对于表的任何项目,仅当项目中存在索引排序键值时,DynamoDB 才会写入相应索引条目。如果排序键没有出现在每个表项目中,或者如果索引分区键不存在于该项目中,则这种索引称为稀疏索引。
稀疏索引对于查询表的小子集非常有用。例如,假设有一个表存储所有客户订单,具有以下键属性:
-
分区键:
CustomerId -
排序键:
OrderId
要跟踪未结订单,可以在尚未发货的订单项目中插入一个名为 isOpen 的属性。订单发货后,可以删除该属性。如果对 CustomerId(分区键)和 isOpen(排序键)创建索引,则仅显示定义了 isOpen 的订单。如果数以千计的订单中只有少量订单处于未结状态,查询未结订单索引比扫描整个表更快,成本更低。
可以使用值在索引中生成有用排序顺序的属性,代替 isOpen 属性。例如,可以使用设置为下每个订单的日期的 OrderOpenDate 属性,订单完成后删除。这样查询稀疏索引时,返回的项目将按下每个订单的日期排序。
DynamoDB 中稀疏索引的示例
全局二级索引默认属于稀疏型。创建全局二级索引时,指定一个分区键,可以选择指定一个排序键。索引仅显示基表中包含这些属性的项目。
将全局二级索引设计为稀疏索引,可以配置低于基表的写入吞吐量,同时仍实现出色的性能。
例如,游戏应用程序可能跟踪每个用户的所有得分,但通常只需查询一些高分。下面的设计高效处理这种情况:
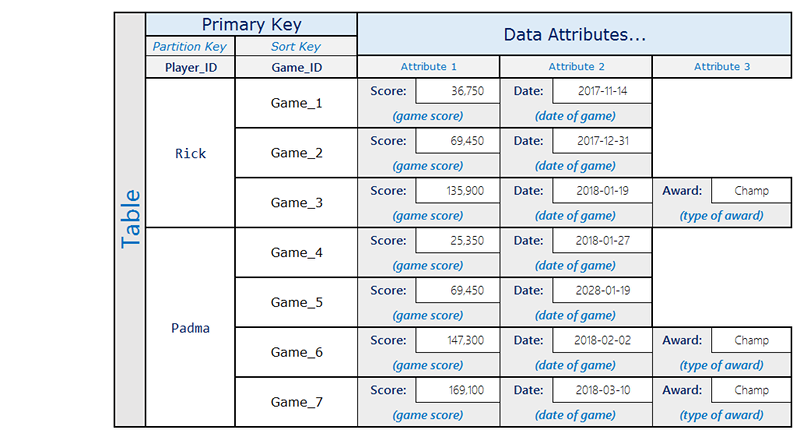
Rick 玩三款游戏,在其中一款游戏中达到 Champ 状态。Padma 玩四款游戏,在其中两款游戏中达到 Champ 状态。请注意,只有用户达到奖励的项目存在 Award 属性。关联全局二级索引如下所示:
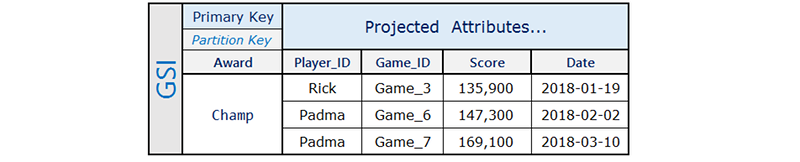
全局二级索引仅包含经常查询的高分,这是基表的一个小子集。
