Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Puoi utilizzare il connettore dati Amazon Athena per un metastore Hive esterno per interrogare set di dati in Amazon S3 che utilizzano un metastore Apache Hive. Non è necessaria alcuna migrazione dei metadati verso. AWS Glue Data Catalog Nella console di gestione di Athena, configura una funzione Lambda per comunicare con il metastore Hive nel VPC privato e quindi collegala al metastore. La connessione da Lambda al metastore Hive è protetta da un canale Amazon VPC privato e non utilizza la rete Internet pubblica. Puoi fornire il tuo codice di funzione Lambda, oppure puoi utilizzare l'implementazione predefinita del connettore dati Athena per un metastore Hive esterno.
Argomenti
Usa il AWS Serverless Application Repository per implementare un connettore di origine dati Hive
Connect Athena a un metastore Hive utilizzando un ruolo di esecuzione IAM esistente
Configurazione di Athena per l'utilizzo di un connettore Hive Metastore distribuito
Ometti il nome del catalogo nelle query esterne del metastore Hive
Panoramica delle caratteristiche
Con il connettore dati Athena per un metastore Hive esterno, puoi svolgere le seguenti attività:
-
Utilizzare la console Athena per registrare cataloghi personalizzati ed eseguire query che li utilizzano.
-
Definire le funzioni Lambda per diversi metastore Hive esterni e unirle nelle query Athena.
-
Usa AWS Glue Data Catalog i tuoi metastore Hive esterni nella stessa query Athena.
-
Specificare un catalogo nel contesto di esecuzione della query come catalogo predefinito corrente. In questo modo viene rimosso il requisito di anteporre i nomi dei cataloghi ai nomi dei database nelle query. Invece di usare la sintassi
catalog.database.tabledatabase.table -
Utilizzare una varietà di strumenti per eseguire query che fanno riferimento a metastore Hive esterni. È possibile utilizzare la console Athena, l' AWS CLI AWS SDK, Athena e i driver Athena JDBC APIs e ODBC aggiornati. I driver aggiornati supportano i cataloghi personalizzati.
Supporto API
Il connettore Athena Data per il metastore Hive esterno include il supporto per le operazioni API di registrazione del catalogo e le operazioni API relative ai metadati.
-
Registrazione catalogo: registrare cataloghi personalizzati per metastore Hive esterni e origini dati federate.
-
Metadati: utilizza i metadati APIs per fornire informazioni su database e tabelle per AWS Glue qualsiasi catalogo registrato con Athena.
-
Client Athena JAVA SDK: utilizza la registrazione del catalogo APIs, i metadati APIs e il supporto per i cataloghi nell'operazione nel client Athena Java SDK aggiornato.
StartQueryExecution
Implementazione di riferimento
Athena fornisce un'implementazione di riferimento per la funzione Lambda che si connette a metastore Hive esterni. L'implementazione di riferimento è fornita GitHub come progetto open source presso il metastore Athena Hive
L'implementazione di riferimento è disponibile come le seguenti due AWS SAM applicazioni in (SAR). AWS Serverless Application Repository È possibile utilizzare una di queste applicazioni in SAR per creare le proprie funzioni Lambda.
-
AthenaHiveMetastoreFunction— File.jardella funzione Uber Lambda. Un JAR "uber" (noto anche come JAR grasso o JAR con dipendenze) è un.jarche contiene sia un programma Java che le sue dipendenze in un unico file. -
AthenaHiveMetastoreFunctionWithLayer– Livello Lambda e file.jardella funzione Lambda.
Flusso di lavoro
Il diagramma seguente mostra come Athena interagisce con il metastore Hive esterno.
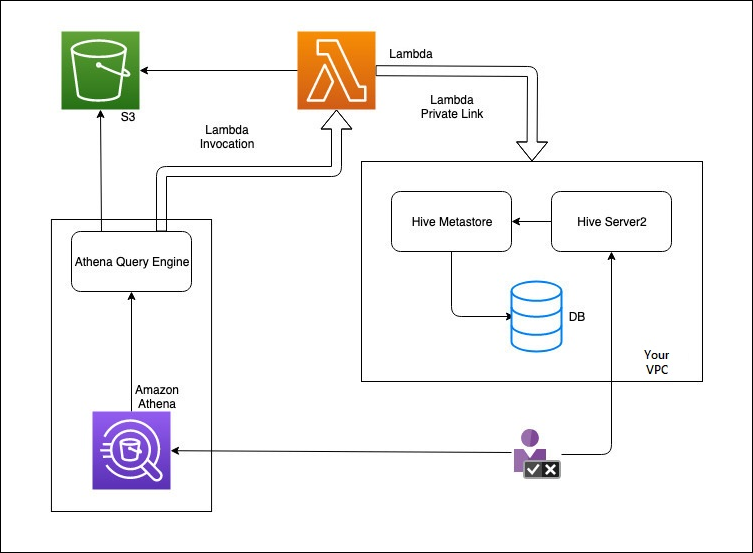
In questo flusso di lavoro, il metastore Hive connesso al database si trova all'interno del VPC. È possibile utilizzare Hive Server2 per gestire il metastore Hive utilizzando l'interfaccia CLI di Hive.
Il flusso di lavoro per l'utilizzo di metastore Hive esterni da Athena include i passaggi seguenti.
-
Si crea una funzione Lambda che connette Athena al metastore Hive che si trova all'interno del VPC.
-
Si registra un nome di catalogo univoco per il metastore Hive e un nome di funzione corrispondente nell'account.
-
Quando si esegue una query DML o DDL Athena che utilizza il nome del catalogo, il motore di query Athena chiama il nome della funzione Lambda associato al nome del catalogo.
-
Utilizzando AWS PrivateLink, la funzione Lambda comunica con il metastore Hive esterno nel tuo VPC e riceve risposte alle richieste di metadati. Athena usa i metadati dal metastore Hive esterno proprio come usa i metadati dalla AWS Glue Data Catalog predefinita.
Considerazioni e limitazioni
Quando si utilizza Athena Data Connector per il metastore Hive esterno, considerare i seguenti punti:
-
Puoi utilizzare CTAS per creare una tabella su un metastore Hive esterno.
-
Puoi utilizzare INSERT INTO per inserire dati in un metastore Hive esterno.
-
Il supporto DDL per il metastore Hive esterno è limitato alle seguenti istruzioni.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
Il numero massimo di cataloghi registrati che è possibile avere è 1.000.
-
L'autenticazione Kerberos per metastore Hive non è supportata.
-
Per utilizzare il driver JDBC con un metastore Hive esterno o query federate, includi
MetadataRetrievalMethod=ProxyAPInella stringa di connessione JDBC. Per informazioni sul driver JDBC, consulta Connect ad Amazon Athena con JDBC. -
Le colonne nascoste di Hive
$path,$bucket,$file_size,$file_modified_time,$partitione$row_idnon possono essere utilizzate per filtrare con il controllo granulare degli accessi. -
Le tabelle di sistema Hive nascoste, come
example_table$partitionsexample_table$properties
Autorizzazioni
I connettori dati precompilati e personalizzati potrebbero richiedere l'accesso alle seguenti risorse per funzionare correttamente. Controlla le informazioni relative al connettore utilizzato per assicurarti di aver configurato correttamente il VPC. Per informazioni sulle autorizzazioni IAM obbligatorie per eseguire query e creare un connettore origine dati in Athena, consulta Consenti l'accesso a Athena Data Connector for External Hive Metastore e Consentire l'accesso alla funzione Lambda a metastore Hive esterni.
-
Amazon S3 — Oltre a scrivere i risultati delle query nella posizione dei risultati della query Athena in Amazon S3, i connettori di dati scrivono anche in un bucket di spill in Amazon S3. Sono richieste connettività e autorizzazioni a questa posizione Amazon S3. Per ulteriori informazioni, consulta Posizione spill in Amazon S3 più avanti in questo argomento.
-
Athena – L'accesso è necessario per controllare lo stato della query e impedire l'overscan.
-
AWS Glue— L'accesso è necessario se il connettore utilizza metadati supplementari o primari. AWS Glue
-
AWS Key Management Service
-
Criteri: Hive metastore, Athena Query Federation e UDFs richiedono politiche oltre a. AWS politica gestita: AmazonAthenaFullAccess Per ulteriori informazioni, consulta Gestione dell'identità e dell'accesso in Athena.
Posizione spill in Amazon S3
A causa del limite relativo alle dimensioni delle risposte delle funzioni Lambda, le risposte superiori alla soglia si riversano in una posizione Amazon S3 specificata al momento della creazione della funzione Lambda. Athena legge direttamente queste risposte da Amazon S3.
Nota
Athena non rimuove i file di risposta su Amazon S3. Ti consigliamo di impostare una policy di conservazione per eliminare automaticamente i file di risposta.
