Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon Transcribe unterstützt die Ausgabe von WebVTT (*.vtt) und SubRip (*.srt) zur Verwendung als Videountertitel. Sie können einen oder beide Dateitypen auswählen, wenn Sie Ihren Batch-Videotranskriptionsauftrag einrichten. Bei Verwendung des Features „Untertitel“ werden die von Ihnen ausgewählte(n) Untertiteldatei(en) und eine reguläre Transkriptdatei (mit zusätzlichen Informationen) erstellt. Untertitel- und Transkriptionsdateien werden an dasselbe Ziel ausgegeben.
Die Untertitel werden gleichzeitig mit dem gesprochenen Text angezeigt und bleiben sichtbar, bis eine natürliche Pause entsteht oder der Sprecher zu Ende spricht. Beachten Sie, dass keine Untertiteldatei erstellt wird, wenn Sie Untertitel in Ihrer Transkriptionsanforderung aktivieren und Ihr Audio keine Sprache enthält.
Wichtig
Amazon Transcribe verwendet einen Standard-Startindex von 0 für die Untertitelausgabe, der sich vom häufiger verwendeten Wert von unterscheidet. 1 Wenn Sie einen Startindex von benötigen1, können Sie dies in der AWS Management Console oder in Ihrer API-Anfrage mithilfe des OutputStartIndexParameters angeben.
Die Verwendung des falschen Startindexes kann zu Kompatibilitätsfehlern mit anderen Services führen. Stellen Sie daher sicher, dass Sie vor der Erstellung Ihrer Untertitel überprüfen, welchen Startindex Sie benötigen. Wenn Sie sich nicht sicher sind, welchen Wert Sie verwenden sollen, empfehlen wir Ihnen, 1 zu wählen. Weitere Informationen finden Sie unter Subtitles.
Unterstützte Features mit Untertiteln:
-
Schwärzung von Inhalten – Alle geschwärzten Inhalte werden sowohl in den Untertitel- als auch in den regulären Transkriptausgabedateien als „
PII“ angezeigt. Audio wird nicht verändert. -
Wortschatzfilter – Untertiteldateien werden aus der Transkriptionsdatei generiert, sodass alle Wörter, die Sie in Ihrer Standardtranskriptionsausgabe filtern, auch in Ihren Untertiteln gefiltert werden. Gefilterte Inhalte werden als Leerraum oder
***in Ihren Transkript- und Untertiteldateien angezeigt. Audio wird nicht verändert. -
Sprecherdiarisierung – Wenn es in einem Untertitelsegment mehrere Sprecher gibt, werden Bindestriche zur Unterscheidung der einzelnen Sprecher verwendet. Dies gilt sowohl für WebVTT als auch für SubRip Formate; zum Beispiel:
-- Text gesprochen von Person 1
-- Text gesprochen von Person 2
Untertiteldateien werden am selben Amazon S3 Ort wie Ihre Transkriptionsausgabe gespeichert.
Eine Videoanleitung zur Erstellung von Untertiteln finden Sie unter:
Erzeugen von Untertiteldateien
Sie können Untertiteldateien mithilfe von AWS Management ConsoleAWS CLIAWS SDKs, oder erstellen. Sehen Sie sich die folgenden Beispiele an:
-
Melden Sie sich an der AWS Management Console
an. -
Wählen Sie im Navigationsbereich Transkriptionsaufträge und dann Auftrag erstellen (oben rechts). Dies öffnet die Seite Auftragsdetails angeben. Die Optionen für Untertitel befinden sich im Bereich Ausgabedaten.
-
Wählen Sie die Formate aus, die Sie für Ihre Untertiteldateien wünschen, und wählen Sie dann einen Wert für den Startindex. Beachten Sie, dass dies die Amazon Transcribe Standardeinstellung
1ist0, aber häufiger verwendet wird. Wenn Sie sich nicht sicher sind, welchen Wert Sie verwenden sollen, empfehlen wir Ihnen,1zu wählen, da dies die Kompatibilität mit anderen Services verbessern kann.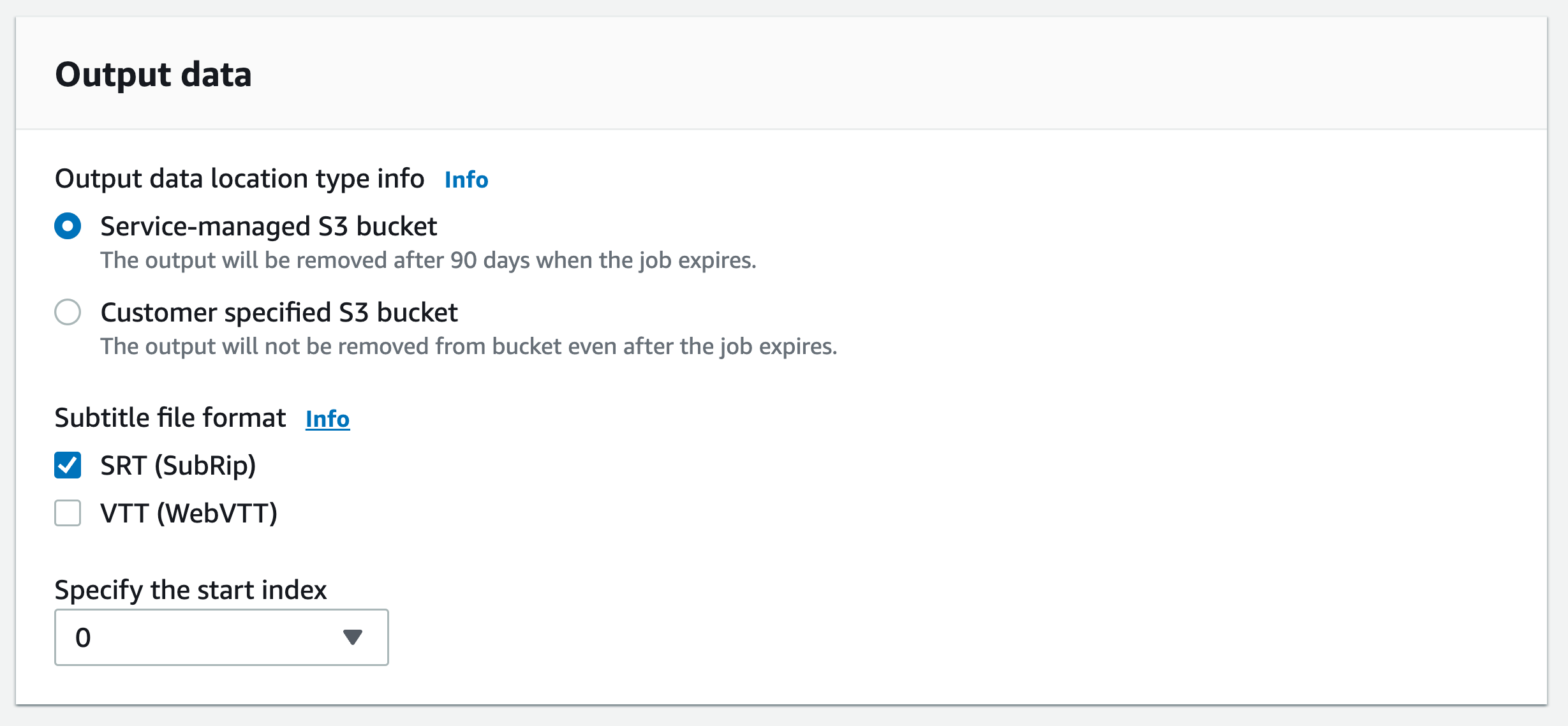
-
Füllen Sie alle anderen Felder aus, die Sie auf der Seite Auftragsdetails angeben möchten, und wählen Sie dann Weiter. Hier gelangen Sie zur Seite Auftrag konfigurieren – optional .
-
Wählen Sie Auftrag erstellen, um Ihren Transkriptionsauftrag auszuführen.
-
Melden Sie sich an der AWS Management Console
an. -
Wählen Sie im Navigationsbereich Transkriptionsaufträge und dann Auftrag erstellen (oben rechts). Dies öffnet die Seite Auftragsdetails angeben. Die Optionen für Untertitel befinden sich im Bereich Ausgabedaten.
-
Wählen Sie die Formate aus, die Sie für Ihre Untertiteldateien wünschen, und wählen Sie dann einen Wert für den Startindex. Beachten Sie, dass dies die Amazon Transcribe Standardeinstellung
1ist0, aber häufiger verwendet wird. Wenn Sie sich nicht sicher sind, welchen Wert Sie verwenden sollen, empfehlen wir Ihnen,1zu wählen, da dies die Kompatibilität mit anderen Services verbessern kann.
-
Füllen Sie alle anderen Felder aus, die Sie auf der Seite Auftragsdetails angeben möchten, und wählen Sie dann Weiter. Hier gelangen Sie zur Seite Auftrag konfigurieren – optional .
-
Wählen Sie Auftrag erstellen, um Ihren Transkriptionsauftrag auszuführen.
In diesem Beispiel werden der Befehl und der start-transcription-jobSubtitles Weitere Informationen erhalten Sie unter StartTranscriptionJob und Subtitles.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --subtitles Formats=vtt,srt,OutputStartIndex=1
Hier ist ein weiteres Beispiel, in dem der start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-subtitle-job.json
Die Datei my-first-subtitle-job.json enthält den folgenden Anforderungstext.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Subtitles": {
"Formats": [
"vtt","srt"
],
"OutputStartIndex": 1
}
}In diesem Beispiel werden mithilfe des AWS SDK für Python (Boto3) Subtitles Arguments für die Methode start_transcription_jobStartTranscriptionJob und Subtitles.
Weitere Beispiele für die Verwendung der AWS SDKs, einschließlich funktionsspezifischer, szenarienspezifischer und dienstübergreifender Beispiele, finden Sie im Kapitel. Codebeispiele für Amazon Transcribe mit AWS SDKs
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Subtitles = {
'Formats': [
'vtt','srt'
],
'OutputStartIndex': 1
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)