporta saída WebVTT (*.vtt) SubRip e (*.srt) para uso como legendas de vídeo. Você pode selecionar um ou ambos os tipos de arquivo ao configurar seu trabalho de transcrição de vídeo em lote. Ao usar o recurso de legenda, seus arquivos de legenda selecionados e um arquivo de transcrição normal (contendo informações adicionais) são produzidos. Os arquivos de legenda e transcrição são enviados para o mesmo destino.
As legendas são exibidas ao mesmo tempo em que o texto é falado e permanecem visíveis até que haja uma pausa natural ou o locutor pare de falar. Observe que, se você habilitar legendas na solicitação de transcrição e o áudio não contiver fala, não será criado um arquivo de legenda.
Importante
Amazon Transcribe usa um índice inicial padrão de 0 para saída de legenda, que difere do valor mais amplamente usado de1. Se você precisar de um índice inicial de1, você pode especificar isso na AWS Management Console ou em sua solicitação de API usando o OutputStartIndexparâmetro.
Usar o índice inicial incorreto pode resultar em erros de compatibilidade com outros serviços, portanto, verifique de qual índice inicial você precisa antes de criar legendas. Se você não tiver certeza de qual valor usar, recomendamos escolher 1. Consulte Subtitles para obter mais informações.
Recursos compatíveis com legendas:
-
Edição de conteúdo: qualquer conteúdo editado é refletido como “
PII” nos arquivos de saída da legenda e da transcrição normal. O áudio não é alterado. -
Filtros de vocabulário: os arquivos de legenda são gerados com base no arquivo de transcrição; portanto, todas as palavras filtradas na saída da transcrição padrão também são filtradas nas legendas. O conteúdo filtrado é exibido como espaço em branco ou
***nos arquivos de transcrição e legenda. O áudio não é alterado. -
Diarização do locutor: se houver vários locutores em determinado segmento da legenda, serão usados traços para distinguir cada um deles. Isso se aplica tanto ao WebVTT quanto aos formatos; por SubRip exemplo:
-- Texto falado pela pessoa 1
-- Texto falado pela pessoa 2
Os arquivos de legenda são armazenados no mesmo Amazon S3 local da saída da transcrição.
Para ver um tutorial em vídeo sobre a criação de legendas, consulte:
Gerar arquivos de legenda
Você pode criar arquivos de legenda usando o AWS Management Console, AWS CLI, ou AWS SDKs; veja os exemplos a seguir:
-
Faça login no AWS Management Console
. -
No painel de navegação, escolha Tarefas de transcrição e selecione Criar tarefa (no canto superior direito). Isso abre a página Especificar os detalhes da tarefa. As opções de legenda estão localizadas no painel Dados de saída.
-
Selecione os formatos que você deseja para os arquivos de legenda e escolha um valor para o índice inicial. Observe que o Amazon Transcribe padrão é
0, mas1é mais amplamente usado. Se você não tiver certeza de qual valor usar, recomendamos escolher1, pois isso pode melhorar a compatibilidade com outros serviços.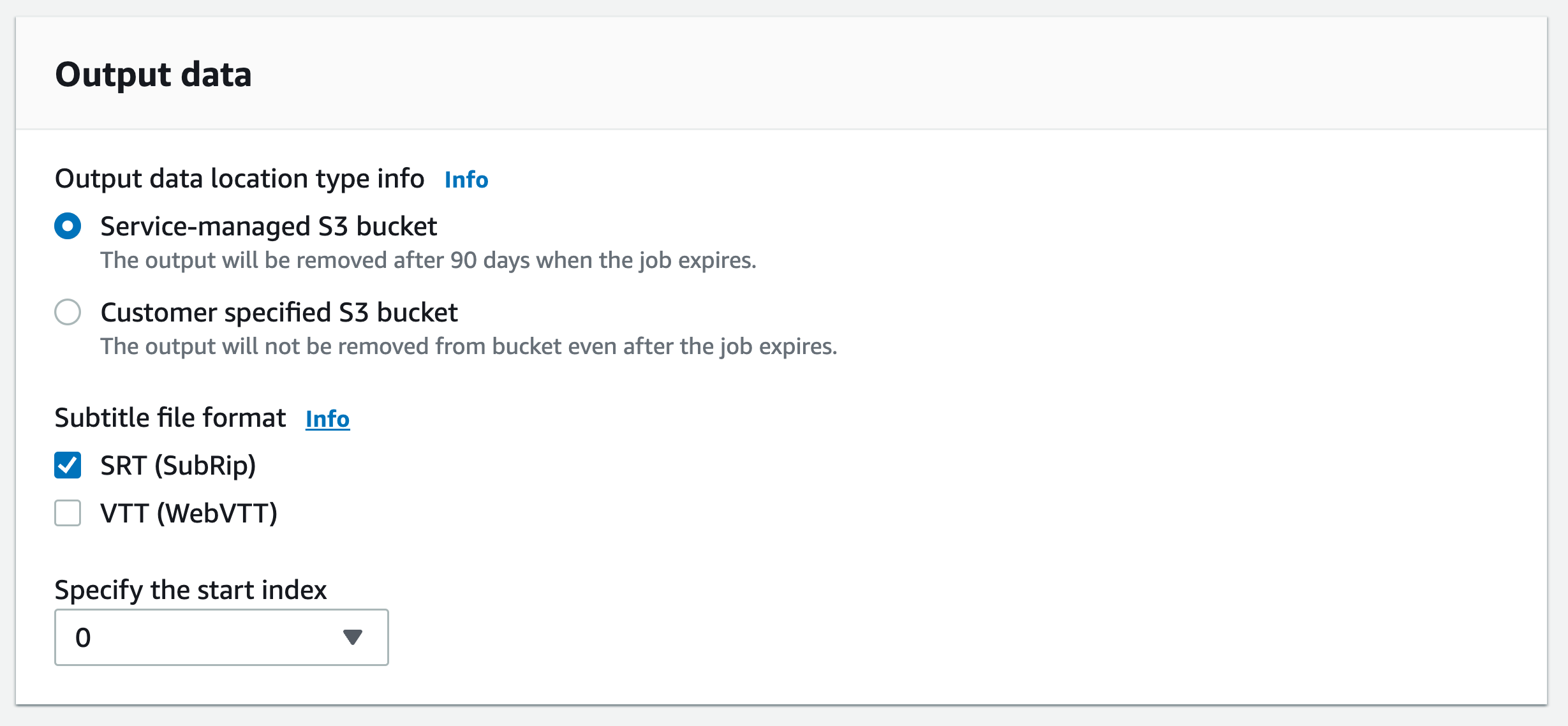
-
Preencha os outros campos que deseja incluir na página Especificar os detalhes da tarefa e selecione Próximo. Isso leva você à página Configurar tarefa: opcional.
-
Selecione Criar tarefa para executar a tarefa de transcrição.
-
Faça login no AWS Management Console
. -
No painel de navegação, escolha Tarefas de transcrição e selecione Criar tarefa (no canto superior direito). Isso abre a página Especificar os detalhes da tarefa. As opções de legenda estão localizadas no painel Dados de saída.
-
Selecione os formatos que você deseja para os arquivos de legenda e escolha um valor para o índice inicial. Observe que o Amazon Transcribe padrão é
0, mas1é mais amplamente usado. Se você não tiver certeza de qual valor usar, recomendamos escolher1, pois isso pode melhorar a compatibilidade com outros serviços.
-
Preencha os outros campos que deseja incluir na página Especificar os detalhes da tarefa e selecione Próximo. Isso leva você à página Configurar tarefa: opcional.
-
Selecione Criar tarefa para executar a tarefa de transcrição.
Este exemplo usa o start-transcription-jobSubtitles parâmetro. Para ter mais informações, consulte StartTranscriptionJob e Subtitles.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --subtitles Formats=vtt,srt,OutputStartIndex=1
Aqui está outro exemplo usando o start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-subtitle-job.json
O arquivo my-first-subtitle-job.json contém o seguinte corpo da solicitação.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Subtitles": {
"Formats": [
"vtt","srt"
],
"OutputStartIndex": 1
}
}Este exemplo usa o AWS SDK para Python (Boto3) para adicionar legendas usando o Subtitles argumento do método start_transcription_jobStartTranscriptionJob e Subtitles.
Para obter exemplos adicionais de uso do AWS SDKs, incluindo exemplos específicos de recursos, cenários e entre serviços, consulte o capítulo. Exemplos de código para o Amazon Transcribe usando AWS SDKs
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Subtitles = {
'Formats': [
'vtt','srt'
],
'OutputStartIndex': 1
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)