将 DynamoDB 与 Amazon Managed Streaming for Apache Kafka 集成
借助 Amazon Managed Streaming for Apache Kafka (Amazon MSK),您可以通过完全托管式、高可用性 Apache Kafka 服务,轻松、实时地摄取和处理流数据。
Apache Kafka
由于这些功能,Apache Kafka 经常用于构建实时流数据管道。数据管道 可靠地处理数据并将数据从一个系统移动到另一个系统,通过促进使用多个数据库(每个数据库支持不同的用例),数据管道可以成为采用专用数据库策略的重要组成部分。
Amazon DynamoDB 是这些数据管道中的常见目标,用于支持使用键值或文档数据模型的应用程序,这些应用程序需要无限的可扩展性和稳定的个位数毫秒性能。
工作原理
Amazon MSK 和 DynamoDB 之间的集成使用 Lambda 函数,以使用来自 Amazon MSK 的记录并将其写入 DynamoDB。
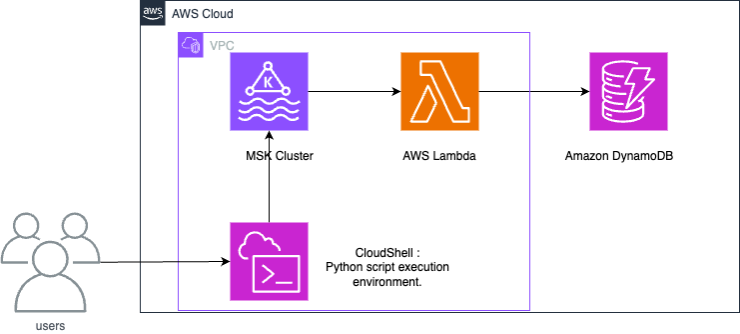
Lambda 在内部轮询来自 Amazon MSK 的新消息,然后同步调用目标 Lambda 函数。Lambda 函数的事件有效载荷包含来自 Amazon MSK 的批量消息。为了实现 Amazon MSK 和 DynamoDB 之间的集成,Lambda 函数会将这些消息写入 DynamoDB。
设置 Amazon MSK 和 DynamoDB 之间的集成
注意
可以在以下 GitHub repository
以下步骤显示了如何在 Amazon MSK 和 Amazon DynamoDB 之间设置示例集成。该示例表示物联网(IoT)设备生成并摄取到 Amazon MSK 中的数据。当数据摄取到 Amazon MSK 时,可以将其和与 Apache Kafka 兼容的分析服务或第三方工具集成,从而实现各种分析用例。集成 DynamoDB 还可以提供对单个设备记录的键值查询。
此示例将演示 Python 脚本如何将 IoT 传感器数据写入 Amazon MSK。然后,Lambda 函数将带有分区键“deviceid”的项目写入 DynamoDB。
所提供的 CloudFormation 模板将创建以下资源:Amazon S3 存储桶、Amazon VPC、Amazon MSK 集群和用于测试数据操作的 AWS CloudShell。
要生成测试数据,请创建一个 Amazon MSK 主题,然后创建一个 DynamoDB 表。可以使用管理控制台中的会话管理器登录到 CloudShell 的操作系统并运行 Python 脚本。
运行 CloudFormation 模板后,可以通过执行以下操作来完成此架构的构建。
-
运行 CloudFormation 模板
S3bucket.yaml来创建 S3 存储桶。对于任何后续脚本或操作,请在同一个区域中运行它们。输入ForMSKTestS3作为 CloudFormation 堆栈名称。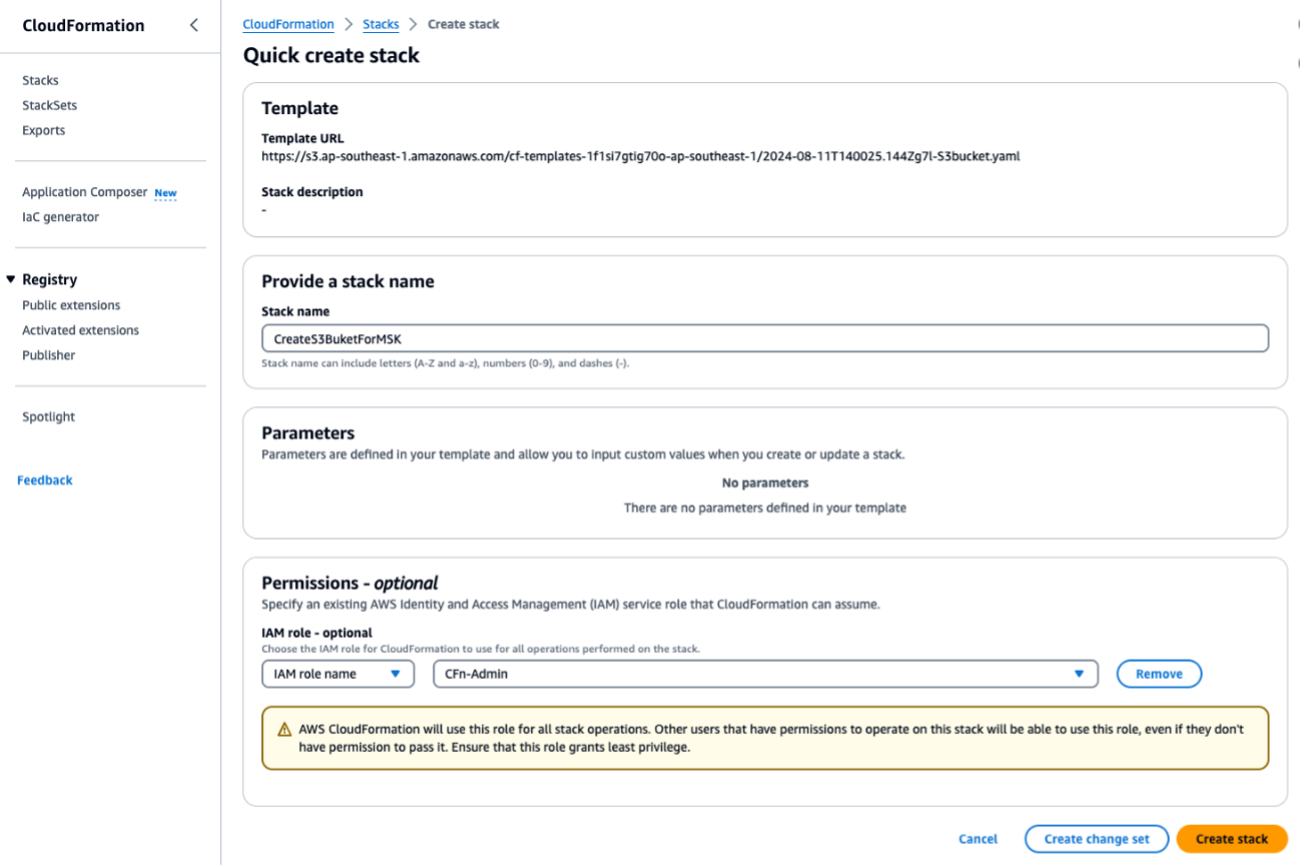
完成此过程后,记下在输出 下输出的 S3 存储桶名称。您将在步骤 3 中需要此名称。

-
将下载的 ZIP 文件
fromMSK.zip上传到您刚创建的 S3 存储桶。
-
运行 CloudFormation 模板
VPC.yaml以创建 VPC、Amazon MSK 集群和 Lambda 函数。在参数输入屏幕上,在需要 S3 存储桶的位置输入您在步骤 1 中创建的 S3 存储桶名称。将 CloudFormation 堆栈名称设置为ForMSKTestVPC。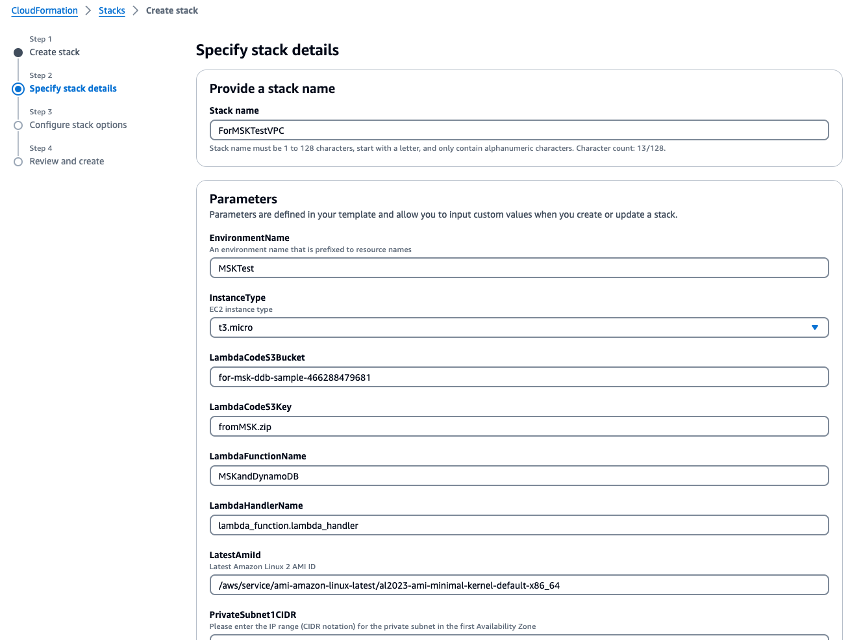
-
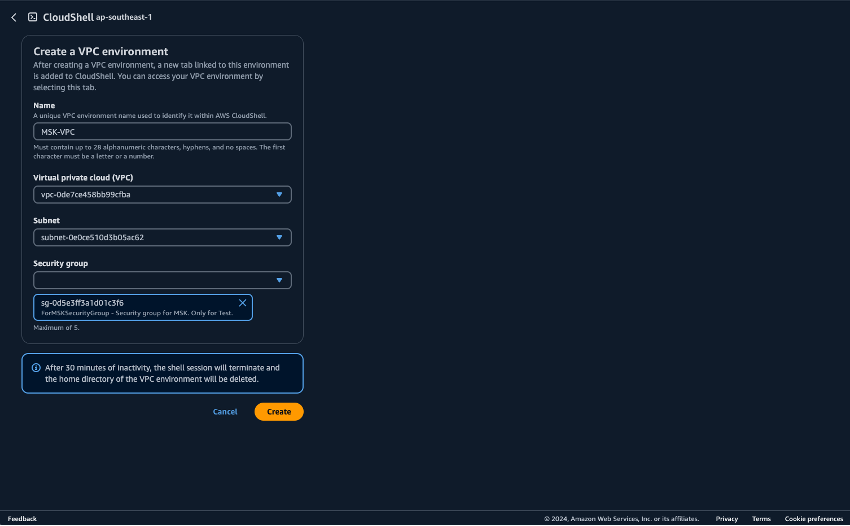
为在 CloudShell 中运行 Python 脚本准备好环境。可以在 AWS Management Console上使用 CloudShell。有关使用 CloudShell 的更多信息,请参阅开始使用 AWS CloudShell。启动 CloudShell 后,创建一个属于您刚创建的 VPC 的 CloudShell,以便连接到 Amazon MSK 集群。在私有子网中创建 CloudShell。填写以下字段:
-
名称 - 可以设置为任何名称。MSK-VPC 就是一个例子
-
VPC - 选择 MSKTest
-
子网 - 选择 MSKTest 私有子网(AZ1)
-
安全组 - 选择 ForMSKSecurityGroup

一旦属于私有子网的 CloudShell 启动,就运行以下命令:
pip install boto3 kafka-python aws-msk-iam-sasl-signer-python -
-
从 S3 存储桶下载 Python 脚本。
aws s3 cp s3://[YOUR-BUCKET-NAME]/pythonScripts.zip ./ unzip pythonScripts.zip -
检查管理控制台,并在 Python 脚本中为代理 URL 和区域值设置环境变量。在管理控制台中检查 Amazon MSK 集群代理端点。

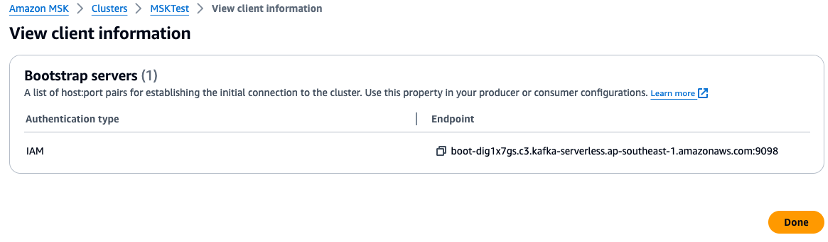
-
在 CloudShell 上设置环境变量。如果您使用的是美国西部(俄勒冈州):
export AWS_REGION="us-west-2" export MSK_BROKER="boot-YOURMSKCLUSTER.c3.kafka-serverless.ap-southeast-1.amazonaws.com:9098" -
运行以下 Python 脚本。
创建 Amazon MSK 主题:
python ./createTopic.py创建 DynamoDB 表:
python ./createTable.py将测试数据写入 Amazon MSK 主题:
python ./kafkaDataGen.py -
检查已创建的 Amazon MSK、Lambda 和 DynamoDB 资源的 CloudWatch 指标,并使用 DynamoDB Data Explorer 来验证存储在
device_status表中的数据,以确保所有进程都正常运行。如果每个进程都正常运行而没有错误,则可以检查从 CloudShell 写入 Amazon MSK 的测试数据是否也写入 DynamoDB。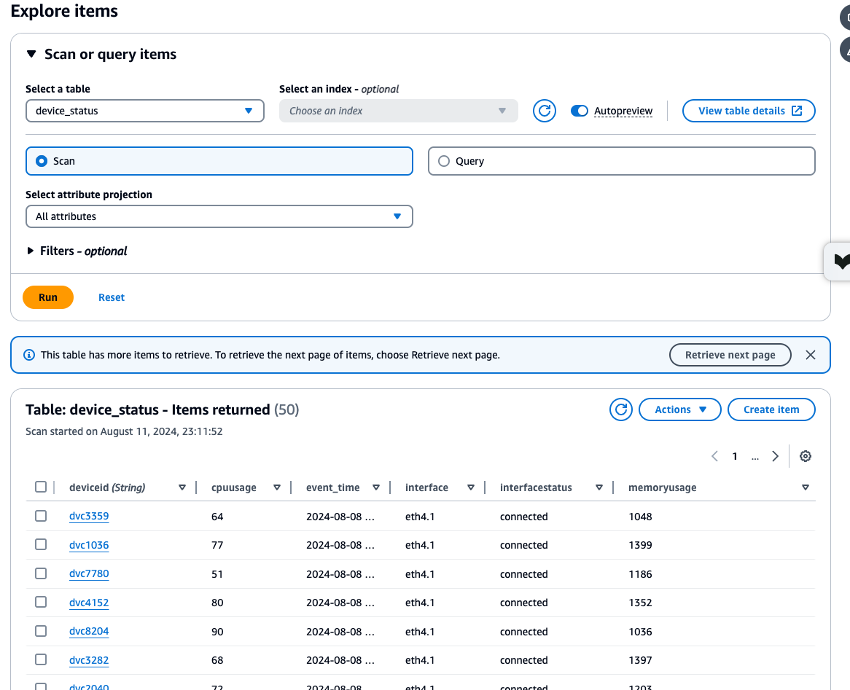
-
完成此示例后,请删除在本教程中创建的资源。删除两个 CloudFormation 堆栈:
ForMSKTestS3和ForMSKTestVPC。如果堆栈删除操作成功完成,则所有资源都将被删除。
后续步骤
注意
如果您在遵循此示例时创建了资源,请记得将其删除,以免产生任何意外费用。
该集成确定了一种架构,该架构将 Amazon MSK 和 DynamoDB 相关联,使流数据能够支持 OLTP 工作负载。在此处,通过关联 DynamoDB 与 OpenSearch 服务,可以实现更复杂的搜索。考虑与 EventBridge 集成,以满足更复杂的事件驱动型需求,并考虑与 Amazon Managed Service for Apache Flink 等扩展集成,以满足对更高吞吐量和更低延迟的要求。
