翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Neptune ML 特徴の使い方の概要
Amazon Neptune の Neptune ML 機能は、グラフデータベース内の機械学習モデルを活用するための合理化されたワークフローを提供します。このプロセスには、Neptune から CSV 形式にデータをエクスポートする、データを前処理してモデルトレーニングの準備する、Amazon SageMaker AI を使用して機械学習モデルをトレーニングする、予測を処理する推論エンドポイントを作成する、Gremlin クエリから直接モデルをクエリする、といういくつかの重要なステップが含まれます。Neptune ワークベンチは、これらのステップの管理と自動化に役立つ便利なラインマジックコマンドとセルマジックコマンドを提供します。Neptune ML は、機械学習の機能をグラフデータベースに直接統合することで、Neptune グラフに保存されている豊富なリレーショナルデータを使用して貴重なインサイトを取得し、予測を行うことができます。
Neptune ML を使用するためのワークフローの開始
Amazon Neptune で Neptune ML 特徴を使用するには、通常、まず次の 5 つの手順が必要です。
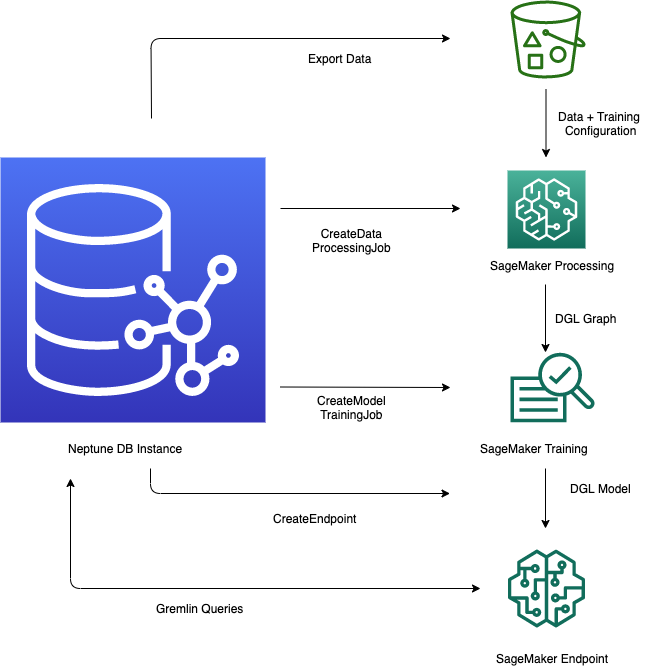
-
データのエクスポートと設定 — データエクスポートステップでは、Neptune-Export サービスまたはNeptune から Amazon Simple Storage Service (Amazon S3) にデータを CSV 形式でエクスポートするための
neptune-exportコマンドラインツールを使用します。training-data-configuration.jsonという構成ファイルが同時に自動的に生成されます。これにより、エクスポートされたデータをトレーニング可能なグラフにロードする方法が指定されます。 -
データの前処理 — このステップでは、エクスポートされたデータセットは標準的な手法を使用して前処理され、モデルトレーニング用に準備されます。数値データに対して特徴の正規化を実行でき、テキスト特徴は
word2vecを使用して符号化できます。この手順の最後に、エクスポートされたデータセットから DGL (ディープグラフライブラリ) グラフが生成され、モデルトレーニングステップで使用できるようになります。この手順は、アカウントの SageMaker AI 処理ジョブを使用して実装され、結果のデータは指定した Amazon S3 ロケーションに保存されます。
-
モデルトレーニング — モデルトレーニングステップは、予測に使用される機械学習モデルをトレーニングします。
モデルトレーニングは、次の2つの段階で行われます。
最初のステージでは、SageMaker AI 処理ジョブを使用して、モデルトレーニングに使用するモデルおよびモデルのハイパーパラメータ範囲のタイプを指定するモデルトレーニング戦略構成セットを生成します。
次に、第 2 段階では SageMaker AI モデルチューニングジョブを使用して、さまざまなハイパーパラメータ構成を試し、最もパフォーマンスの高いモデルを生成したトレーニングジョブを選択します。チューニングジョブは、処理されたデータに対して事前に指定された数のモデルトレーニングジョブ試行を実行します。このステージの最後に、最適なトレーニングジョブのトレーニング済みモデルパラメータを使用して、推論のためのモデルアーティファクトを生成します。
-
Amazon SageMaker AI で推論エンドポイントを作成する — 推論エンドポイントは、最適なトレーニングジョブによって生成されたモデルアーティファクトで起動される SageMaker AI エンドポイントインスタンスです。各モデルは 1 つのエンドポイントに関連付けられています。エンドポイントは、グラフデータベースからの受信リクエストを受け入れ、リクエストの入力に対するモデル予測を返すことができます。エンドポイントを作成した後も、削除するまでアクティブなままになります。
Gremlin を使用して機械学習モデルを照会する — Gremlin クエリ言語の拡張機能を使用して、推論エンドポイントから予測を照会できます。
注記
Neptune workbench ラインマジックとセルマジックが含まれており、これらの手順の管理に多大な時間を節約できます。
