Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Sprecherpartitionierung (Diarisierung)
Mit der Lautsprecher-Diarisierung können Sie in Ihrer Transkriptionsausgabe zwischen verschiedenen Sprechern unterscheiden. Amazon Transcribe kann zwischen maximal 30 einzelnen Sprechern unterscheiden und kennzeichnet den Text jedes einzelnen Sprechers mit einem eindeutigen Wert (spk_0durchspk_29).
Zusätzlich zu den Standard-Transkriptabschnitten (transcripts und items) enthalten Anfragen mit aktivierter Sprecherpartitionierung einen Abschnitt speaker_labels. Dieser Abschnitt ist nach Sprechern gruppiert und enthält Informationen zu jeder Äußerung, einschließlich Sprecherbezeichnung und Zeitstempel.
"speaker_labels": { "channel_label": "ch_0", "speakers": 2, "segments": [ { "start_time": "4.87", "speaker_label": "spk_0", "end_time": "6.88", "items": [ { "start_time": "4.87", "speaker_label": "spk_0", "end_time": "5.02" },...{ "start_time": "8.49", "speaker_label": "spk_1", "end_time": "9.24", "items": [ { "start_time": "8.49", "speaker_label": "spk_1", "end_time": "8.88" },
Ein vollständiges Beispieltranskript mit Sprecherpartitionierung (für zwei Sprecher) finden Sie unter Beispiel für die Diarisierungsausgabe (Batch).
Aufteilung der Sprecher in einer Batch-Transkription
Zur Sprecherpartitionierung in einer Batch-Transkription siehe die folgenden Beispiele:
-
Melden Sie sich an der AWS Management Console
an. -
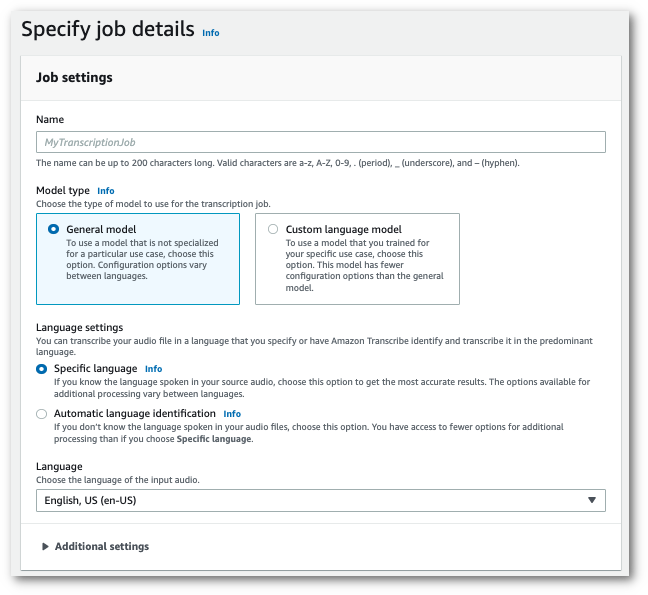
Wählen Sie im Navigationsbereich Transkriptionsaufträge und dann Auftrag erstellen (oben rechts). Dies öffnet die Seite Auftragsdetails angeben.
-
Füllen Sie alle Felder aus, die Sie auf der Seite Auftragsdetails angeben möchten, und wählen Sie dann Weiter. Dadurch gelangen Sie zur Seite Auftrag konfigurieren – optional.
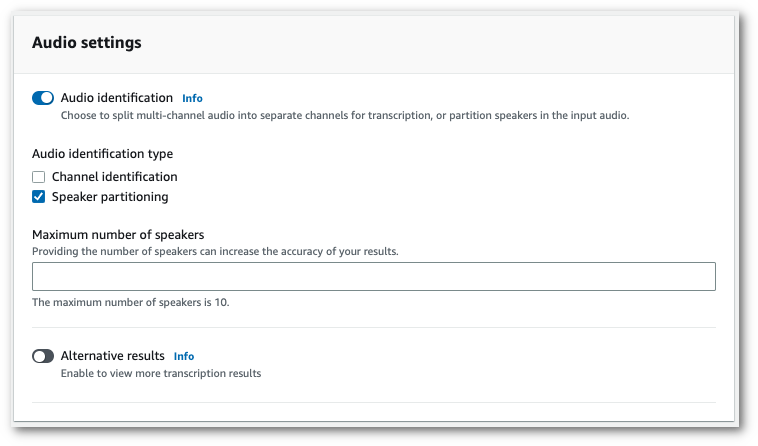
Um die Lautsprecherpartitionierung zu aktivieren, wählen Sie in den Audioeinstellungen die Option Audioidentifikation. Wählen Sie dann Lautsprecherpartitionierung und geben Sie die Anzahl der Lautsprecher an.
-
Wählen Sie Auftrag erstellen, um Ihren Transkriptionsauftrag auszuführen.
In diesem Beispiel wird start-Transkription-jobStartTranscriptionJob.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ShowSpeakerLabels=true,MaxSpeakerLabels=3
Hier ein weiteres Beispiel mit dem Befehl start-Transkription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-transcription-job.json
Die Datei my-first-Transkription-job.json enthält den folgenden Anforderungstext.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ShowSpeakerLabels": 'TRUE', "MaxSpeakerLabels":3}
In diesem Beispiel werden Kanäle mithilfe der AWS SDK für Python (Boto3) Methode start_transcription_job
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'ShowSpeakerLabels': True, 'MaxSpeakerLabels':3} ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Partitionierung der Sprecher in einer Streaming-Transkription
Um die Sprecher in einer Streaming-Transkription zu trennen, sehen Sie sich die folgenden Beispiele an:
-
Melden Sie sich an der AWS Management Console
an. -
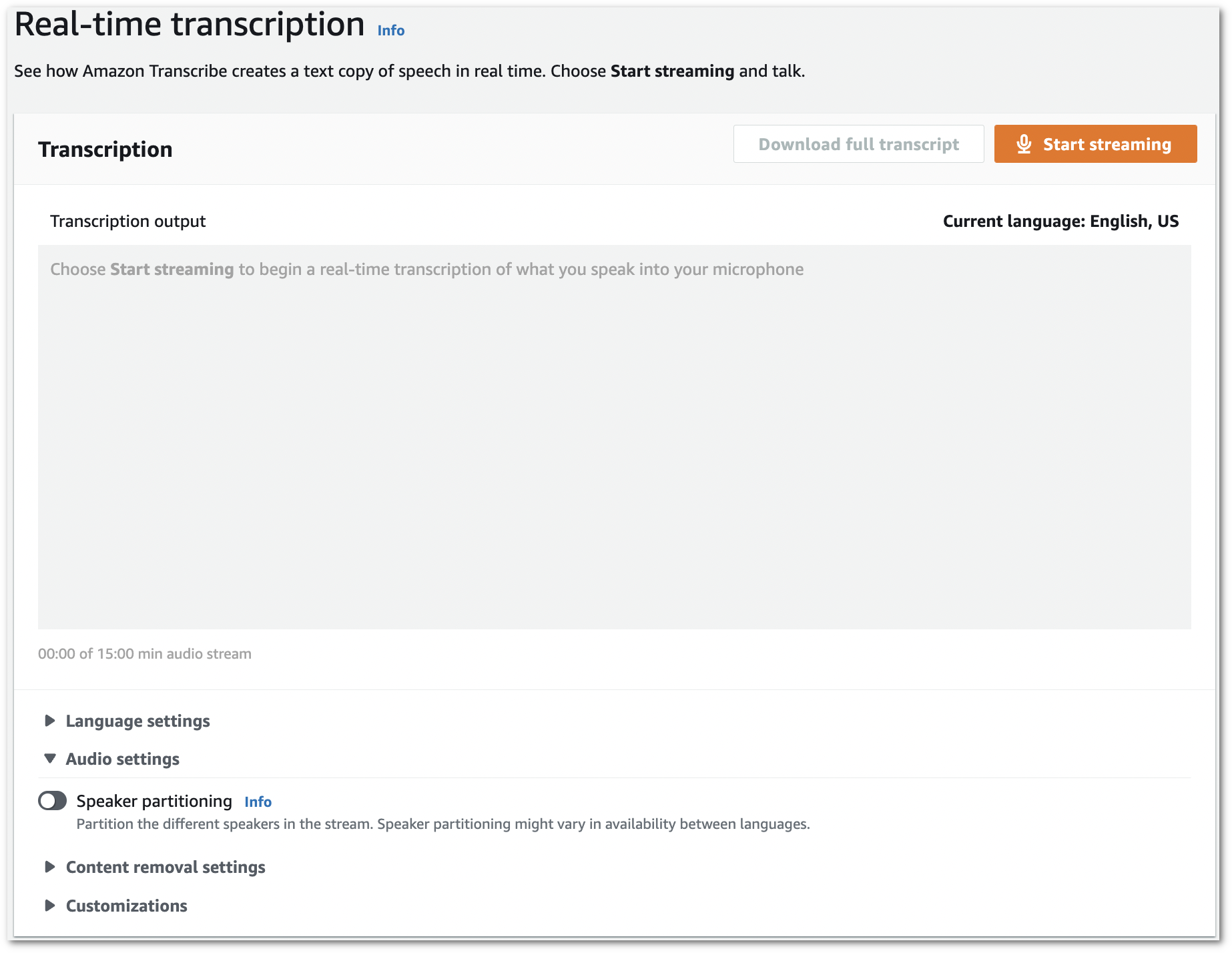
Wählen Sie im Navigationsbereich Real-time Transkription aus. Blättern Sie nach unten zu den Audioeinstellungen und erweitern Sie dieses Feld, falls es minimiert ist.
-
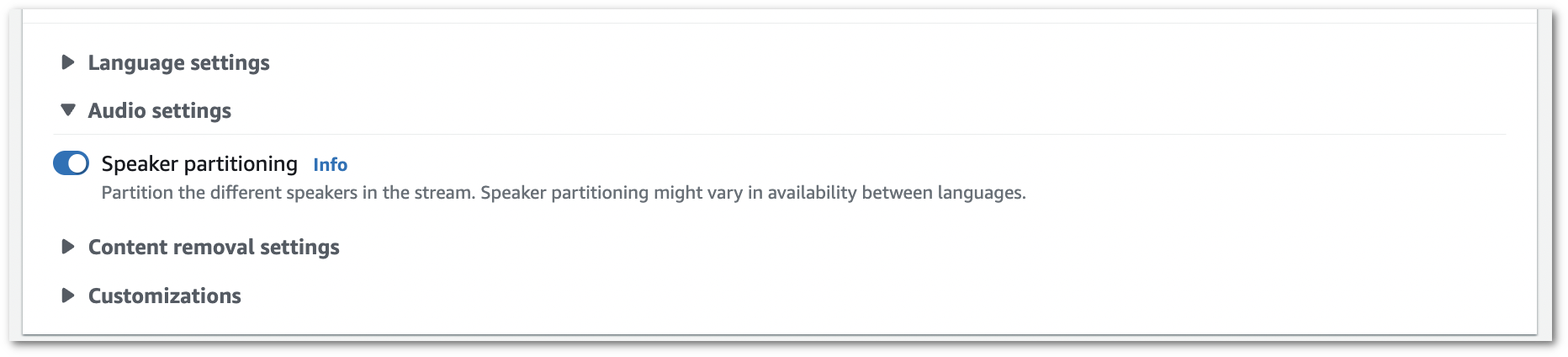
Aktivieren Sie die Sprecherpartitionierung.
-
Jetzt können Sie Ihren Stream transkribieren. Wählen Sie Streaming starten und beginnen Sie zu sprechen. Um Ihr Diktat zu beenden, wählen Sie Streaming beenden.
In diesem Beispiel wird eine HTTP/2 Anfrage erstellt, die Lautsprecher in Ihrer Transkriptionsausgabe partitioniert. Weitere Informationen zur Verwendung von HTTP/2 Streaming mit finden Sie Amazon Transcribe unterEinen HTTP/2 Stream einrichten. Weitere Einzelheiten zu Parametern und Kopfzeilen, die speziell für Amazon Transcribe gelten, finden Sie unter StartStreamTranscription.
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-show-speaker-label: true transfer-encoding: chunked
Parameterdefinitionen finden Sie in der API-Referenz. Parameter, die allen AWS API-Vorgängen gemeinsam sind, sind im Abschnitt Allgemeine Parameter aufgeführt.
In diesem Beispiel wird eine vorsignierte URL erstellt, die die Sprecher in Ihrer Transkriptionsausgabe trennt. Für eine bessere Lesbarkeit werden Zeilenumbrüche hinzugefügt. Weitere Hinweise zur Verwendung von WebSocket Streams mit Amazon Transcribe finden Sie unterEinen WebSocket Stream einrichten. Weitere Einzelheiten zu den Parametern finden Sie unter StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US &specialty=PRIMARYCARE&type=DICTATION&media-encoding=flac&sample-rate=16000&show-speaker-label=true
Parameterdefinitionen finden Sie in der API-Referenz. Parameter, die allen AWS API-Vorgängen gemeinsam sind, sind im Abschnitt Allgemeine Parameter aufgeführt.
