当您需要在特定时间范围内查询近期数据时,对于大多数读取操作,DynamoDB 要求提供分区键,这可能会带来挑战。为了解决这种情况,您可以将写入分片和全局二级索引(GSI)结合使用,来实施高效的查询模式。
通过这种方法,您能够高效地检索和分析时间敏感型数据,而无需执行全表扫描,全表扫描会占用大量资源且成本高昂。通过战略性的表结构和索引设计,您可以创建灵活的解决方案,支持基于时间的数据检索,同时保持出色的性能。
模式设计
使用 DynamoDB 时,为了克服时间敏感型数据检索带来的挑战,您可以实施一种精巧的模式,将写入分片和全局二级索引结合使用,从而实现对近期数据时段灵活且高效的查询。
表的结构
分区键(PK):“Username”
GSI 的结构
GSI 分区键(PK_GSI):“ShardNumber#”
GSI 排序键(SK_GSI):ISO 8601 时间戳(例如,“2030-04-01T12:00:00Z”)
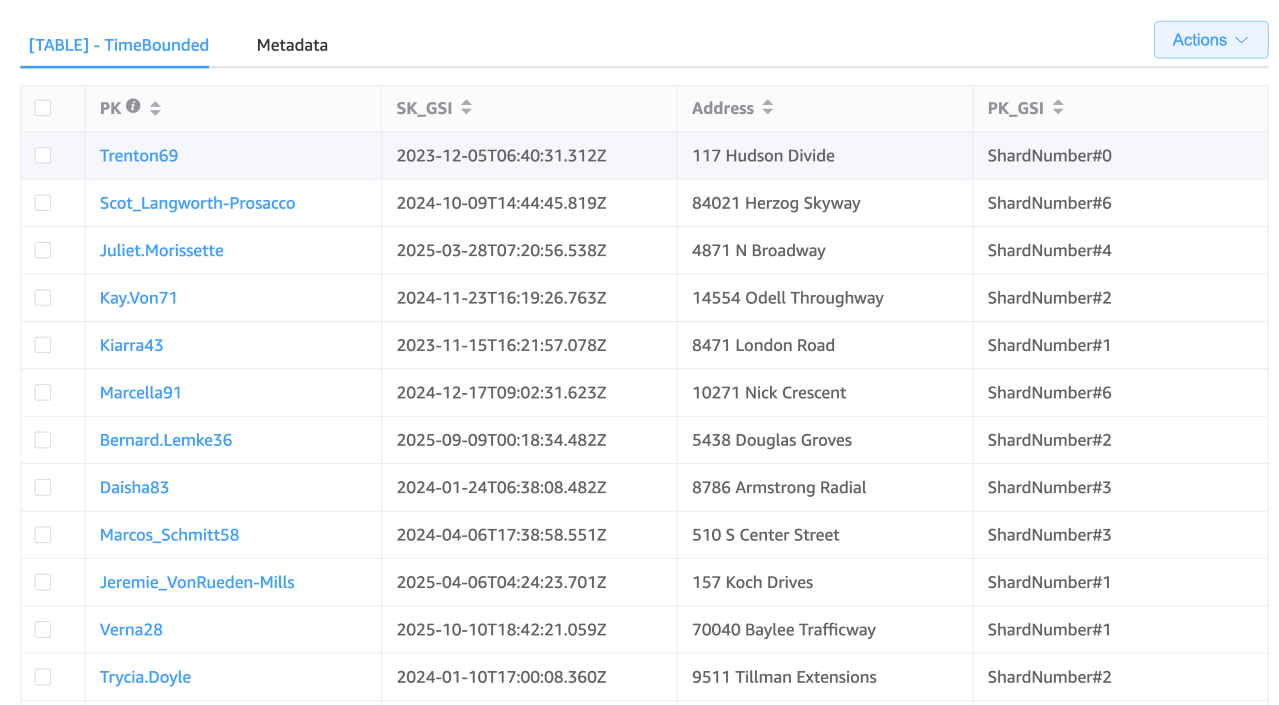
分片策略
假设您决定使用 10 个分片,则分片编号的范围可以是从 0 到 9。在记录活动时,您需要计算分片编号(例如,对用户 ID 上使用哈希函数,然后获取分片编号的模数),后将其添加到 GSI 分区键的前面。此方法将条目分布在不同的分片上,降低了过热分区的风险。
查询分片 GSI
在 DynamoDB 表中,要对所有分片查询特定时间范围内的项目,而其中的数据使用多个分区键进行分片,那么就需要采用与查询单个分区不同的方法。由于 DynamoDB 查询限制为一次使用一个分区键,因此您无法通过单个查询操作直接对多个分片进行查询。但是,您可以使用应用程序级逻辑,通过执行多个查询,每个查询针对一个特定的分片,然后汇总结果,这样就能得到所需的结果。以下过程说明如何执行此操作。
查询和聚合分片
确定分片策略中使用的分片编号范围。例如,如果您有 10 个分片,则分片编号的范围是 0 到 9。
对于每个分片,构造并执行一个查询,用于提取所需时间范围内的项目。查询可以并行执行来提高效率。在这些查询中,使用带有分片编号的分区键,以及带有时间范围的排序键。以下是针对单个分片的示例查询:
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'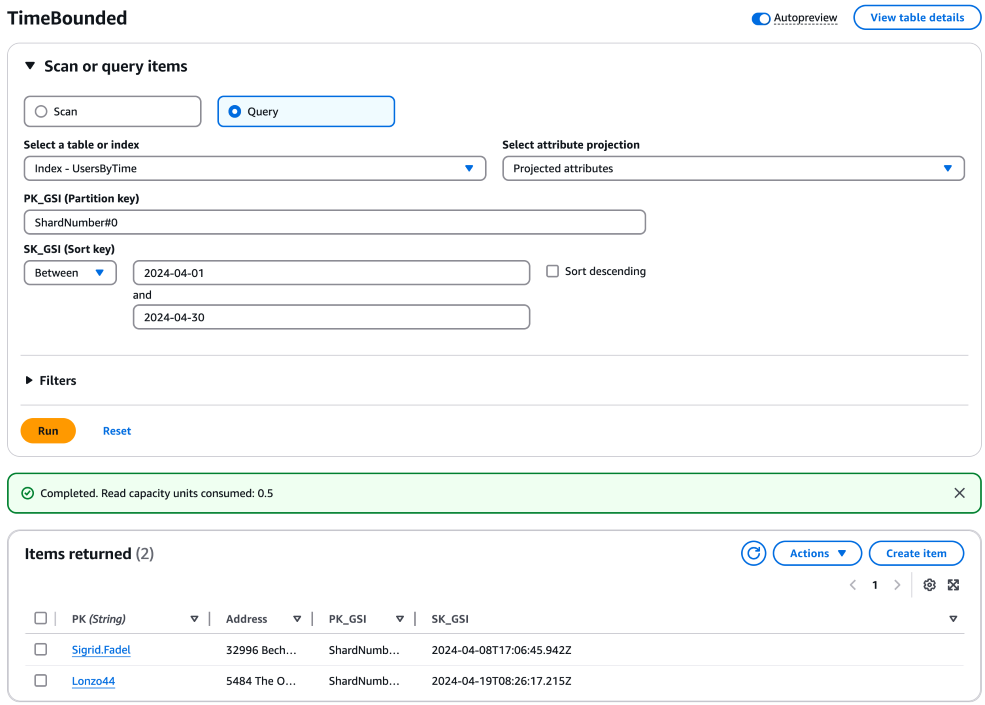
您可以为每个分片复制此查询,并相应调整分区键(例如,“ShardNumber#1”、“ShardNumber#2”、…“ShardNumber#9”)。
所有查询完成后,汇总各个查询的结果。在应用程序代码中执行此聚合,将结果合并到一个数据集中,该数据集就代表了指定时间范围内所有分片中的项目。
并行查询执行注意事项:
每个查询都会消耗表或索引的读取容量。如果您使用预置吞吐量,请确保表已经预置了足够的容量用于处理突发的并行查询。如果您使用的是按需容量,请注意潜在的成本影响。
代码示例
在 DynamoDB 中,要使用 Python 跨分片执行并行查询,您可以使用 boto3 库,这是适用于 Python 的 Amazon Web Services SDK。此示例假设您已安装 boto3 并配置了相应的 AWS 凭证。
以下 Python 代码演示如何针对给定的时间范围,跨多个分片执行并行查询。代码中使用 concurrent.futures 并行执行查询,与顺序执行相比,缩短了总体执行时间。
import boto3
from concurrent.futures import ThreadPoolExecutor, as_completed
# Initialize a DynamoDB client
dynamodb = boto3.client('dynamodb')
# Define your table name and the total number of shards
table_name = 'YourTableName'
total_shards = 10 # Example: 10 shards numbered 0 to 9
time_start = "2030-03-15T09:00:00Z"
time_end = "2030-03-15T10:00:00Z"
def query_shard(shard_number):
"""
Query items in a specific shard for the given time range.
"""
response = dynamodb.query(
TableName=table_name,
IndexName='YourGSIName', # Replace with your GSI name
KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end",
ExpressionAttributeValues={
":pk_val": {"S": f"ShardNumber#{shard_number}"},
":date_start": {"S": time_start},
":date_end": {"S": time_end},
}
)
return response['Items']
# Use ThreadPoolExecutor to query across shards in parallel
with ThreadPoolExecutor(max_workers=total_shards) as executor:
# Submit a future for each shard query
futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)}
# Collect and aggregate results from all shards
all_items = []
for future in as_completed(futures):
shard_number = futures[future]
try:
shard_items = future.result()
all_items.extend(shard_items)
print(f"Shard {shard_number} returned {len(shard_items)} items")
except Exception as exc:
print(f"Shard {shard_number} generated an exception: {exc}")
# Process the aggregated results (e.g., sorting, filtering) as needed
# For example, simply printing the count of all retrieved items
print(f"Total items retrieved from all shards: {len(all_items)}")在运行此代码之前,请务必使用您的 DynamoDB 设置中的实际表和 GSI 名称替换 YourTableName 和 YourGSIName。此外,根据您的具体要求调整 total_shards、time_start 和 time_end 变量。
此脚本在每个分片中,查询指定时间范围内的项目并汇总结果。
