翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Keyspaces: 仕組み
Amazon Keyspaces では、Cassandra の管理にかかる管理オーバーヘッドが取り除かれます。その理由を理解するには、Cassandra アーキテクチャについて調べた上で Amazon Keyspaces と比較するとよいでしょう。
トピック
高レベルのアーキテクチャ: Apache Cassandra と Amazon Keyspaces の比較
従来の Apache Cassandra は 1 つ以上のノードで構成されるクラスターにデプロイされます。各ノードの管理と、クラスターのスケールに応じたノードの追加および削除は、ユーザーに責任があります。
クライアントプログラムは、いずれかのノードに接続して Cassandra クエリ言語 (CQL) ステートメントを発行することにより Cassandra にアクセスします。CQL は、リレーショナルデータベースで使用される一般的な言語である SQL に似ています。Cassandra はリレーショナル・データベースではありませんが、CQL は Cassandra 内のデータのクエリと操作のための使い慣れたインタフェースを提供します。
次の図は、4 つのノードで構成されるシンプルな Apache Cassandra クラスターを示しています。

本番稼働用の Cassandra のデプロイは、1 つまたは複数の物理データセンターで数百台の物理コンピュータ上で動作する数百のノードで構成されている可能性があります。ソフトウェアのインストール、保守、および運用に加えて、サーバーのプロビジョニング、パッチ適用、管理を行わなければならないアプリケーションデベロッパーに、運用上の負担がかかる可能性があります。
Amazon Keyspaces (Apache Cassandra 向け) では、サーバーのプロビジョニング、パッチ適用、管理が不要なため、より優れたアプリケーションを構築することに集中できます。Amazon Keyspaces では、読み取りと書き込みの 2 つのスループットキャパシティモード (オンデマンドとプロビジョニング) があります。テーブルのスループットキャパシティモードを選択すれば、ワークロードの予測可能性と変動性に基づいて読み取りと書き込みの料金を最適化できます。
オンデマンドモード (デフォルト) - アプリケーションにより実行される実際の読み取りと書き込みに対してのみ料金が発生します。テーブルのスループットキャパシティを事前に指定する必要はありません。Amazon Keyspaces は、アプリケーショントラフィックの上昇と下降にほぼ瞬時に対応するため、トラフィックが予測不能であるアプリケーションに適しています。
プロビジョンドキャパシティモードでは、予測可能なアプリケーショントラフィックがあり、テーブルのキャパシティ要件を事前に予測できる場合に、スループットの料金を最適化できます。プロビジョンドキャパシティモードを使用する場合、アプリケーションに必要な 1 秒あたりの読み取り回数と書き込み回数を指定します。オートスケーリングを有効にすると、テーブルのプロビジョンドキャパシティが自動的に調整されます。
ワークロードのトラフィックパターンについて詳しく学んだとおり、大量のテーブルトラフィックの発生が予想される主要なイベントなど、トラフィックの大幅なバーストが予想される場合は、テーブルのキャパシティモードを 1 日 1 回変更することができます。読み取り/書き込みキャパシティのプロビジョニングについては、「Amazon Keyspaces で読み取り/書き込みのキャパシティモードを設定する」を参照してください。
Amazon Keyspaces (Apache Cassandra 向け) では、耐久性と高可用性のために、3 つのデータコピーが複数のアベイラビリティーゾーン
Amazon Keyspaces のアーキテクチャを次の図に示します。
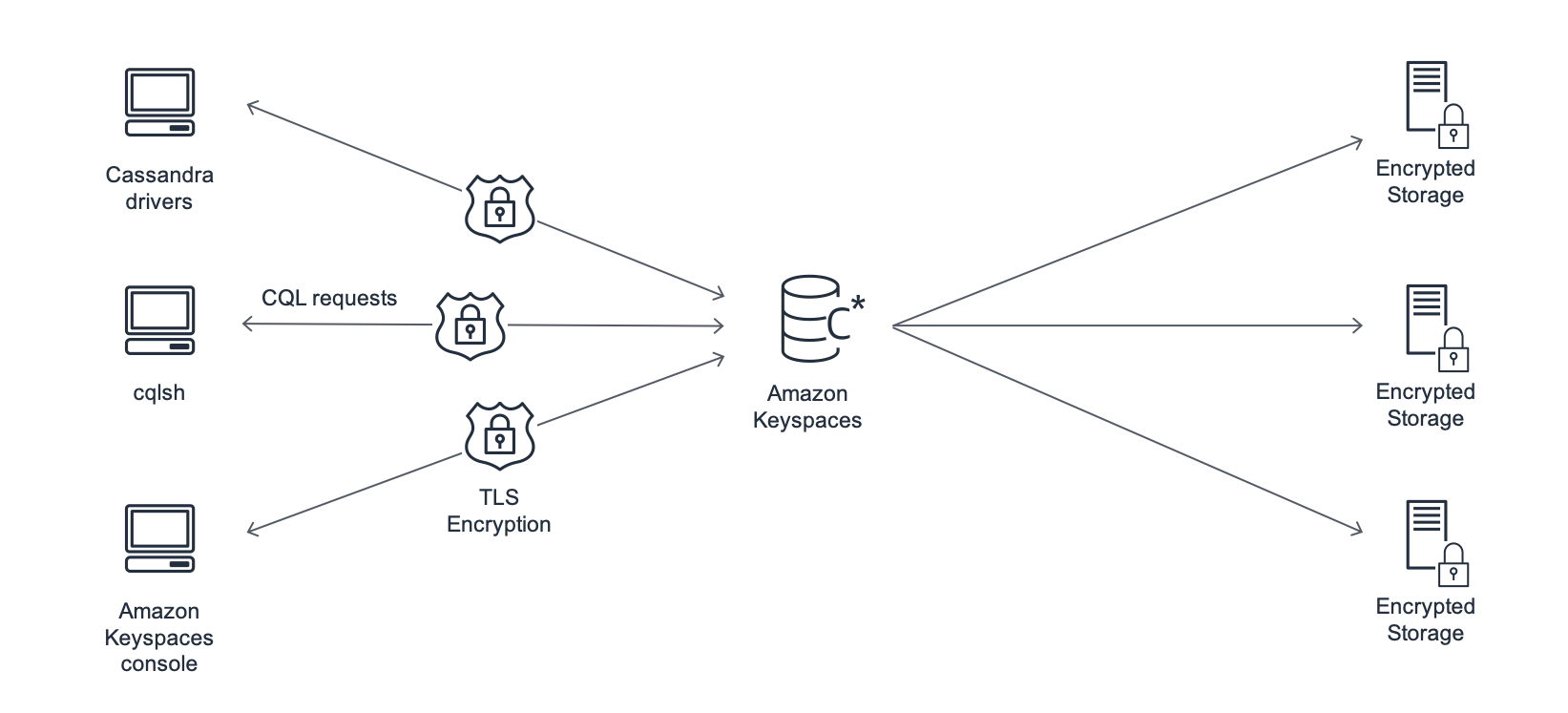
クライアントプログラムは、事前に定義されたエンドポイント (ホスト名とポート番号) に接続し、CQL ステートメントを発行して、 Amazon Keyspaces にアクセスします。利用可能なエンドポイントのリストについては、「Amazon Keyspaces のサービスエンドポイント」を参照してください。
Cassandra のデータモデル
Amazon Keyspaces から最適なパフォーマンスの達成を目指す上で、ビジネスケースのデータをどうモデル化するかが重要になります。データモデルが貧弱だとパフォーマンスが大幅に低下する可能性があります。
CQL は SQL に似ていますが、Cassandra とリレーショナルデータベースではバックエンドが大きく異なっているため、別の方法でアプローチする必要があります。次に、考慮すべき重要な問題をいくつか取り上げます。
- [Storage (ストレージ)]
-
テーブルで Cassandra データを可視化することができます。各行はレコードを表し、各列はそのレコード内のフィールドを表します。
- テーブルデザイン: クエリ重視
-
CQL には
JOINがありません。したがって、データの形状と、ビジネスユースケースのためにデータにどうアクセスする必要があるかを考慮して、テーブルを設計する必要があります。これにより、重複データがある非正規化が生じる可能性があります。各テーブルを特定のアクセスパターンに合わせて設計する必要があります。 - パーティション
-
データはディスク上のパーティションに保存されます。データが保存されているパーティションの数とパーティション間でデータの分散状況は、パーティションキーによって決まります。パーティションキーの定義方法は、クエリのパフォーマンスに大きな影響を与える可能性があります。ベストプラクティスについては、Amazon Keyspaces でパーティションキーを効果的に使用する方法を参照してください。
- プライマリキー
-
Cassandra では、データはキーバリューペアとして保存されます。Cassandra のすべてのテーブルには、テーブルの各行を一意に識別するプライマリキーが必要です。プライマリキーは、必須のパーティションキー 1 つと、オプションのクラスタリング列 1 つ以上で構成されます。プライマリキーを構成するデータは、テーブルのすべてのレコードに対して一意でなければなりません。
-
パーティションキー — プライマリキーのパーティションキー部分は必須で、データが保存されるクラスターのパーティションを決定します。パーティションキーは、1 つの列である場合もあれば、2 つ以上の列で構成される複合値である場合もあります。単一列パーティションキーを使用すると、ほとんどのデータが単一のパーティションまたは非常に少数のパーティションに保存され、そのためにディスク I/O オペレーションの大部分を単一列パーティションキーが占める結果となる場合は、複合パーティションキーを使用した方がよいでしょう。
-
クラスタリング列 – プライマリキーのオプションのクラスタリング列部分は、各パーティションにおけるデータのクラスター処理方法とソート方法を決定するものです。プライマリキーにクラスタリング列を含めると、クラスタリング列には 1 つ以上の列が存在します。クラスタリング列内に複数の列が存在する場合、クラスタリング列内の列の順序 (左から右) によってソート順序が決まります。
-
NoSQL 設計と Amazon Keyspaces の詳細については、「NoSQL 設計の主な相違点と設計原則」を参照してください。Amazon Keyspaces およびデータモデリングの詳細については、「データモデリングのベストプラクティス: データモデル設計時の推奨事項」を参照してください。
アプリケーションからの Amazon Keyspaces へのアクセス
すでに使用している CQL および Cassandra ドライバーを使用できるように、Amazon Keyspaces (Apache Cassandra 向け) には Apache Cassandra クエリ言語 (CQL) API が実装されています。アプリケーションの更新は、Cassandraドライバーの更新や、Amazon Keyspaces サービスエンドポイントを指すための cqlsh 設定と同じくらい簡単です。必要な認証情報の詳細については、「Amazon Keyspaces の AWS 認証情報の作成と設定」を参照してください。
注記
開始にあたっては、GitHub
次の Python プログラムで Cassandra クラスターに接続してテーブルをクエリする場合を考えてみましょう。
from cassandra.cluster import Cluster #TLS/SSL configuration goes here ksp = 'MyKeyspace' tbl = 'WeatherData' cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN) session = cluster.connect(ksp) session.execute('USE ' + ksp) rows = session.execute('SELECT * FROM ' + tbl) for row in rows: print(row)
Amazon Keyspaces に対して同じプログラムを実行するには、次の作業を行う必要があります。
-
クラスターのエンドポイントとポートの追加: 例えば、ホストを
cassandra.us-east-1.amazonaws.comやポート番号9142などのサービスエンドポイントに置き換えることができます。 -
TLS/SSL 設定の追加: Cassandra クライアントの Python ドライバーを使用して Amazon Keyspaces に接続するための TLS/SSL 設定の追加については、「Cassandra Python クライアントドライバーを使用した Amazon Keyspaces へのプログラムアクセス」を参照してください。
