Amazon DynamoDB 的一般设计准则建议尽可能少使用表格。对于大多数应用程序,只需单个表即可。但是,对于时间序列数据,通常最好每个时间段为每个应用程序使用一个表。
时间序列数据的设计模式
考虑一个需要跟踪大量活动的典型时间序列场景。写入访问模式是记录的所有事件都有当天日期。读取访问模式是当天事件读取频率最高,前一天事件的读取频率小很多,更早事件的读取频率几乎为零。一种处理方式是将当前日期和时间加入主键。
下面的设计模式通常可以高效应对这种场景:
-
每个时间段创建一个表,预置所需的读取和写入容量以及所需的索引。
-
每个时间段结束前,为下一个时间段预生成表。当前时间段结束时,将事件流量定向至新表。可以为这些表分配名称,指定这些表记录的时间段。
-
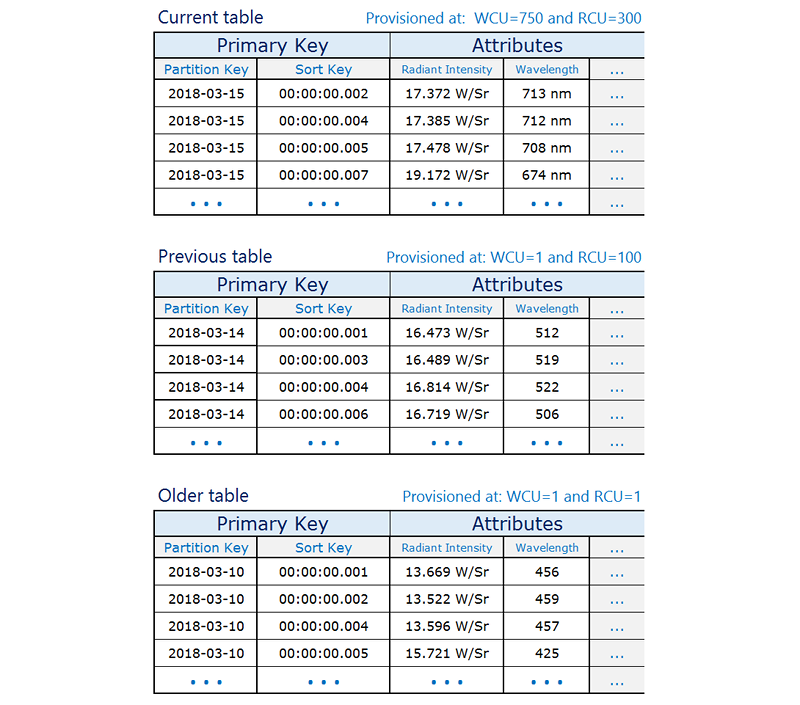
只要不再写入表,就将预置的写入容量降至较低值(例如 1 WCU),预置适当的读取容量。随着时间推移,减少早期表的预置读取容量。可以选择存档或删除几乎或完全不需要其内容的表。
这种做法的目的是将所需的资源分配给承受最高流量的当前时间段,同时降低使用不活跃的旧表的预置资源,从而节省成本。根据业务需求,可能考虑写入分片,将流量均匀地分布到逻辑分区键。有关更多信息,请参阅 在 DynamoDB 表中使用写入分片来均匀分配工作负载。
时间序列表示例
下面是一个时间序列数据示例,当前表预置较高读取/写入容量,较早的表因为访问不频繁,将降低配置。