Como usar índices secundários globais no DynamoDB
Alguns aplicativos talvez precisem executar muitos tipos de consultas, usando uma variedade de atributos diferentes como critérios de consulta. Para oferecer suporte a esses requisitos, você pode criar um ou mais índices secundários globais e emitir solicitações Query para esses índices no Amazon DynamoDB.
Tópicos
Sincronização de dados entre tabelas e índices secundários globais
Considerações sobre throughput provisionado para índices secundários globais
Considerações sobre armazenamento para índices secundários globais
Detectar e corrigir violações de chave de índice no DynamoDB
Trabalhar com índices secundários globais no DynamoDB usando a AWS CLI
Cenário: Uso de um índice secundário global
Para ilustrar, considere uma tabela chamada GameScores que controla os usuários e os placares de um aplicativo de jogo móvel. Cada item em GameScores é identificado por uma chave de partição (UserId) e por uma chave de classificação (GameTitle). O diagrama a seguir mostra como os itens da tabela seriam organizados. (Nem todos os atributos são mostrados.)
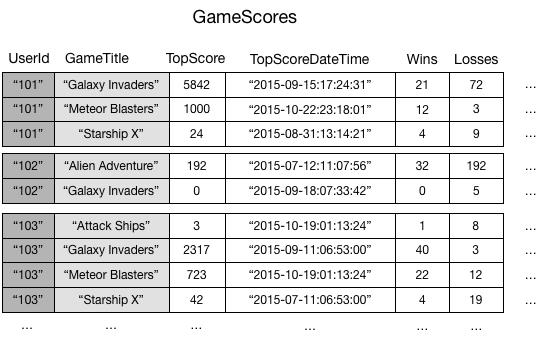
Agora, vamos supor que você quisesse gravar um aplicativo de placar para exibir as pontuações máximas de cada jogo. Uma consulta que especificasse os atributos chave (UserId e GameTitle) seria muito eficaz. No entanto, se o aplicativo precisasse recuperar dados de GameScores com base no GameTitle apenas, ele precisaria usar uma operação Scan. À medida que mais itens são adicionados à tabela, as verificações de todos os dados se tornam lentas e ineficientes. Isso dificulta responder a questões como as seguintes:
-
Qual é a pontuação máxima já registrada no jogo Meteor Blasters?
-
Qual usuário tinha a maior pontuação no Galaxy Invaders?
-
Qual era a maior proporção de vitórias versus derrotas?
Para acelerar as consultas em atributos que não são chave, você pode criar um índice secundário global. Um índice secundário global contém uma seleção de atributos da tabela-base, mas eles são organizados por uma chave primária que é diferente daquela da região da tabela. A chave do índice não precisa ter nenhum dos atributos de chaves da tabela. Ela não precisa nem ter o mesmo esquema de chaves que a tabela.
Por exemplo, você poderia criar um índice secundário global chamado GameTitleIndex com uma chave de partição GameTitle e uma chave de classificação TopScore. Os atributos de chave primária da tabela base são sempre projetados em um índice, portanto, o atributo UserId também está presente. O diagrama a seguir mostra qual é a aparência do índice GameTitleIndex.
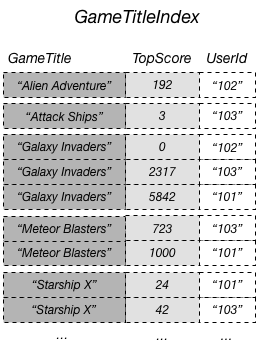
Agora você pode consultar GameTitleIndex e obter as pontuações do jogo Meteor Blasters com facilidade. Os resultados são ordenados por valores de chave de classificação, TopScore. Se você definir o parâmetro ScanIndexForward como falso, os resultados serão retornados em ordem decrescente, de modo que a maior pontuação é retornada primeiro.
Cada índice secundário global deve ter uma chave de partição e pode ter uma chave de classificação opcional. O esquema da chave de índice pode ser diferente do esquema da tabela base. Você poderia ter uma tabela com uma chave primária simples (chave de partição) e criar um índice secundário global com uma chave primária composta (chave de partição e chave de classificação), ou vice versa. Os atributos de chaves do índice podem consistir em quaisquer atributos de nível superior, String, Number ou Binary da tabela base. Outros tipos escalares, tipos de documento e tipos de conjunto não são permitidos.
Você pode projetar outros atributos da tabela-base para o índice, se quisesse. Quando você consultar o índice, o DynamoDB poderá recuperar esses atributos projetados com eficiência. No entanto, as consultas do índice secundário global buscam atributos da tabela-base. Por exemplo, se você consultar GameTitleIndex conforme mostrado no diagrama anterior, a consulta poderá não acessar nenhum atributo que não seja de chave além de TopScore (embora os atributos de chave GameTitle e UserId sejam projetados automaticamente).
Em uma tabela do DynamoDB, cada valor de chave deve ser exclusivo. No entanto, os valores de chave em um índice secundário global não precisam ser exclusivos. Para ilustrar, suponhamos que um jogo chamado Comet Quest seja muito difícil. Há vários novos usuários tentando obter uma pontuação acima de zero, mas não conseguem. Veja a seguir alguns dos dados que podem representar isso.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
Quando esses dados são adicionados à tabela GameScores, o DynamoDB os propaga para o GameTitleIndex. Se consultarmos o índice usando Comet Quest para GameTitle e 0 para TopScore, os seguintes dados serão retornados.
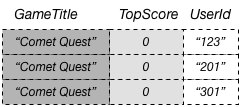
Apenas os itens com os valores de chaves especificados aparecem na resposta. Nesse conjunto de dados, os itens não estão em nenhuma ordem específica.
Um índice secundário global controla apenas os itens de dados em que seus atributos de chave realmente existem. Por exemplo, suponha que você tenha adicionado um novo item à tabela GameScores, mas forneceu somente os atributos de chave primária necessários.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Como você não especificou o atributo TopScore, o DynamoDB não propagará esse item para GameTitleIndex. Portanto, se você tivesse consultado GameScores para obter todos os itens do Comet Quest, obteria os quatro itens a seguir.
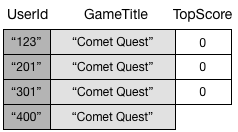
Uma consulta semelhante em GameTitleIndex ainda retornaria três itens, em vez de quatro. Isso acontece porque o item com TopScore inexistente não é propagado para o índice.
Projeções de atributo
Uma projeção é o conjunto de atributos que é copiado de uma tabela para um índice secundário. A chave de partição e a chave de classificação da tabela são sempre projetadas no índice; você pode projetar outros atributos para suportar os requisitos de consulta da sua aplicação. Quando você consulta um índice, o Amazon DynamoDB pode acessar quaisquer atributos na projeção como se estivessem em uma tabela própria.
Quando você cria um índice secundário, é necessário especificar os atributos que serão projetados no índice. O DynamoDB proporciona três opções diferentes para fazer isso:
-
KEYS_ONLY: cada item do índice consiste apenas nos valores de chaves de partição e nas chaves de classificação da tabela, além dos valores de chaves do índice. A opção
KEYS_ONLYresulta no menor índice secundário possível. -
INCLUDE: além dos atributos descritos em
KEYS_ONLY, o índice secundário incluirá outros atributos não chave que você especificar. -
ALL: o índice secundário inclui todos os atributos da tabela de origem. Como todos os dados da tabela são duplicados no índice, uma projeção
ALLresulta no maior índice secundário possível.
No diagrama anterior, GameTitleIndex tem apenas um atributo projetado: UserId Portanto, embora um aplicativo possa determinar eficientemente o UserId dos melhores marcadores para cada jogo usando GameTitle e TopScore nas consultas, ele não pode determinar com eficiência a maior proporção de vitórias versus derrotas dos maiores marcadores. Para fazer isso, a aplicação teria que realizar uma consulta adicional na tabela base para buscar os ganhos e perdas de cada um dos maiores artilheiros. A maneira mais eficiente de oferecer suporte a consultas nesses dados seria projetar esses atributos da tabela-base no índice secundário global, conforme mostrado neste diagrama.
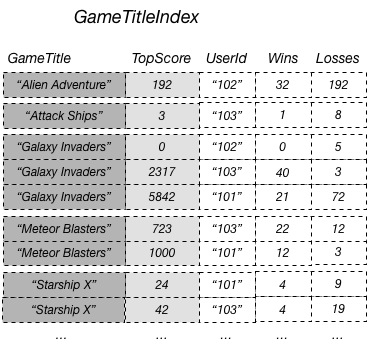
Como os atributos não são de chave Wins e Losses são projetados no índice, um aplicativo pode determinar a proporção de vitórias versus derrotas de qualquer jogo ou de qualquer combinação de jogo e ID do usuário.
Ao escolher os atributos para projetar em um índice secundário global, você deve considerar a desvantagem entre os custos de throughput provisionado e os custos de armazenamento:
-
Se você precisar acessar apenas alguns atributos com a latência mais baixa possível, considere projetar apenas os atributos em um índice secundário global. Quanto menor o índice, menores serão os custos de armazenamento e de gravação.
-
Se sua aplicação acessar frequentemente alguns atributos não chave, considere projetar esses atributos em um índice secundário global. Os custos adicionais de armazenamento do índice secundário global compensarão o custo de executar verificações de tabelas frequentes.
-
Se precisar acessar a maioria dos atributos não chave com frequência, você poderá projetar esses atributos, inclusive a tabela-base inteira, em um índice secundário global. Isso dá flexibilidade máxima a você. No entanto, o custo do armazenamento aumentará ou até dobrará.
-
Se o aplicativo precisar consultar uma tabela com pouca frequência, mas precisar executar muitas gravações ou atualizações nos dados da tabela, considere projetar
KEYS_ONLY. O índice secundário global seria de tamanho mínimo, mas ainda estaria disponível quando necessário para a atividade de consulta.
Esquema de chave de vários atributos
Os índices secundários globais são compatíveis com chaves de vários atributos, permitindo que você componha chaves de partição e chaves de classificação com base em vários atributos. Com chaves de vários atributos, você pode criar uma chave de partição com até quatro atributos e uma chave de classificação com até quatro atributos, totalizando até oito atributos por esquema de chave.
As chaves de vários atributos simplificam seu modelo de dados, eliminando a necessidade de concatenar manualmente os atributos em chaves sintéticas. Em vez de criar strings compostas, como TOURNAMENT#WINTER2024#REGION#NA-EAST, você pode usar diretamente os atributos naturais do seu modelo de domínio. O DynamoDB processa a lógica da chave composta automaticamente, unindo vários atributos da chave de partição para distribuição de dados e mantendo a ordem de classificação hierárquica em vários atributos da chave de classificação.
Por exemplo, considere um sistema de torneios de jogos em que você deseja organizar partidas por torneio e região. Com chaves de vários atributos, você pode definir sua chave de partição como dois atributos separados: tournamentId e region. Da mesma forma, você pode definir sua chave de classificação usando vários atributos, como round, bracket e matchId, para criar uma hierarquia natural. Essa abordagem mantém seus dados tipados e seu código limpo, sem manipulação nem análise de strings.
Quando você consulta um índice secundário global com chaves de vários atributos, deve especificar todos os atributos da chave de partição usando condições de igualdade. Em relação a atributos de chave de classificação, é possível consultá-los da esquerda para a direita na ordem em que estão definidos no esquema de chaves. Isso significa que você pode consultar o primeiro atributo da chave de classificação sozinho, os dois primeiros atributos juntos ou todos os atributos juntos, mas não pode ignorar os atributos no meio. Condições de desigualdade, como >, <, BETWEEN ou begins_with(), devem ser a última condição em sua consulta.
As chaves de vários atributos funcionam particularmente bem quando você cria índices secundários globais em tabelas existentes. Você pode usar atributos que já existem na sua tabela sem precisar preencher chaves sintéticas em todos os seus dados. Isso facilita a inclusão de novos padrões de consulta à sua aplicação criando índices que reorganizam seus dados usando diferentes combinações de atributos.
Cada atributo em uma chave de vários atributos pode ter seu próprio tipo de dados: String (S), Number (N) ou Binary (B). Quando você escolhe os tipos de dados, pense que os atributos Number são classificados numericamente sem exigir preenchimento zero, enquanto os atributos String são classificados de modo lexicográfico. Por exemplo, se você usar um tipo Number para um atributo de pontuação, os valores 5, 50, 500 e 1000 serão classificados em ordem numérica natural. Os mesmos valores, se fossem do tipo String, seriam ordenados como “1000”, “5”, “50”, “500”, a menos que você os preenchesse com zeros à esquerda.
Ao criar chaves de vários atributos, ordene seus atributos do mais geral para o mais específico. Para chaves de partição, combine atributos que são sempre consultados juntos e que oferecem uma boa distribuição de dados. Para chaves de classificação, coloque os atributos frequentemente consultados em primeiro lugar na hierarquia para maximizar a flexibilidade da consulta. Essa ordenação permite que você consulte em qualquer nível de granularidade que corresponda aos seus padrões de acesso.
Consulte exemplos de implementação em Chaves de vários atributos.
Ler dados de um índice secundário global
Você pode recuperar itens de um índice secundário global usando as operações Query e Scan. As operações GetItem e BatchGetItem não podem ser usadas em um índice secundário global.
Como consultar um índice secundário global
Você pode usar a operação Query para acessar um ou mais itens em um índice secundário global. A consulta deve especificar o nome da tabela-base e o nome do índice que você deseja usar, os atributos a serem retornados nos resultados de consulta e quaisquer condições que você deseja aplicar. O DynamoDB pode retornar os resultados em ordem crescente ou decrescente.
Considere os seguintes dados retornados de uma Query que solicita dados de jogos para um aplicativo de placar.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
Nesta consulta:
-
O DynamoDB acessa GameTitleIndex usando a chave de partição GameTitle para localizar os itens de índice do Meteor Blasters. Todos os itens do índice com essa chave são armazenados lado a lado para rápida recuperação.
-
Nesse jogo, o DynamoDB usa o índice para acessar todos os IDs de usuário e as pontuações máximas.
-
Os resultados são retornados, classificados em ordem decrescente, pois o parâmetro
ScanIndexForwardestá definido como falso.
Como verificar um índice secundário global
Você pode usar a operação Scan para recuperar todos os dados de um índice secundário global. Você deve fornecer o nome da tabela-base e o nome de índice na solicitação. Com uma operação Scan, o DynamoDB lê todos os dados do índice e os retorna para a aplicação. Você também pode solicitar que apenas alguns dos dados sejam retornados, e que os dados restantes sejam descartados. Para fazer isso, use o parâmetro FilterExpression da operação Scan. Para obter mais informações, consulte Expressões de filtro para verificação.
Sincronização de dados entre tabelas e índices secundários globais
O DynamoDB sincroniza automaticamente cada índice secundário global com sua tabela-base. Quando uma aplicação grava ou exclui itens em uma tabela, quaisquer índices secundários globais nessa tabela são atualizados de forma assíncrona usando um modelo final consistente. Os aplicativos nunca gravam diretamente em um índice. No entanto, é importante compreender as implicações de como o DynamoDB mantém esses índices.
Índices secundários globais herdam o modo de capacidade leitura/gravação da tabela base. Para obter mais informações, consulte Considerações ao alternar os modos de capacidade no DynamoDB.
Ao criar um índice secundário global, você especifica um ou mais atributos de chave de índice e seus tipos de dados. Isso significa que sempre que você grava um item na tabela-base, os tipos de dados desses atributos devem corresponder aos tipos de dados do esquema de chaves do índice. No caso de GameTitleIndex, a chave de partição GameTitle no índice é definida como um tipo de dados String. A chave de classificação TopScore no índice é do tipo Number. Se você tentar adicionar um item à tabela GameScores e especificar um tipo de dados diferente para GameTitle ou TopScore, o DynamoDB retornará uma ValidationException devido à inconsistência do tipo de dados.
Quando você insere ou exclui itens em uma tabela, os índices secundários globais dessa tabela são atualizados de uma forma eventualmente consistente. As alterações na tabela são propagadas para os índices secundários globais em uma fração de segundo, sob condições normais. No entanto, em alguns cenários improváveis de falha, podem ocorrer atrasos de propagação mais longos. Consequentemente, as aplicações precisam prever e lidar com situações em que uma consulta em um índice secundário global retorna resultados que não estão atualizados.
Se você gravar um item em uma tabela, não será necessário especificar os atributos para qualquer chave de classificação do índice secundário global. Usando GameTitleIndex como um exemplo, você não precisa especificar um valor para o atributo TopScore para gravar um novo item na tabela GameScores. Neste caso, o DynamoDB não grava todos os dados no índice deste item específico.
Os custos das atividades de gravação em uma tabela com muitos índices secundários serão mais altos do que em uma tabela com um número menor de índices. Para obter mais informações, consulte Considerações sobre throughput provisionado para índices secundários globais.
Classes de tabela com índice secundário global
Um índice secundário global sempre usará a mesma classe de tabela que sua tabela-base. Sempre que um novo índice secundário global for adicionado para uma tabela, o novo índice usará a mesma classe de tabela que sua tabela base. Quando a classe de tabela de uma tabela é atualizada, todos os índices secundários globais associados também são atualizados.
Considerações sobre throughput provisionado para índices secundários globais
Ao criar um índice secundário global em uma tabela de modo provisionado, você deve especificar unidades de capacidade de leitura e gravação para a workload esperada no índice. As configurações de throughput provisionado de um índice secundário global são separadas daquelas de sua tabela-base. Uma operação Query em um índice secundário global consome unidades de capacidade de leitura do índice, não da tabela-base. Quando você insere ou exclui itens em uma tabela, os índices secundários globais dessa tabela também são atualizados. Essas atualizações de índice consomem unidades de capacidade do índice, não da tabela base.
Por exemplo, se você usar a operação Query em um índice secundário global e exceder sua capacidade de leitura provisionada, sua solicitação será limitada. Se você executar atividades de gravação pesadas na tabela, mas um índice secundário global da tabela tiver capacidade de gravação insuficiente, a atividade de gravação na tabela será limitada.
Importante
Para evitar o controle de utilização potencial, a capacidade de gravação provisionada para um índice secundário global deve ser igual ou maior que a capacidade de gravação da tabela base, porque as novas atualizações gravarão na tabela base e no índice secundário global.
Para visualizar as configurações de throughput provisionado de um índice secundário global, use a operação DescribeTable. Informações detalhadas sobre todos os índices secundários globais da tabela são retornados.
Unidades de capacidade de leitura
Os índices secundários globais oferecem suporte a leituras eventualmente consistentes, cada uma delas consome metade de uma unidade de capacidade de leitura. Isso significa que uma única consulta de índice secundário global pode recuperar até 2 × 4 KB = 8 KB por unidade de capacidade de leitura.
Para consultas de índice secundário global, o DynamoDB calcula a atividade de leitura provisionada da mesma forma que para consultas em tabelas. A única diferença é que o cálculo é baseado no tamanho das entradas de índice, em vez do tamanho do item na tabela-base. O número de unidades de capacidade de leitura é a soma de todos os tamanhos de atributos projetados em todos os itens retornados. O resultado é arredondado para o próximo limite de 4 KB. Para obter mais informações sobre como o DynamoDB calcula a utilização de throughput provisionado, consulte Modo de capacidade provisionada do DynamoDB.
O tamanho máximo dos resultados retornados por uma operação Query é 1 MB. Isso inclui os tamanhos de todos os nomes e valores de atributos de todos os itens retornados.
Por exemplo, considere um índice secundário global em que cada item contém 2.000 bytes de dados. Agora vamos supor que você use a operação Query nesse índice e que KeyConditionExpression da consulta retorne oito itens. O tamanho total dos itens correspondentes é 2.000 bytes × 8 itens = 16.000 bytes. O resultado é arredondado para o próximo limite de 4 KB. Como as consultas do índice secundário global são finais consistentes, o custo total é 0,5 × (16 KB / 4 KB), ou 2 unidades de capacidade de leitura.
Unidades de capacidade de gravação
Quando um item é adicionado, atualizado ou excluído em uma tabela, e um índice secundário global é afetado por isso, o índice secundário global consome unidades de capacidade de gravação provisionadas para a operação. O custo total do throughput provisionado para uma gravação consiste na soma das unidades de capacidade de gravação consumidas pela gravação na tabela base e pela atualização dos índices secundários globais. Se uma gravação em uma tabela não exigir uma atualização do índice secundário global, nenhuma capacidade de gravação será consumida no índice.
Para que uma gravação de tabela seja bem-sucedida, as configurações do throughput provisionado e todos os seus índices secundários globais devem ter capacidade de gravação suficiente para acomodar a gravação. Caso contrário, a gravação na tabela será limitada.
Importante
Ao criar um índice secundário global (GSI), as operações de gravação na tabela base poderão sofrer controle de utilização se a atividade do GSI resultante das gravações na tabela base exceder a capacidade de gravação provisionada do GSI. Esse controle de utilização afeta todas as operações de gravação, desde o processo de indexação até a possível interrupção de suas workloads de produção. Para ter mais informações, consulte Problemas de controle de utilização no Amazon DynamoDB.
O custo de gravar um item em um índice secundário global depende de vários fatores:
-
Se você gravar um novo item na tabela que define um atributo indexado, ou atualizar um item existente para definir um atributo indexado indefinido anteriormente, uma operação de gravação é necessária para inserir o item no índice.
-
Se uma atualização na tabela alterar o valor de um atributo de chave indexado (de A para B), duas gravações serão necessárias, uma para excluir o item anterior do índice e outra gravação para inserir o novo item no índice.
-
Se um item estava presente no índice, mas uma gravação na tabela fez com que o atributo indexado fosse excluído, uma gravação é necessária para excluir a projeção do item antigo do índice.
-
Se um item não estiver presente no índice antes ou depois que o item é atualizado, não haverá custo de gravação adicionais para o índice.
-
Se uma atualização na tabela alterar somente o valor dos atributos projetados no esquema de chaves do índice, mas não alterar o valores de qualquer atributo de chave indexado, uma gravação será necessária para atualizar os valores dos atributos projetados no índice.
-
Se uma atualização na tabela alterar apenas atributos que não sejam atributos de chave do índice nem estejam projetados no índice, a entrada do índice permanecerá inalterada e nenhuma capacidade de gravação será consumida para esse índice. A tabela base continuará sendo cobrada pela gravação.
Todos esses fatores supõem que o tamanho de cada item no índice seja menor ou igual ao tamanho de item de 1 KB para calcular unidades de capacidade de gravação. Entradas de índice maiores exigirão unidades adicionais de capacidade de gravação. Você pode minimizar os custos de gravação, considerando quais atributos suas consultas precisarão retornar e projetar apenas esses atributos no índice.
Considerações sobre armazenamento para índices secundários globais
Quando uma aplicação grava um item em uma tabela, o DynamoDB copia automaticamente o subconjunto de atributos corretos para qualquer índice secundário global no qual esses atributos devem aparecer. Sua conta da AWS é cobrada pelo armazenamento do item na tabela-base e também pelo armazenamento de atributos em qualquer índice secundário global dessa tabela.
A quantidade de espaço usada por um item do índice é a soma do seguinte:
-
O tamanho em bytes da chave primária da tabela-base (chave de partição e chave de classificação)
-
O tamanho em bytes do atributo de chave do índice
-
O tamanho em bytes dos atributos projetados (se houver)
-
100 bytes de sobrecarga por item de índice
Para estimar os requisitos de armazenamento de um índice secundário global, você pode estimar o tamanho médio de um item no índice e multiplicar pelo número de itens da tabela-base que têm os atributos de chave do índice secundário global.
Se uma tabela contiver um item em que determinado atributo não esteja definido, mas esteja configurado como uma chave de partição ou chave de classificação do índice, o DynamoDB não gravará nenhum dado desse item no índice.
