Práticas recomendadas para modelagem de dados relacionais no DynamoDB
Esta seção fornece práticas recomendadas para modelagem de dados relacionais no Amazon DynamoDB. Primeiro, apresentamos os conceitos tradicionais de modelagem de dados. Em seguida, descrevemos as vantagens de usar o DynamoDB em relação aos sistemas tradicionais de gerenciamento de banco de dados relacional, mostrando como ele elimina a necessidade de operações de JOIN e reduz as despesas operacionais indiretas.
Depois, explicamos como criar uma tabela do DynamoDB que escale com eficiência. Por fim, fornecemos um exemplo de como modelar dados relacionais no DynamoDB.
Tópicos
Modelos tradicionais de banco de dados relacional
Os sistemas de gerenciamento de banco de dados relacional (RDBMS) tradicionais armazenam dados em uma estrutura relacional normalizada. O objetivo do modelo de dados relacional é reduzir a duplicação de dados (por meio da normalização) para apoiar a integridade referencial e reduzir as anomalias de dados.
O esquema a seguir é um exemplo de um modelo de dados relacional para uma aplicação genérica de entrada de pedidos. A aplicação atende a um esquema de recursos humanos que apoia os sistemas de suporte operacional e comercial de um fabricante fictício.
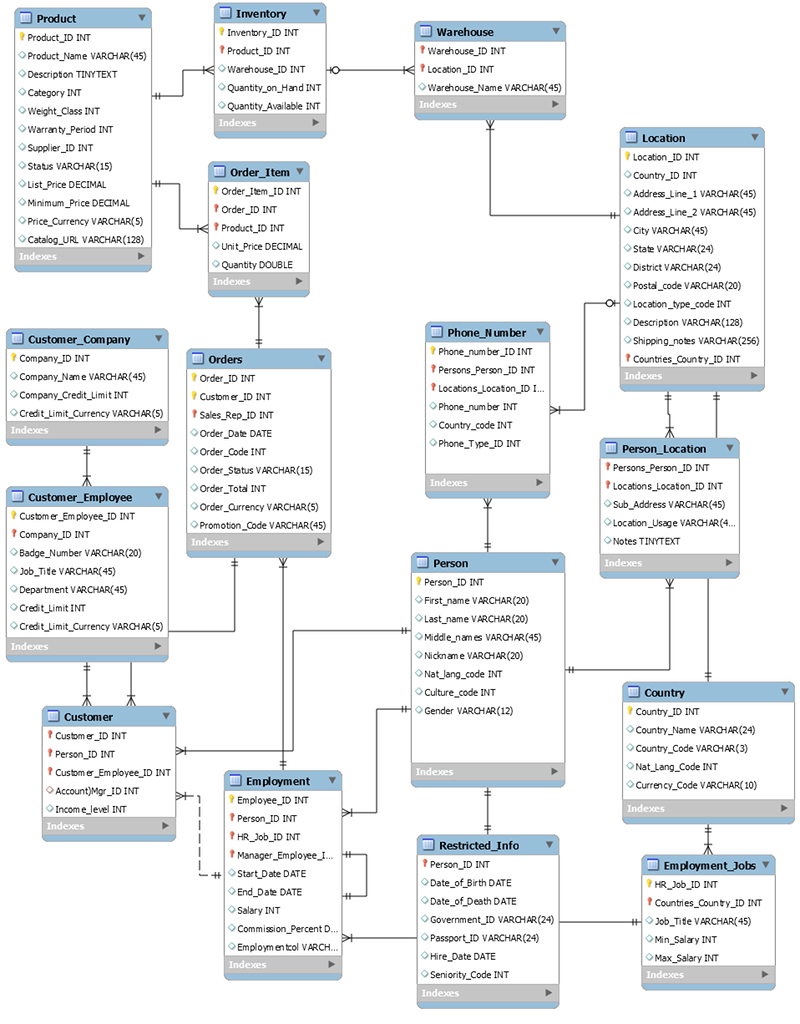
Como um serviço de banco de dados não relacional, o DynamoDB oferece muitas vantagens em relação aos sistemas tradicionais de gerenciamento de banco de dados relacional.
Como o DynamoDB elimina a necessidade de operações JOIN
Um RDBMS usa uma linguagem de consulta estruturada (SQL) para retornar dados à aplicação. Em decorrência da normalização do modelo de dados, essas consultas normalmente exigem o uso do operador JOIN para combinar dados de uma ou mais tabelas.
Por exemplo, para gerar uma lista de itens de ordens de compra classificadas pela quantidade em estoque em todos os depósitos que podem enviar cada item, você pode emitir a seguinte consulta de SQL no esquema anterior:
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCConsultas SQL desse tipo podem fornecer uma API flexível para acesso aos dados, mas exigem um volume significativo de processamento. Cada junção na consulta aumenta a complexidade do tempo de execução da consulta, pois os dados de cada tabela devem ser armazenados e depois montados para retornar o conjunto de resultados.
Outros fatores que podem afetar o tempo de execução das consultas são o tamanho das tabelas e se as colunas que estão sendo unidas têm índices. A consulta anterior inicia consultas complexas em várias tabelas e, depois, classifica o conjunto de resultados.
Eliminar a necessidade de JOINs é o principal objetivo da modelagem de dados NoSQL. É por isso que criamos o DynamoDB para oferecer suporte à Amazon.com e que o DynamoDB pode oferecer performance consistente em qualquer escala. Dada a complexidade do runtime das consultas SQL e JOINs, a performance do RDBMS não é constante em larga escala. Isso causa problemas de performance à medida que as aplicações do cliente se ampliam.
Embora a normalização dos dados reduza a quantidade de dados armazenados em disco, geralmente os recursos mais restritos que afetam a performance são o tempo de CPU e a latência da rede.
O DynamoDB foi criado para minimizar as duas restrições, eliminando JOINs (e incentivando a desnormalização dos dados) e otimizando a arquitetura do banco de dados para responder totalmente a uma consulta de aplicação com uma única solicitação para um item. Essas qualidades permitem que o DynamoDB forneça performance de milissegundos de um dígito em qualquer escala. Isso ocorre porque a complexidade do tempo de execução das operações do DynamoDB é constante, independentemente do tamanho dos dados, para padrões comuns de acesso.
Como as transações do DynamoDB eliminam a sobrecarga no processo de gravação
Outro fator que pode desacelerar um RDBMS é o uso de transações para gravação em um esquema normalizado. Conforme mostrado no exemplo, as estruturas de dados relacionais usadas pela maioria das aplicações de processamento de transações on-line (OLTP) devem ser divididas e distribuídas entre várias tabelas lógicas quando são armazenadas em um RDBMS.
Portanto, um framework de transações compatível com ACID é necessário para evitar problemas de integridade de dados e condições de disputa que poderão ocorrer se uma aplicação tentar ler um objeto que esteja em processo de gravação. Esse framework de transações, quanto acoplado a um esquema relacional, pode adicionar uma sobrecarga significativa ao processo de gravação.
A implementação de transações no DynamoDB impede problemas comuns de escalabilidade encontrados em um RDBMS. O DynamoDB faz isso ao emitir uma transação como uma única chamada de API e limitar o número de itens que podem ser acessados nessa única transação. Transações de longa duração podem causar problemas operacionais ao manter os dados bloqueados por muito tempo ou perpetuamente, pois a transação nunca é encerrada.
Para evitar esses problemas no DynamoDB, as transações foram implementadas com duas operações de API distintas: TransactWriteItems e TransactGetItems. Essas operações de API não têm semânticas de início e fim, que são comuns em um RDBMS. Além disso, o DynamoDB tem um limite de acesso de 100 itens em uma transação para igualmente evitar transações de longa duração. Para saber mais sobre transações do DynamoDB, consulte Trabalhar com transações.
Por esses motivos, quando sua empresa precisar de resposta de baixa latência a consultas de alto tráfego, aproveitar as vantagens de um sistema NoSQL normalmente faz sentido do ponto de vista técnico e econômico. O Amazon DynamoDB ajuda a resolver os problemas que limitam a escalabilidade do sistema relacional simplesmente evitando-os.
Normalmente, a performance de um RDBMS não escala bem pelos seguintes motivos:
-
Ele usa junções caras para remontar as visualizações exigidas dos resultados de consulta.
-
Ele normaliza os dados e armazena-os em várias tabelas que exigem várias consultas para gravar em disco.
-
Isso geralmente implica em custos de desempenho de um sistema de transações compatível com ACID.
O DynamoDB tem uma boa escalabilidade por estes motivos:
-
A flexibilidade do esquema permite o DynamoDB armazene dados hierárquicos e complexos em um único item.
-
O design da chave composta permite o armazenamento de itens relacionados na mesma tabela.
-
As transações são realizadas em uma única operação. O limite ao número de itens que podem ser acessados é 100, para evitar operações de longa duração.
As consultas no armazenamento de dados tornam-se muito mais simples, normalmente da seguinte forma:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
O DynamoDB executa muito menos trabalho para retornar os dados solicitados em comparação ao RDBMS no exemplo anterior.
