Fundamentos da modelagem de dados no DynamoDB
Esta seção aborda a camada básica, examinando os dois tipos de design de tabela: tabela única e várias tabelas.
Conceitos básicos do design de tabela única
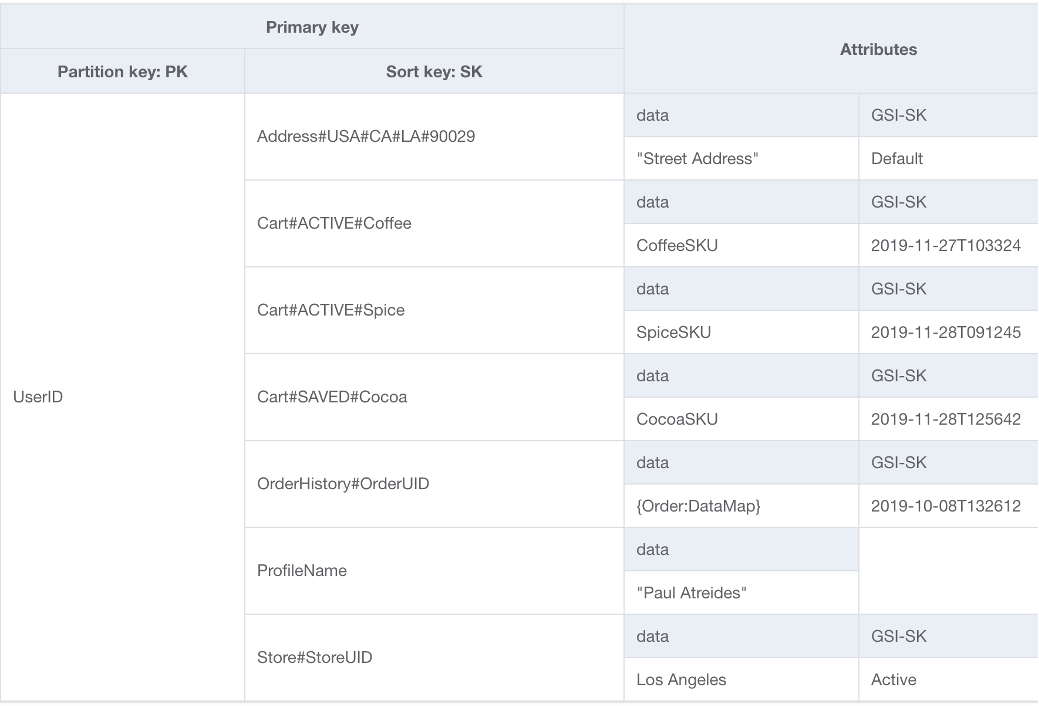
Uma das opções de base para o esquema do DynamoDB é o design de tabela única. O design de tabela única é um padrão que permite armazenar vários tipos (entidades) de dados em uma única tabela do DynamoDB. Seu objetivo é otimizar os padrões de acesso aos dados, melhorar a performance e reduzir os custos, eliminando a necessidade de manter várias tabelas e relacionamentos complexos entre elas. Isso é possível porque o DynamoDB armazena itens com a mesma chave de partição (conhecida como coleção de itens) nas mesmas partições. Nesse design, diferentes tipos de dados são armazenados como itens na mesma tabela e cada item é identificado por uma chave de classificação exclusiva.
Vantagens
-
Oferece localidade de dados para atender a consultas para vários tipos de entidades em uma única chamada de banco de dados.
-
Reduz os custos financeiros gerais e de latência das leituras:
-
Uma única consulta para dois itens com menos de 4 KB no total corresponde a 0,5 RCU com consistência final.
-
Duas consultas para dois itens com menos de 4 KB no total corresponde a 1 RCU com consistência final (0,5 RCU cada).
-
O tempo para exibir duas chamadas de banco de dados separadas normalmente será maior do que o de uma única chamada.
-
-
Reduz o número de tabelas a serem gerenciadas:
-
Não é necessário manter permissões em vários perfis ou políticas do IAM.
-
O gerenciamento de capacidade da tabela é distribuído proporcionalmente entre todas as entidades, o que geralmente resulta em um padrão de consumo mais previsível.
-
O monitoramento requer menos alarmes.
-
As chaves de criptografia gerenciadas pelo cliente só precisam ser alternadas em uma única tabela.
-
-
Suaviza o tráfego para a tabela:
-
Ao agregar vários padrões de uso à mesma tabela, o uso geral tende a ser mais suave (da mesma forma que a performance de um índice de ações tende a ser mais suave do que qualquer ação individual), o que é mais adequado para conseguir maior utilização com tabelas de modo provisionado.
-
Desvantagens
-
A curva de aprendizado pode ser pronunciada devido ao design paradoxal em comparação com bancos de dados relacionais.
-
Os requisitos de dados devem ser consistentes em todos os tipos de entidade.
-
Os backups são tudo ou nada; portanto, se alguns dados não forem essenciais, pense na possibilidade de mantê-los em uma tabela separada.
-
A criptografia da tabela é compartilhada entre todos os itens. Para aplicações de vários locatários com requisitos individuais de criptografia de locatário, seria necessária a criptografia do lado do cliente.
-
As tabelas com uma combinação de dados históricos e dados operacionais não serão tão beneficiadas com a habilitação da classe de armazenamento de acesso infrequente. Para obter mais informações, consulte . Classes de tabelas do DynamoDB
-
-
Todos os dados alterados serão propagados para o DynamoDB Streams mesmo que seja necessário processar somente um subconjunto de entidades.
-
Graças aos filtros de eventos do Lambda, isso não afetará sua fatura ao usar o Lambda, mas haverá um custo adicional se você usar a Kinesis Consumer Library.
-
-
Quando se usa o GraphQL, é mais difícil de implementar o design de tabela única.
-
Ao usar clientes SDK de nível superior, como o DynamoDBMapper do Java ou o Enhanced Client, pode ser mais difícil processar resultados porque na mesma resposta pode haver itens associados a classes diferentes.
Quando utilizar
O design de tabela única funciona bem para aplicativos que frequentemente consultam vários tipos de entidades juntos ou precisam manter relacionamentos entre diferentes tipos de dados. É particularmente eficaz quando seus padrões de acesso se beneficiam da localidade de dados e quando você deseja minimizar a sobrecarga de gerenciar várias tabelas.
Conceitos básicos do design de várias tabelas
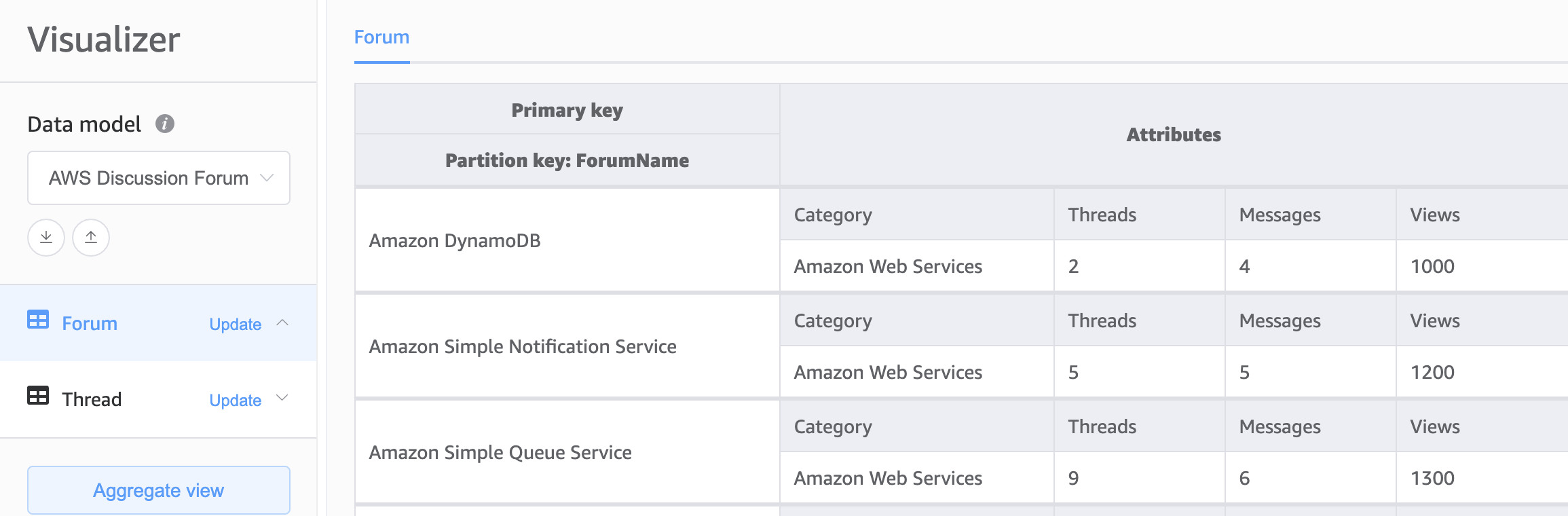
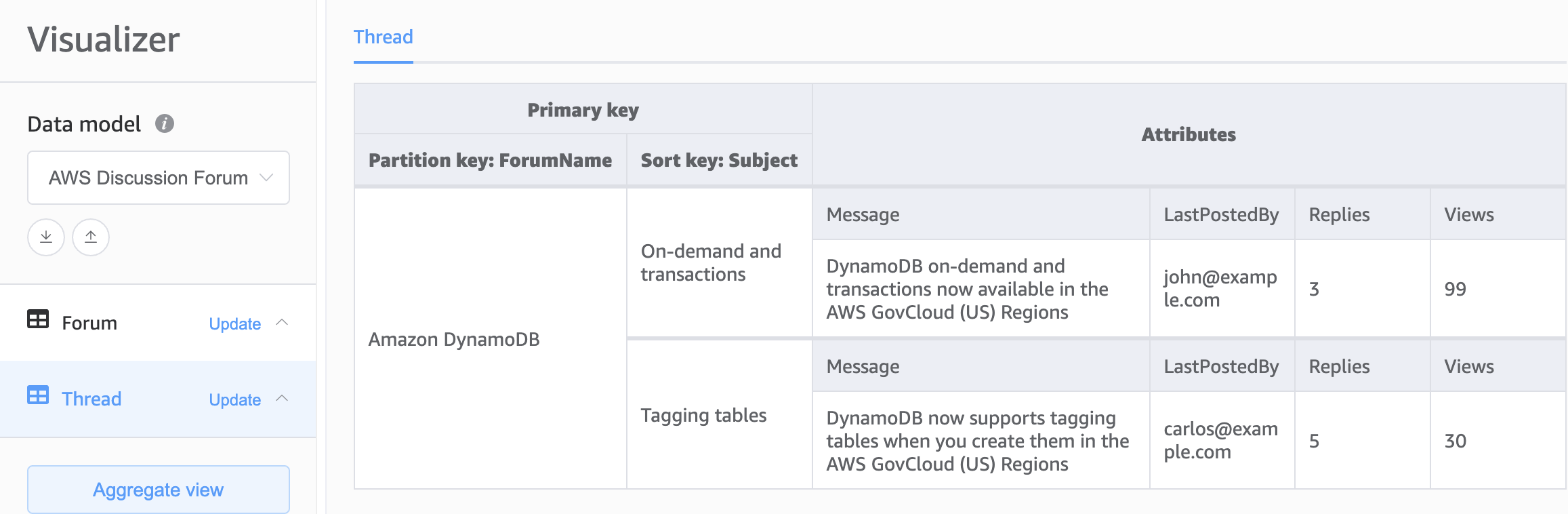
A segunda opção de base para o nosso esquema do DynamoDB é o design de várias tabelas. O design de várias tabelas é um padrão mais parecido com um design de banco de dados tradicional em que você armazena um único tipo (entidade) de dados em cada tabela do DynamoDB. Os dados em cada tabela ainda serão organizados por chave de partição para que a performance e a escalabilidade de um único tipo de entidade sejam otimizadas, mas as consultas em várias tabelas deverão ser feitas de forma independente.
Vantagens
-
É mais simples de projetar para quem não está acostumado a trabalhar com design de tabela única.
-
Possibilita uma implementação mais fácil de resolvedores do GraphQL devido ao mapeamento de cada resolvedor para uma única entidade (tabela).
-
Permite requisitos de dados exclusivos em diferentes tipos de entidade:
-
É possível fazer backups de tabelas individuais de missão crítica.
-
É possível gerenciar a criptografia de cada tabela. Para aplicações de vários locatários com requisitos individuais de criptografia de locatário, tabelas de locatários separadas possibilitam que cada cliente tenha sua própria chave de criptografia.
-
Para obter todos os benefícios de redução de custos, a classe de armazenamento de acesso infrequente pode ser habilitada apenas nas tabelas com dados históricos. Para obter mais informações, consulte . Classes de tabelas do DynamoDB
-
-
Cada tabela terá seu próprio fluxo de dados de alteração, permitindo que uma função do Lambda dedicada seja projetada para cada tipo de item, em vez de um único processador monolítico.
Desvantagens
-
Para padrões de acesso que exigem dados em várias tabelas, diversas leituras do DynamoDB serão necessárias e talvez os dados precisem ser processados e unidos no código do cliente.
-
As operações e o monitoramento de várias tabelas exigem mais alarmes do CloudWatch, e cada tabela deve ser escalada de forma independente.
-
As permissões de cada tabela precisarão ser gerenciadas separadamente. A adição de tabelas no futuro exigirá uma alteração em todos os perfis ou políticas essenciais do IAM.
Quando utilizar
Se os padrões de acesso da aplicação não precisarem consultar várias entidades ou tabelas ao mesmo tempo, o design de várias tabelas será uma abordagem adequada e suficiente.
