Prácticas recomendadas para Amazon RDS
Descubra las prácticas recomendadas para trabajar con Amazon RDS. A medida que se identifiquen nuevas prácticas recomendadas, se actualizará esta sección.
Temas
nota
Para ver recomendaciones frecuentes para Amazon RDS, consulte Recomendaciones para Amazon RDS.
Directrices operativas básicas de Amazon RDS
A continuación se detallan las directrices operativas básicas que se deben seguir al trabajar con Amazon RDS. El Acuerdo de nivel de servicios de Amazon RDS requiere que se sigan estas directrices:
-
Utilice métricas para supervisar la memoria, la CPU, el retraso de las réplicas y el uso de almacenamiento. Puede configurar Amazon CloudWatch para que le notifique cuando cambien los patrones de uso o cuando su implementación se acerque a los límites de capacidad. De esta forma, puede mantener el rendimiento y la disponibilidad del sistema.
-
Escale la instancia de base de datos cuando se esté acercando a los límites de la capacidad de almacenamiento. Debe tener búfer de almacenamiento y de memoria para asumir incrementos imprevistos de la demanda de las aplicaciones.
-
Habilite las copias de seguridad automáticas y configure la ventana de copia de seguridad para que se produzca durante el momento diario en el que más bajen las IOPS de escritura. Es entonces cuando una copia de seguridad es menos perjudicial para el uso de la base de datos.
-
Si la carga de trabajo de la base de datos requiere más E/S de la aprovisionada, la recuperación tras una conmutación por error o tras un error de la base de datos será lenta. Para incrementar la capacidad de E/S de una instancia de base de datos, lleve a cabo una de las acciones siguientes o todas ellas:
Migre a una clase de instancia de base de datos distinta con una alta capacidad de E/S.
Convierta desde el almacenamiento magnético al almacenamiento de uso general o de IOPS provisionadas en función del incremento que necesite. Para obtener información acerca de los tipos de almacenamiento disponibles, consulte Tipos de almacenamiento de Amazon RDS.
Si convierte a almacenamiento de IOPS provisionadas, asegúrese de que también usa una clase de instancia de base de datos que se haya optimizado para las IOPS provisionadas. Para obtener información acerca de las IOPS provisionadas, consulte Almacenamiento de SSD de IOPS aprovisionadas.
Si ya está usando almacenamiento de IOPS provisionadas, aprovisione capacidad de rendimiento adicional.
-
Si la aplicación cliente almacena en caché los datos del Servicio de nombres de dominio (DNS) de las instancias de base de datos, defina un valor de tiempo de vida (TTL) de menos de 30 segundos. La dirección IP subyacente de una instancia de base de datos puede cambiar después de producirse una conmutación por error. Por lo tanto, almacenar en caché los datos de DNS durante un tiempo prolongado puede provocar errores de conexión. Es posible que tu aplicación intente conectarse a una dirección IP que ya no esté en servicio.
-
Pruebe la conmutación por error de la instancia de base de datos para comprender cuánto tiempo tarda el proceso en su caso de uso particular. Pruebe también la conmutación por error para asegurarse de que la aplicación que accede a su instancia de base de datos puede conectarse automáticamente a la nueva instancia de base de datos después de la conmutación por error.
Recomendaciones de RAM de las instancias de base de datos
Una práctica recomendada de rendimiento de Amazon RDS consiste en asignar suficiente RAM para que el conjunto de trabajo resida casi por completo en la memoria. El conjunto de trabajo son los datos e índices que se usan con frecuencia en su instancia. Cuanto más use la instancia de base de datos, más crecerá el conjunto de trabajo.
Para saber si el conjunto de trabajo está en la memoria casi en su totalidad, compruebe la métrica ReadIOPS (usando Amazon CloudWatch) mientras la instancia de base de datos está sometida a carga. El valor de ReadIOPS debe ser pequeño y estable. En algunos casos, escalar verticalmente la clase de instancia de base de datos a una clase con más RAM da como resultado una disminución brusca de ReadIOPS. En estos casos, el conjunto de trabajo no estaba casi completamente en la memoria. Siga escalando hasta que ReadIOPS no se reduzca bruscamente después de una operación de escalado o hasta que ReadIOPS se reduzca muy poco. Para obtener más información acerca de la monitorización de las métricas de las instancias de base de datos, consulte Consulta de métricas en la consola de Amazon RDS.
Mantenimiento de versiones actualizadas del motor de base de datos
Actualice con regularidad la versión de motor de base de datos para mantener la seguridad, el rendimiento y el cumplimiento. Amazon RDS publica nuevas versiones principales y secundarias que incluyen revisiones de seguridad, mejoras de rendimiento y características nuevas. Ejecutar un motor de base de datos obsoleto puede exponer las cargas de trabajo a vulnerabilidades conocidas, problemas de compatibilidad y una asistencia reducida por parte de AWS y los proveedores de bases de datos.
Para minimizar las interrupciones, tenga en cuenta lo siguiente cuando planifique las actualizaciones:
-
Realice pruebas en un entorno provisional: valide la nueva versión en la carga de trabajo antes de actualizar las bases de datos de producción.
-
Utilice las actualizaciones administradas por Amazon RDS: habilite las actualizaciones automáticas de versiones secundarias para facilitar la aplicación de revisiones.
-
Programe las actualizaciones de las versiones principales: consulte las notas de la versión, compruebe la compatibilidad de las aplicaciones y planifique un periodo de actualización controlado.
Las actualizaciones periódicas ayudan a garantizar que la base de datos permanezca segura, optimizada y alineada con las prácticas recomendadas de AWS.
AWSControladores de bases de datos de
Recomendamos el conjunto de controladores de AWS para la conectividad de las aplicaciones. Los controladores se han diseñado para permitir tiempos de transición y conmutación por error más rápidos y autenticarse con AWS Secrets Manager, AWS Identity and Access Management (IAM) e identidad federada. Los controladores de AWS se basan en la supervisión del estado de la instancia de base de datos y en el conocimiento de la topología de la instancia para determinar quién es el nuevo escritor. Este enfoque reduce los tiempos de transición y conmutación por error a segundos de un solo dígito, en comparación con las decenas de segundos de los controladores de código abierto.
A medida que se introducen nuevas características de servicio, el objetivo del conjunto de controladores de AWS es contar con soporte integrado para estas características de servicio.
Para obtener más información, consulte Conexión a instancias de base de datos con los controladores de AWS.
Uso del monitoreo mejorado para identificar los problemas del sistema operativo
Cuando el monitoreo mejorado está habilitado, Amazon RDS proporciona métricas en tiempo real para el sistema operativo (SO) en el que se ejecuta la instancia de base de datos. Puede ver las métricas de su instancia de base de datos mediante la consola. También puede consumir la salida JSON de monitoreo mejorado en Amazon CloudWatch Logs en un sistema de monitoreo de su elección. Para obtener más información acerca de la monitorización mejorada, consult Supervisión de las métricas del sistema operativo con Supervisión mejorada.
Uso de métricas para identificar los problemas de rendimiento
Para identificar los problemas de desempeño causados por la falta de recursos y otros cuellos de botella frecuentes, puede monitorizar las métricas disponibles para la instancia de base de datos de Amazon RDS.
Visualización de métricas de rendimiento
Debe monitorizar las métricas de desempeño con frecuencia para ver los valores medios, máximos y mínimos de diversos intervalos de tiempo. De este modo podrá identificar cuándo se degrada el rendimiento. También puede definir alarmas de Amazon CloudWatch para umbrales de métricas concretos si desea recibir alertas cuando se alcancen.
Para solucionar los problemas de rendimiento, es importante conocer el rendimiento de referencia del sistema. Al configurar una instancia de base de datos y ejecutarla con una carga de trabajo típica, capture los valores promedio, máximo y mínimo de todas las métricas de rendimiento. Hágalo en diferentes intervalos (por ejemplo, una hora, 24 horas, una semana o dos semanas). Esto puede darle una idea de lo que es normal. Ayuda a obtener comparaciones para las horas con picos y valles de funcionamiento. Puede usar esta información para saber cuándo cae el desempeño por debajo de los niveles estándar.
Si utiliza clústeres de base de datos Multi-AZ, supervise la diferencia de tiempo entre la última transacción en la instancia de base de datos del escritor y la última transacción aplicada en una instancia de base de datos del lector. Esta diferencia se llama retraso de réplicas. Para obtener más información, consulte Retraso de réplica y clústeres de base de datos Multi-AZ.
Puede ver las métricas combinadas de Información de rendimiento y CloudWatch en el panel de Información de rendimiento y monitorizar su instancia de base de datos. Para utilizar esta vista de monitorización, es necesario activar Información de rendimiento para la instancia de base de datos. Para obtener más información sobre la monitorización, consulte Visualización de las métricas combinadas en la consola de Amazon RDS.
Puede crear un informe de análisis de rendimiento para un período de tiempo específico y ver la información identificada y las recomendaciones para resolver los problemas. Para obtener más información, consulte Creación de un informe de análisis de rendimiento en Información de rendimiento.
Para ver las métricas de desempeño
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. En el panel de navegación, elija Databases (Bases de datos) y seleccione una instancia de base de datos.
Elija Monitoring (Monitorización).
El panel proporciona las métricas de rendimiento. Las métricas muestran de forma predeterminada la información de las últimas tres horas.
Use los botones numerados de la esquina superior derecha para recorrer las métricas adicionales o ajustar la configuración para ver más métricas.
Seleccione una métrica de rendimiento para ajustar el intervalo de tiempo con el fin de ver los datos de un día distinto del actual. Puede cambiar los valores Statistic, Time Range y Period para ajustar la información mostrada. Por ejemplo, puede que desee ver los valores máximos de una métrica para cada día de las dos últimas semanas. Si es así, establezca Statistic (Estadísticas) en Maximum (Máximo), Máximo (Intervalo de tiempo) en Last 2 Weeks (Últimas 2 semanas) y Period (Período) en Day (Día).
También puede ver las métricas de rendimiento usando la interfaz de línea de comandos (CLI) o la API. Para obtener más información, consulte Consulta de métricas en la consola de Amazon RDS.
Para definir una alarma de CloudWatch
-
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En el panel de navegación, elija Databases (Bases de datos) y seleccione una instancia de base de datos.
-
Seleccione Logs & events (Registros y eventos).
-
En la sección CloudWatch alarms (Alarmas de CloudWatch), elija Create alarm (Crear alarma).
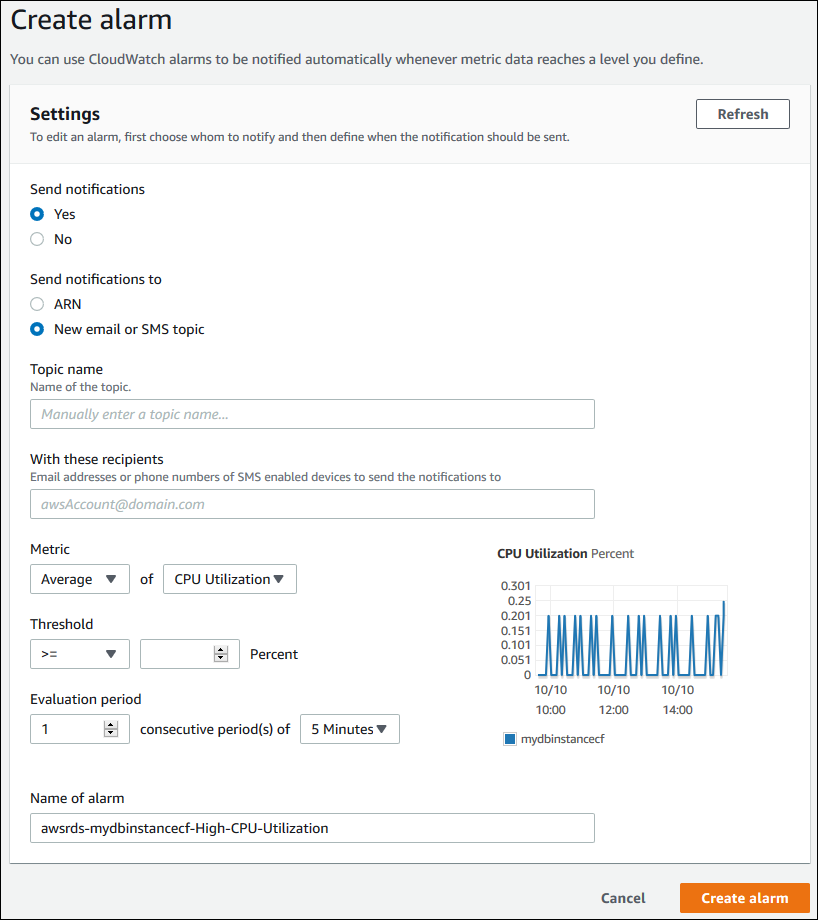
-
En Send notifications (Enviar notificaciones), elija Yes (Sí) y en Send notifications to (Enviar notificaciones a), elija New email or SMS topic (Nuevo correo electrónico o tema de SMS).
-
En Topic name (Nombre de tema), escriba un nombre para la notificación y en With these recipients (Con estos destinatarios), escriba una lista separada por comas de direcciones de correo electrónico y números de teléfono.
-
En Metric (Métrica), seleccione la estadística de alarmas y métrica que definir.
-
Para Threshold (Umbral), especifique si la métrica debe ser mayor que, menor que o igual que el umbral y especifique el valor del umbral.
-
Para Evaluation period (Período de evaluación), elija el periodo de evaluación de la alarma. Para consecutive period(s) of (períodos consecutivos de), elija el período durante el que desea que el umbral se deba haber alcanzado para disparar la alarma.
-
En Name of alarm (Nombre de la alarma), escriba un nombre para la alarma.
-
Elija Create Alarm.
La alarma aparece en la sección CloudWatch alarms (Alarmas de CloudWatch).
Evaluación de las métricas de rendimiento
Una instancia de base de datos tiene varias categorías de métricas diferentes, y la forma de determinar los valores aceptables depende de la métrica.
CPU
Utilización de la CPU: porcentaje de la capacidad de procesamiento del equipo que está en uso.
Memoria
-
Memoria que se puede liberar: cuánta RAM está disponible en la instancia de base de datos en bytes. La línea roja de las métricas de la pestaña de monitorización está marcada en el 75 % para las métricas de CPU, memoria y almacenamiento. Si el consumo de memoria de instancia supera con frecuencia esta línea, significa que debe verificar la carga de trabajo o actualizar la instancia.
Uso del espacio de intercambio: cuánto espacio de intercambio usa la instancia de base de datos en bytes.
Espacio en disco
Espacio de almacenamiento disponible: cuánto espacio en disco no usa actualmente la instancia de base de datos en megabytes.
Operaciones de entrada y salida
IOPS de lectura, IOPS de escritura: número medio de operaciones de lectura o escritura en disco por segundo.
Latencia de lectura, latencia de escritura: tiempo medio de una operación de lectura o escritura en milisegundos.
Rendimiento de lectura, rendimiento de escritura: número medio de megabytes leídos o escritos en el disco por segundo.
Profundidad de la cola: número de operaciones de E/S que están esperando para la lectura o escritura en el disco.
Tráfico de red
Rendimiento de recepción de la red, rendimiento de transmisión de la red – La velocidad del tráfico de red de entrada y salida de la instancia de base de datos en bytes por segundo.
Conexiones a base de datos
Conexiones a base de datos: número de sesiones cliente que están conectadas a la instancia de base de datos.
Para obtener descripciones individuales más detalladas de cada métrica de rendimiento disponible, consulte Supervisión de métricas de Amazon RDS con Amazon CloudWatch.
En general, los valores aceptables para las métricas de desempeño dependen del aspecto de la referencia y de lo que hace la aplicación. Investigue las variaciones coherentes o de las tendencias con respecto a la referencia. La siguiente sección ofrece algunas sugerencias sobre tipos concretos de métricas:
High CPU or RAM consumption (Alto consumo de CPU o RAM): unos valores elevados de consumo de CPU o RAM pueden ser adecuados. Por ejemplo, pueden ser si se ajustan a los objetivos de su aplicación (de rendimiento o simultaneidad, por ejemplo) y son los esperados.
Consumo de espacio en disco: investigue el consumo de espacio en el disco si el espacio utilizado está por sistema alrededor o por encima del 85 % del espacio total disponible en el disco. Compruebe si es posible eliminar datos de la instancia o archivar los datos en un sistema diferente para liberar espacio.
Tráfico de red: para el tráfico de red, hable con el administrador de su sistema para saber cuál es el rendimiento esperado para la red de su dominio y para su conexión a Internet. Investigue el tráfico de red si el rendimiento es por sistema inferior al esperado.
Conexiones a bases de datos: valore la posibilidad de restringir las conexiones a las bases de datos si ve que hay un alto número de conexiones de usuarios junto con una reducción en el rendimiento y el tiempo de respuesta de la instancia. El mejor número de conexiones de usuarios para su instancia de base de datos variará en función de la clase de instancia y de la complejidad de las operaciones que se estén llevando a cabo. Para determinar el número de conexiones a bases de datos, asocie la instancia de base de datos con un grupo de parámetros. En este grupo, defina el parámetro User Connections (Conexiones de usuario) en un valor distinto de 0 (ilimitado). Puede utilizar un grupo de parámetros existente o crear uno nuevo. Para obtener más información, consulte Grupos de parámetros para Amazon RDS.
Métricas de IOPS: los valores esperados para las métricas de IOPS dependen de la especificación del disco y la configuración del servidor, así que debe usar su referencia para conocer los valores típicos. Investigue si los valores son por sistema diferentes de los de la referencia. Para un desempeño óptimo de IOPS, asegúrese de que el conjunto de trabajo típico se ajuste a la memoria para minimizar las operaciones de lectura y escritura.
Para los problemas con las métricas de rendimiento, un primer paso para mejorar el rendimiento es ajustar las consultas más utilizadas y más costosas. Ajústelas para ver si hacerlo reduce la presión sobre los recursos del sistema. Para obtener más información, consulte Ajuste de consultas.
Si sus consultas están ajustadas y el problema persiste, considere la posibilidad de actualizar su Clases de instancia de base de datos de de Amazon RDS. Puede actualizarla a una con más cantidad del recurso (CPU, RAM, espacio en disco, ancho de banda de red, capacidad de E/S) relacionado con el problema.
Ajuste de consultas
Una de las formas más eficaces de mejorar el desempeño de la instancia de base de datos es ajustar las consultas más utilizadas y que más recursos consumen. Aquí, se ajustan para que sean menos costosos de ejecutar. Para obtener información sobre cómo mejorar las consultas, utilice los siguientes recursos:
-
MySQL – Consulte Optimización de sentencias SELECT
en la documentación de MySQL. También puede ir a MySQL Performance Tuning and Optimization Resources para ver otros recursos relacionados con el ajuste de las consultas. -
Oracle – Consulte la Guía de ajuste SQL de base de datos
en la documentación de Oracle Database. -
SQL Server – Consulte Análisis de una consulta
en la documentación de Microsoft. También puede usar las vistas de administración de datos (DMV) relacionadas con la ejecución, los índices y las operaciones de E/S que se describen en la documentación de System Dynamic Management Views en la documentación de Microsoft para solucionar los problemas de las consultas de SQL Server. Un aspecto habitual del ajuste de consultas es la creación de índices eficaces. Para obtener mejoras potenciales en el índice de la instancia de base de datos, consulte el Asesor de ajuste del motor de base
de datos en la documentación de Microsoft. Para obtener información sobre el uso del Asesor de Ajustes en RDS for SQL Server, consulte Análisis de la carga de trabajo de una base de datos de una instancia de base de datos de Amazon RDS for SQL Server con el Asistente para la optimización del motor de base de datos. -
PostgreSQL – Vaya a Using EXPLAIN
en la documentación de PostgreSQL para ver cómo se analiza un plan de consulta. Puede utilizar esta información para modificar una consulta o las tablas subyacentes con el fin de mejorar el desempeño de las consultas. Para obtener información sobre cómo especificar uniones en las consultas para un mejor desempaño, consulte Controlling the Planner with Explicit JOIN Clauses
. -
MariaDB – Consulte optimizaciones de consultas
en la documentación de MariaDB.
Prácticas recomendadas para trabajar con MySQL
Tanto el tamaño de las tablas como el número de tablas de una base de datos MySQL pueden afectar al rendimiento.
Tamaño de las tablas
Normalmente, las restricciones del sistema operativo relativas al tamaño de los archivos determinan el tamaño máximo efectivo de las tablas para las bases de datos MySQL. Por tanto, los límites generalmente no están determinados por restricciones internas de MySQL.
En una instancia de base de datos de MySQL, evite que las tablas de la base de datos crezcan demasiado. Aunque el límite de almacenamiento general es de 64 TiB, los límites de almacenamiento aprovisionado restringen el tamaño máximo de un archivo de tabla de MySQL a 16 TiB. Divida las tablas grandes para que los tamaños de archivo estén claramente por debajo del límite de 16 TiB. Este método también puede mejorar el desempeño y el tiempo de recuperación. Para obtener más información, consulte Límites de tamaño de archivo de MySQL en Amazon RDS.
Las tablas muy grandes (de más de 100 GB de tamaño) pueden afectar negativamente al rendimiento tanto de las lecturas como de las escrituras (incluidas las instrucciones de lenguaje de manipulación de datos o DML y especialmente las instrucciones lenguaje de definición de datos o DDL). Que haya índices en tablas grandes puede aumentar considerablemente el desempeño de SELECT, pero también puede deteriorar el rendimiento de las instrucciones DML. Las instrucciones DDL, como ALTER TABLE, pueden ser considerablemente más lentas con las tablas grandes, pues con esas operaciones es posible que en algunos casos se reconstruya completamente una tabla. Con estas instrucciones DDL es posible que las tablas se bloqueen durante la duración de la operación.
La cantidad de memoria que requiere MySQL para lecturas y escrituras depende de las tablas que se impliquen en las operaciones. Es una práctica recomendada tener al menos suficiente RAM para mantener los índices de las tablas que se utilicen activamente. Para determinar cuáles son las diez tablas e índices más grandes de una base de datos, utilice la siguiente consulta:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Número de tablas
El sistema de archivos subyacente puede tener un límite en cuanto al número de archivos que representan tablas. Sin embargo, MySQL no tiene límite en el número de tablas. A parte de esto, el número total de tablas que haya en el motor de almacenamiento de InnoDB de MySQL puede contribuir al deterioro del rendimiento, independientemente del tamaño que tengan esas tablas. Para limitar el efecto del sistema operativo, puede distribuir las tablas entre varias bases de datos en la misma instancia de base de datos MySQL. Si lo hace, se podría limitar el número de archivos que hay en un directorio, pero no se resolverá el problema general.
Si hay deterioro del rendimiento debido a un número de tablas grande (más de 10 000), es a causa de que MySQL está trabajando con archivos de almacenamiento, que incluye abrirlos y cerrarlos. Para atender esta cuestión, puede aumentar el tamaño de los parámetros table_open_cache y table_definition_cache. Sin embargo, aumentar los valores de esos parámetros podría aumentar considerablemente la cantidad de memoria que usa MySQL e incluso podría agotar toda la memoria disponible. Para obtener más información, consulte How MySQL Opens and Closes Tables
Además, que haya demasiadas tablas puede afectar considerablemente el tiempo de inicio de MySQL. Es posible que afecte la posibilidad de que haya un apagado y un reinicio perfectos, así como una recuperación ante bloqueos, especialmente en versiones anteriores a MySQL 8.0.
Recomendamos tener menos de 10 000 tablas en total distribuidas entre todas las bases de datos de una instancia de base de datos. Para un caso de uso con un número de tablas grande en una base de datos MySQL, consulte One Million Tables in MySQL 8.0 (1 millón de tablas en MySQL 8.0)
Motor de almacenamiento
Las características de restauración a un momento dado y restauración de instantáneas de Amazon RDS para MySQL requieren un motor de almacenamiento que pueda recuperarse en caso de bloqueo. Estas características solo son compatibles para el motor de almacenamiento InnoDB. Aunque MySQL admite varios motores de almacenamiento con diversas capacidades, no todos están optimizados para la recuperación en caso de bloqueo y la durabilidad de los datos. Por ejemplo, el motor de almacenamiento de MyISAM no admite la recuperación fiable tras bloqueo y podría impedir que la restauración a un momento dado o la restauración de instantáneas funcionen según lo previsto. Esto podría traducirse en datos perdidos o dañados cuando MySQL se reinicia después de un bloqueo.
InnoDB es el motor de almacenamiento recomendado y admitido para las instancias de base de datos de MySQL en Amazon RDS. Las instancias de base de datos de InnoDB también se pueden migrar a Aurora, mientras que las instancias de MyISAM no se pueden migrar. Sin embargo, MyISAM funciona mejor que InnoDB si se requiere una capacidad intensiva de búsqueda de texto completo. Si a pesar de ello quiere usar MyISAM con Amazon RDS, seguir los pasos que se describen en Copias de seguridad automatizadas con motores de almacenamiento de MySQL no compatibles puede resultar útil en algunas situaciones para la funcionalidad de restauración de instantáneas.
Si desea convertir tablas de MyISAM en tablas de InnoDB, puede utilizar el proceso que se describe en Converting Tables from MyISAM to InnoDB
Además, no se admite el motor de almacenamiento federado para Amazon RDS for MySQL.
Prácticas recomendadas para trabajar con MariaDB
Tanto el tamaño de las tablas como el número de tablas de una base de datos de MariaDB pueden afectar al rendimiento.
Tamaño de las tablas
Normalmente, las restricciones del sistema operativo relativas al tamaño de los archivos determinan el tamaño máximo efectivo de las tablas para las bases de datos de MariaDB. Por tanto, los límites generalmente no están determinados por restricciones internas de MariaDB.
En una instancia de base de datos de MariaDB, evite que las tablas de la base de datos aumenten demasiado de tamaño. Aunque el límite de almacenamiento general es 64 TiB, debido a los límites de almacenamiento aprovisionado el tamaño máximo de un archivo de tabla de MariaDB se restringe a 16 TiB. Divida las tablas grandes para que los tamaños de archivo estén claramente por debajo del límite de 16 TiB. Este método también puede mejorar el desempeño y el tiempo de recuperación.
Las tablas muy grandes (de más de 100 GB de tamaño) pueden afectar negativamente al rendimiento tanto de las lecturas como de las escrituras (incluidas las instrucciones de lenguaje de manipulación de datos o DML y especialmente las instrucciones lenguaje de definición de datos o DDL). Que haya índices en tablas grandes puede aumentar considerablemente el desempeño de SELECT, pero también puede deteriorar el rendimiento de las instrucciones DML. Las instrucciones DDL, como ALTER TABLE, pueden ser considerablemente más lentas con las tablas grandes, pues con esas operaciones es posible que en algunos casos se reconstruya completamente una tabla. Con estas instrucciones DDL es posible que las tablas se bloqueen durante la duración de la operación.
La cantidad de memoria que requiere MariaDB para lecturas y escrituras depende de las tablas que se impliquen en las operaciones. Es una práctica recomendada tener al menos suficiente RAM para mantener los índices de las tablas que se utilicen activamente. Para determinar cuáles son las diez tablas e índices más grandes de una base de datos, utilice la siguiente consulta:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Número de tablas
El sistema de archivos subyacente puede tener un límite en cuanto al número de archivos que representan tablas. Sin embargo, MariaDB no tiene límite en el número de tablas. A parte de esto, el número total de tablas que haya en el motor de almacenamiento de InnoDB de MariaDB puede contribuir al deterioro del rendimiento, independientemente del tamaño que tengan esas tablas. Para limitar el efecto del sistema operativo, puede distribuir las tablas entre varias bases de datos en la misma instancia de base de datos de MariaDB. Si lo hace, se podría limitar el número de archivos que hay en un directorio, pero no se resuelve el problema general.
Si hay deterioro del rendimiento debido a un número de tablas grande (más de 10 000), es a causa de que MariaDB está trabajando con archivos de almacenamiento. Este trabajo incluye que MariaDB abra y cierre archivos de almacenamiento. Para atender esta cuestión, puede aumentar el tamaño de los parámetros table_open_cache y table_definition_cache. Sin embargo, aumentar los valores de esos parámetros podría aumentar considerablemente la cantidad de memoria que usa MariaDB. Incluso podría usar toda la memoria disponible. Para obtener más información, consulte Optimizing table_open_cache
Además, que haya demasiadas tablas puede afectar considerablemente el tiempo de inicio de MariaDB. Es posible que afecte la posibilidad de que haya un apagado y un reinicio perfectos, así como una recuperación ante bloqueos. Recomendamos tener menos de 10 000 tablas en total distribuidas entre todas las bases de datos de una instancia de base de datos.
Motor de almacenamiento
Las características de restauración a un momento dado y restauración de instantáneas de Amazon RDS for MariaDB requieren un motor de almacenamiento que pueda recuperarse en caso de bloqueo. Aunque MariaDB admite varios motores de almacenamiento con diversas capacidades, no todos están optimizados para la recuperación en caso de bloqueo y la durabilidad de los datos. Por ejemplo, aunque Aria es un sustituto a prueba de bloqueos para MyISAM, también podría impedir que la restauración a un momento dado o la restauración de instantáneas funcionen según lo previsto. Esto podría traducirse en datos perdidos o dañados cuando MariaDB se reinicia después de un bloqueo. InnoDB es el motor de almacenamiento recomendado y admitido para las instancias de base de datos de MariaDB en Amazon RDS. Si a pesar de ello quiere usar Aria con Amazon RDS, seguir los pasos que se describen en Copias de seguridad automatizadas con motores de almacenamiento de MariaDB no compatibles puede resultar útil en algunas situaciones para la funcionalidad de restauración de instantáneas.
Si desea convertir tablas de MyISAM en tablas de InnoDB, puede utilizar el proceso que se describe en Converting Tables from MyISAM to InnoDB
Prácticas recomendadas para trabajar con Oracle
Para obtener información sobre las prácticas recomendadas para trabajar con Amazon RDS for Oracle, consulte Prácticas recomendadas para ejecutar Oracle Database en Amazon Web Services.
Un taller virtual de AWS de 2020 incluyó una presentación sobre la ejecución de bases de datos de Oracle de producción en Amazon RDS. Puede ver aquí un vídeo de la presentación:
Prácticas recomendadas para trabajar con PostgreSQL
De las dos áreas importantes en las que puede mejorar el rendimiento con RDS para PostgreSQL, una es la carga de datos en una instancia de base de datos. Otra es cuando se utiliza la característica autovacuum de PostgreSQL. Las siguientes secciones tratan algunas de las prácticas recomendadas para esas áreas.
Para obtener información sobre cómo Amazon RDS implementa otras tareas comunes de DBA de PostgreSQL, consulte Tareas comunes de los administradores de base de datos (DBA) para Amazon RDS para PostgreSQL.
Carga de datos en una instancia de base de datos de PostgreSQL
Cuando se cargan datos en una instancia de base de datos de Amazon RDS para PostgreSQL, se debe modificar la configuración de la instancia de base de datos y los valores del grupo de parámetros de base de datos. Configúrelos para permitir la importación más eficiente de datos a su instancia de base de datos.
Modifique la configuración de su instancia de base de datos como se indica a continuación:
-
Deshabilite las copias de seguridad de la instancia de base de datos (defina backup_retention como 0)
-
Desactive Multi-AZ
Modifique el grupo de parámetros de base de datos para incluir la siguiente configuración. Asimismo, pruebe la configuración de los parámetros para encontrar los ajustes más eficientes para su instancia de base de datos.
-
Aumente el valor del parámetro
maintenance_work_mem. Para obtener más información acerca de los parámetros de consumo de recursos de PostgreSQL, consulte la documentación de PostgreSQL. -
Aumente el valor de los parámetros
max_wal_sizeucheckpoint_timeoutpara reducir el número de escrituras en el registro de escritura anticipada (WAL). -
Desactive el parámetro
synchronous_commit. -
Deshabilite el parámetro autovacuum de PostgreSQL.
-
Asegúrese de que ninguna de las tablas que está importando esté sin registrar. Los datos almacenados en tablas sin registrar pueden perderse durante una conmutación por error. Para obtener más información, consulte el apartado de CREACIÓN DE TABLA SIN REGISTRAR
.
Use los comandos pg_dump -Fc (comprimido) o pg_restore -j (paralelo) con estos ajustes.
Una vez finalizada la operación de carga, devuelva la instancia de base de datos y los parámetros de base de datos a su configuración normal.
Trabajo con la característica autovacuum de PostgreSQL
La característica autovacuum de las bases de datos de PostgreSQL es una función cuyo uso se recomienda para mantener la instancia de base de datos de PostgreSQL en buen estado. Autovacuum automatiza la ejecución de los comandos VACUUM y ANALYZE. El uso de autovacuum es requerido por PostgreSQL, no impuesto por Amazon RDS, y es esencial para un buen desempeño. La característica está habilitada de manera predeterminada para todas las nuevas instancias de base de datos de Amazon RDS para PostgreSQL, y los parámetros de configuración relacionados se definen correctamente de forma predeterminada.
El administrador de la base de datos debe conocer y entender esta operación de mantenimiento. Para obtener la documentación de PostgreSQL sobre autovacuum, consulte The Autovacuum Daemon
Autovacuum no es una operación que no consuma recursos, pero funciona en segundo plano y deja a las operaciones del usuario toda la capacidad posible. Cuando está habilitado, autovacuum busca las tablas en las que se ha insertado, actualizado o eliminado un número elevado de tuplas. También protege contra la pérdida de los datos muy antiguos debida al reinicio de los ID de transacciones. Para obtener más información, consulte Preventing Transaction ID Wraparound Failures
Autovacuum no se debe entender como una operación de alto consumo que se puede reducir para mejorar el desempeño. Por el contrario, las tablas con una velocidad alta de actualizaciones y eliminaciones se deteriorarán con rapidez si no se ejecuta autovacuum.
importante
No ejecutar autovacuum puede llevar a una interrupción para realizar una operación de vacío mucho más intrusiva. En algunos casos, una instancia de base de datos de RDS para PostgreSQL puede dejar de estar disponible debido a un uso demasiado conservador de autovacuum. En estos casos, la base de datos de PostgreSQL se cierra para protegerse. En ese punto, Amazon RDS debe realizar un vacío completo en modo de un usuario directamente en la instancia de base de datos. Este vacío total puede provocar una interrupción de varias horas. Por ello, es recomendable no desactivar autovacuum, que está activado de manera predeterminada.
Los parámetros de autovacuum determinan cuándo y con qué intensidad funciona autovacuum. Los parámetrosautovacuum_vacuum_threshold y autovacuum_vacuum_scale_factor determinan cuándo se ejecuta autovacuum. Los parámetros autovacuum_max_workers, autovacuum_nap_time, autovacuum_cost_limit y autovacuum_cost_delay determinan la intensidad con la que trabaja autovacuum. Para obtener más información acerca de autovacuum, de cuándo se ejecuta y de los parámetros que requiere, consulte Routine Vacuuming
La siguiente consulta muestra el número de tuplas “muertas” en una tabla denominada table1:
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
Los resultados de la consulta serán similares a los siguientes:
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Video de prácticas recomendadas de Amazon RDS for PostgreSQL
La conferencia de AWS re:Invent de 2020 incluyó una presentación sobre nuevas características y prácticas recomendadas para trabajar con PostgreSQL en Amazon RDS. Puede ver aquí un vídeo de la presentación:
Prácticas recomendadas para trabajar con SQL Server
Entre las prácticas recomendadas para un despliegue Multi-AZ con una instancia de base de datos de SQL Server se incluyen las siguientes:
Use los eventos de base de datos de Amazon RDS para monitorizar las conmutaciones por error. Por ejemplo, puede recibir una notificación en un mensaje de texto o un correo electrónico cuando se produzca una conmutación por error de una instancia de base de datos. Para obtener más información acerca de los eventos de Amazon RDS, consulte Uso de notificaciones de eventos de Amazon RDS.
Si su aplicación almacena en caché los valores DNS, defina el tiempo de vida (TTL) en menos de 30 segundos. Definir TTL en este valor es una práctica recomendada en caso de que se produzca una conmutación por error. En una conmutación por error, la dirección IP podría cambiar y el valor en caché podría dejar de estar en servicio.
Es recomendable que no habilite los modos siguientes porque desactivan el registro de transacciones, que es necesario para el uso de Multi-AZ:
-
Modo de recuperación simple
-
Modo sin conexión
-
Modo de solo lectura
-
Pruebe para determinar cuánto tiempo se tarda en completar la conmutación por error de la instancia de base de datos. El tiempo de la conmutación por error puede variar en función del tipo de base de datos, la clase de instancia y el tipo de almacenamiento utilizado. También debe probar la capacidad de su aplicación para seguir trabajando si se produce una conmutación por error.
Para acortar el tiempo necesario para la conmutación por error, haga lo siguiente:
Compruebe que tiene asignadas las IOPS provisionadas necesarias para su carga de trabajo. Los valores de E/S inadecuados pueden alargar los tiempos de conmutación por error. La recuperación de la base de datos requiere E/S.
Use transacciones más pequeñas. La recuperación de bases de datos se basa en las transacciones, de modo que si divide las transacciones grandes en varias transacciones más pequeñas, el tiempo de conmutación por error debería acortarse.
Tenga en cuenta que, durante una conmutación por error, habrá latencias elevadas. Como parte del proceso de conmutación por error, Amazon RDS replica automáticamente los datos en una nueva instancia en espera. Esta replicación significa que los datos nuevos se envían a dos instancias de base de datos diferentes. Por lo tanto, puede haber latencia hasta que la instancia de base de datos en espera alcance el ritmo de la nueva instancia de base de datos principal.
Implemente sus aplicaciones en todas las zonas de disponibilidad. Si una zona de disponibilidad deja de funcionar, las aplicaciones de las otras zonas de disponibilidad seguirán estando disponibles.
Cuando trabaje con una implementación Multi-AZ de SQL Server, recuerde que Amazon RDS crea réplicas para todas las bases de datos de SQL Server de su instancia. Si no desea que determinadas bases de datos tengan réplicas secundarias, configure una instancia de base de datos independiente que no use Multi-AZ para esas bases de datos.
Video de prácticas recomendadas de Amazon RDS for SQL Server
La conferencia de AWS re:Invent de 2019 incluyó una presentación sobre nuevas características y prácticas recomendadas para trabajar con SQL Server en Amazon RDS. Puede ver aquí un vídeo de la presentación:
Trabajo con los grupos de parámetros de base de datos
Es recomendable que pruebe los cambios de los grupos de parámetros de base de datos en una instancia de base de datos de prueba antes de aplicarlos en las instancias de base de datos de producción. Si se configuran de forma incorrecta los parámetros del motor de base de datos de un grupo de parámetros de base de datos, pueden producirse efectos adversos no deseados, como la degradación del desempeño y la inestabilidad del sistema. Tenga cuidado siempre que modifique los parámetros del motor de base de datos y cree una copia de seguridad de la instancia de base de datos antes de modificar un grupo de parámetros de base de datos.
Para obtener información acerca del procedimiento para realizar la copia de seguridad de la instancia de base de datos, consulte Copia de seguridad, restauración y exportación de datos.
Prácticas recomendadas para automatizar la creación de instancias de base de datos
Es una práctica recomendada de Amazon RDS crear una instancia de base de datos con la versión secundaria preferida del motor de base de datos. Puede utilizar la AWS CLI, la API de Amazon RDS o la AWS CloudFormation para automatizar la creación de una instancia de base de datos. Cuando utiliza estos métodos, solo puede especificar la versión principal y Amazon RDS crea automáticamente la instancia con la versión secundaria preferida. Por ejemplo, si PostgreSQL 12.5 es la versión secundaria preferida y si especifica la versión 12 con create-db-instance, la instancia de base de datos será la versión 12.5.
Para determinar la versión secundaria preferida, puede ejecutar el comando describe-db-engine-versions con la opción --default-only que se muestra en el siguiente ejemplo.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
Para obtener información sobre la creación de instancias de base de datos mediante programación, consulte los siguientes recursos:
Uso de la AWS CLI: create-db-instance
Uso de la API de Amazon RDS–: CreateDBInstance
Uso de AWS CloudFormation: AWS::RDS::DBInstance
Vídeo de nuevas características de Amazon RDS
La conferencia de AWS re:Invent de 2023 incluyó una presentación sobre nuevas características de Amazon RDS. Puede ver aquí un vídeo de la presentación:
