Migrar um banco de dados relacional para o DynamoDB
A migração de um banco de dados relacional para o DynamoDB exige um planejamento cuidadoso para garantir um resultado bem-sucedido. Este guia ajudará você a entender como esse processo funciona, quais ferramentas estão disponíveis e, depois, como avaliar possíveis estratégias de migração e selecionar uma que atenda às suas necessidades.
Tópicos
Considerações ao migrar um banco de dados relacional para o DynamoDB
Noções básicas de como funciona uma migração para o DynamoDB
Selecionar a estratégia apropriada para migrar para o DynamoDB
Realizar uma migração on-line para o DynamoDB migrando cada tabela 1:1
Realizar uma migração on-line para o DynamoDB usando tabela de preparação personalizada.
Motivos para migrar para o DynamoDB
A migração para o Amazon DynamoDB apresenta uma série de benefícios interessantes para empresas e organizações. Veja a seguir algumas das principais vantagens que tornam o DynamoDB uma opção atraente para migração de banco de dados:
-
Escalabilidade: o DynamoDB foi concebido para lidar com grandes workloads e escalar perfeitamente para acomodar volumes e tráfego de dados crescentes. Com o DynamoDB, é fácil aumentar ou reduzir a escala do banco de dados verticalmente com base na demanda, garantindo que as aplicações possam lidar com picos repentinos de tráfego sem comprometer a performance.
-
Performance: o DynamoDB oferece acesso a dados de baixa latência, permitindo que as aplicações recuperem e processem dados com velocidade excepcional. Sua arquitetura distribuída garante que as operações de leitura e gravação sejam distribuídas em vários nós, oferecendo tempos de resposta consistentes de um dígito de milissegundo, mesmo com altas taxas de solicitação.
-
Totalmente gerenciado: o DynamoDB é um serviço totalmente gerenciado oferecido pela AWS. Isso significa que a AWS lida com os aspectos operacionais do gerenciamento de banco de dados, incluindo provisionamento, configuração, aplicação de patches, backups e escalabilidade. Isso permite que você se concentre mais no desenvolvimento de aplicações e menos nas tarefas de administração do banco de dados.
-
Arquitetura sem servidor: o DynamoDB comporta um modelo sem servidor, conhecido como DynamoDB sob demanda, em que você paga somente pelas solicitações reais de leitura e gravação feitas pela aplicação, sem a necessidade de provisionamento antecipado de capacidade. Esse modelo de pagamento por solicitação oferece economia e despesas operacionais mínimas, pois você paga apenas pelos recursos que consome, sem a necessidade de provisionar e monitorar a capacidade.
-
Flexibilidade do NoSQL: ao contrário dos bancos de dados relacionais tradicionais, o DynamoDB segue um modelo de dados NoSQL, oferecendo flexibilidade no design do esquema. Com o DynamoDB, é possível armazenar dados estruturados, semiestruturados e não estruturados, o que o torna adequado para lidar com tipos de dados diversos e dinâmicos. Essa flexibilidade permite ciclos de desenvolvimento mais rápidos e uma adaptação mais fácil às mudanças nos requisitos de negócios.
-
Alta disponibilidade e durabilidade: o DynamoDB replica dados em várias zonas de disponibilidade em uma região, garantindo alta disponibilidade e durabilidade dos dados. Ele gerencia automaticamente a replicação, o failover e a recuperação, minimizando o risco de perda de dados ou interrupções no serviço. O DynamoDB oferece um SLA de disponibilidade de até 99,999%.
-
Segurança e conformidade: o DynamoDB integra-se ao AWS Identity and Access Management para oferecer um controle de acesso minucioso. Ele fornece criptografia em repouso e em trânsito, garantindo a segurança dos dados. O DynamoDB também segue vários padrões de conformidade, incluindo HIPAA, PCI DSS e RGPD, possibilitando que você atenda aos requisitos regulatórios.
-
Integração com o ecossistema da AWS: como parte do ecossistema da AWS, o DynamoDB integra-se perfeitamente com outros serviços da AWS, como AWS Lambda, CloudFormation e AWS AppSync. Essa integração permite criar arquiteturas sem servidor, aproveitar a infraestrutura como código e criar aplicações orientadas por dados em tempo real.
Considerações ao migrar um banco de dados relacional para o DynamoDB
Os sistemas de bancos de dados relacionais e os bancos de dados NoSQL têm diferentes pontos fortes e fracos. Essas diferenças tornam o design de banco de dados diferente entre os dois sistemas.
| Tipo de tarefa | Banco de dados relacional | Banco de dados NoSQL |
|---|---|---|
| Consultar o banco de dados | Em bancos de dados relacionais, as consultas de dados são flexíveis, mas têm um custo relativamente alto e não escalam com facilidade em situações de grande volume de tráfego (consulte Primeiras passos para a modelagem de dados relacionais no DynamoDB). Uma aplicação de banco de dados relacional pode implementar lógica de negócios em procedimentos armazenados, subconsultas SQL, consultas de atualização em massa e consultas de agregação. | Em um banco de dados NoSQL como o DynamoDB, há formas limitadas de consultar dados com eficiência. As demais formas de consulta podem apresentar alto custo e baixa performance. As gravações no DynamoDB são singletons. A lógica de negócios da aplicação que antes era executada em procedimentos armazenados deve ser refatorada para ser executada fora do DynamoDB em código personalizado executado em um host, como Amazon EC2 ou AWS Lambda. |
| Projetar o banco de dados | Você deve criar o design para ter flexibilidade sem se preocupar com detalhes de implementação ou performance. A otimização de consultas geralmente não afeta o design do esquema, mas a normalização é importante. | Você deve criar o esquema especificamente para fazer as consultas mais comuns e importantes do modo mais rápido e econômico possível. Suas estruturas de dados são adaptadas aos requisitos específicos de seus casos de uso de negócios. |
A criação de um projeto para banco de dados NoSQL requer uma mentalidade diferente da criação de um projeto para um sistema de gerenciamento de banco de dados relacional (RDBMS). Para um RDBMS, você pode criar um modelo de dados normalizado sem pensar nos padrões de acesso. Você poderá estendê-lo posteriormente quando surgirem novas perguntas e requisitos de consulta. Você pode organizar cada tipo de dados em sua própria tabela.
Com o projeto NoSQL, você pode projetar o esquema do DynamoDB quando não souber a quais perguntas ele precisará responder. É essencial compreender os problemas de negócios e os padrões de leitura e gravação da aplicação. Também é necessário manter o mínimo de tabelas possível em uma aplicação do DynamoDB. Com menos tabelas, há mais escalabilidade, menos gerenciamento de permissões e menor sobrecarga para o DynamoDB. Isso também pode ajudar a manter os custos de backup mais baixos em geral.
A tarefa de modelar dados relacionais para o DynamoDB e criar uma versão da aplicação front-end é um tópico separado. Este guia pressupõe que você tenha uma nova versão da aplicação criada para usar o DynamoDB, mas mesmo assim é necessário determinar a melhor forma de migrar e sincronizar dados históricos durante a substituição.
Considerações sobre tamanho
O tamanho máximo de cada item (linha) armazenado em uma tabela do DynamoDB é 400 KB. Para obter mais informações, consulte Cotas no Amazon DynamoDB. O tamanho do item é determinado pelo tamanho total de todos os nomes e valores de atributos em um item. Para obter mais informações, consulte Tamanhos e formatos de item do DynamoDB.
Se a aplicação precisa armazenar mais dados em um item do que o limite de tamanho do DynamoDB permite, divida o item em um conjunto de itens, compacte os dados do item ou armazene-o como um objeto no Amazon Simple Storage Service (Amazon S3) ao armazenar o identificador do objeto do Amazon S3 no item do DynamoDB. Consulte Práticas recomendadas para armazenar itens e atributos grandes no DynamoDB. O custo de atualização de um item baseia-se no tamanho total do item. Para workloads que exigem atualizações frequentes de itens existentes, ter itens pequenos de 1 ou 2 KB custará menos para atualizar do que itens maiores. Consulte Coleções de itens: como modelar relações de um para muitos no DynamoDB para ter mais informações sobre conjuntos de itens.
Ao selecionar a partição e os atributos da chave de classificação, outras configurações da tabela, o tamanho e a estrutura do item e se deseja criar índices secundários, não deixe de analisar a documentação de modelagem do DynamoDB, bem como Otimizar os custos nas tabelas do DynamoDB no guia. Teste seu plano de migração para que a solução do DynamoDB seja econômica e ajuste-se aos recursos e às limitações do DynamoDB.
Noções básicas de como funciona uma migração para o DynamoDB
Antes de analisar as ferramentas de migração disponíveis para nós, pense em como as gravações são processadas pelo DynamoDB.
A operação de gravação padrão e mais comum é uma única operação de API PutItem. É possível realizar uma operação PutItem em um loop para processar conjuntos de dados. O DynamoDB comporta conexões simultâneas praticamente ilimitadas; portanto, supondo que você possa configurar e executar uma rotina de carregamento extremamente multiencadeada, como MapReduce ou Spark, a velocidade das gravações é limitada apenas pela capacidade da tabela de destino (que geralmente também é ilimitada).
Ao carregar dados no DynamoDB, é importante entender a velocidade de gravação do carregador. Se os itens (linhas) que você está carregando tiverem 1 KB de tamanho ou menos, essa velocidade será simplesmente o número de itens por segundo. A tabela de destino pode então ser provisionada com WCU (unidades de capacidade de gravação) suficientes para lidar com essa taxa. Se seu carregador exceder a capacidade provisionada em qualquer segundo que seja, as solicitações adicionais poderão ter controle de utilização ou ser totalmente rejeitadas. É possível conferir se há controles de utilização nos gráficos do CloudWatch encontrados na guia de monitoramento do console do DynamoDB.
A segunda operação que pode ser executada é com uma API relacionada, chamada BatchWriteItem. BatchWriteItem permite combinar até 25 solicitações de gravação em uma chamada de API. Elas são recebidas pelo serviço e processados como solicitações PutItem separadas para a tabela. No momento, ao escolher BatchWriteItem, você não terá a vantagem das novas tentativas automáticas incluídas no SDK da AWS ao fazer chamadas únicas com PutItem. Portanto, se houver algum erro (como exceções de controle de utilização), será necessário procurar a lista de todas as gravações com falha na chamada de resposta para BatchWriteItem. Para ter mais informações sobre como lidar com avisos de controle de utilização, caso sejam detectados nos gráficos de controle de utilização do CloudWatch, consulte Solução de problemas de controle de utilização no Amazon DynamoDB.
O terceiro tipo de importação de dados é possível com o recurso de importação do DynamoDB do S3PutItem, ele requer um processo upstream e grava os dados no formato escolhido em um bucket do Amazon S3.
Ferramentas úteis na migração para o DynamoDB
Há várias ferramentas comuns de migração e ETL que você pode usar para migrar dados para o DynamoDB.
A Amazon oferece uma série de ferramentas de dados que podem ser utilizadas na migração, incluindo AWS Database Migration Service (DMS), AWS Glue, Amazon EMR e Amazon Managed Streaming for Apache Kafka. Todas essas ferramentas podem ser usadas para realizar uma migração em tempo de inatividade e elas podem utilizar os atributos de captura de dados de alteração (CDC) do banco de dados relacional para comportar migrações on-line. Ao escolher uma ferramenta, será útil pensar no conjunto de habilidades e na experiência que sua organização tem com cada ferramenta, além dos atributos, do desempenho e do custo de cada uma.
Muitos clientes optam por elaborar seus próprios scripts e trabalhos de migração para criar transformações de dados personalizadas para o processo de migração. Se você planeja operar uma tabela de alto volume do DynamoDB com tráfego intenso de gravação ou trabalhos grandes e regulares de carga em massa, talvez você mesmo queira gravar código de migração para conhecer melhor o comportamento do DynamoDB em tráfego intenso de gravação. Controle de utilização e provisionamento eficiente de tabelas são situações que podem ocorrer no início do projeto ao realizar uma migração prática.
Selecionar a estratégia apropriada para migrar para o DynamoDB
Uma grande aplicação de banco de dados relacional pode abranger uma centena ou mais de tabelas e comportar várias funções diferentes da aplicação. Ao abordar uma grande migração, pense em dividir sua aplicação em componentes ou microsserviços menores e migrar um pequeno conjunto de tabelas por vez. Depois, é possível migrar componentes adicionais para o DynamoDB em ondas.
Ao selecionar uma estratégia de migração, vários fatores podem direcionar você para uma solução ou outra. Podemos apresentar essas opções em uma árvore de decisão a fim de simplificar as opções disponíveis para nós, de acordo com nossos requisitos e recursos disponíveis. Os conceitos são brevemente mencionados aqui (mas serão abordados com mais detalhes posteriormente no guia):
-
Migração off-line: se a aplicação puder tolerar algum tempo de inatividade durante a migração, isso simplificará o processo.
-
Migração híbrida: essa abordagem possibilita um tempo de atividade parcial durante a migração, como permitir leituras, mas não gravações, ou permitir leituras e inserções, mas não atualizações e exclusões.
-
Migração on-line: aplicações que não exigem tempo de inatividade durante a migração são mais difíceis de migrar e podem exigir planejamento significativo e desenvolvimento personalizado. Uma decisão importante é calcular e ponderar os custos da criação de um processo de migração personalizado em comparação ao custo para a empresa de ter uma janela de tempo de inatividade durante a substituição.
| If (Se) | E | Então |
|---|---|---|
| For possível desativar a aplicação por algum tempo durante uma janela de manutenção para realizar a migração de dados. Essa é uma migração off-line. |
Use o AWS DMS e realize uma migração off-line usando uma tarefa de carga completa. Pré-modele os dados de origem com um SQL |
|
| For possível executar a aplicação no modo somente leitura durante a migração. Essa é uma migração híbrida. | Desabilite as gravações na aplicação ou no banco de dados de origem. Use o AWS DMS e realize uma migração off-line usando uma tarefa de carga completa. | |
| For possível executar a aplicação com leituras e inserções de novos registros, mas sem atualizações ou exclusões, durante a migração. Essa é uma migração híbrida. | Você tiver habilidades em desenvolvimento de aplicações e puder atualizar a aplicação relacional existente para realizar gravações duplas, inclusive no DynamoDB, para todos os novos registros. | Use o AWS DMS e realize uma migração off-line usando uma tarefa de carga completa. Simultaneamente, implante uma versão da aplicação existente que permita leituras e execute gravações duplas. |
| Você precisar de uma migração com o mínimo de tempo de inatividade. Essa é uma migração on-line. |
|
Use o AWS DMS para realizar uma migração de dados on-line. Executar uma tarefa de carregamento em massa seguida pela tarefa de sincronização do CDC. |
| Você precisar de uma migração com o mínimo de tempo de inatividade. Essa é uma migração on-line. |
|
Crie a tabela pronta para NoSQL no banco de dados SQL. Preencha-a e sincronize-a usando JOINs, UNIONs, VIEWs, gatilhos e procedimentos armazenados. |
| Você precisar de uma migração com o mínimo de tempo de inatividade. Essa é uma migração on-line. |
|
Pense nas abordagens de migração híbrida ou off-line. |
| Você precisar de uma migração com o mínimo de tempo de inatividade. Essa é uma migração on-line. | For possível ignorar a migração de dados históricos de transações ou arquivá-los no Amazon S3 em vez de migrá-los. Você só precisa migrar algumas pequenas tabelas estáticas. | Escreva um script ou use qualquer ferramenta ETL para migrar as tabelas. Pré-modele os dados de origem com um SQL VIEW, se desejar. |
Realizar uma migração off-line para o DynamoDB
As migrações off-line são adequadas para quando é possível permitir uma janela de tempo de inatividade para realizar a migração. Os bancos de dados relacionais geralmente têm pelo menos algum tempo de inatividade a cada mês para manutenção e correção, ou podem levar mais tempo de inatividade para atualizações de hardware ou atualizações de versões principais.
O Amazon S3 pode ser usado como uma área de preparação durante uma migração. Os dados armazenados no formato CSV (valores separados por vírgula) ou no formato JSON do DynamoDB podem ser importados automaticamente para uma nova tabela do DynamoDB usando o recurso de importação do DynamoDB do S3.
Convém combinar tabelas para utilizar padrões exclusivos de acesso ao NoSQL (por exemplo, transformar quatro tabelas herdadas em uma única tabela do DynamoDB). Uma única solicitação de documento de chave-valor ou uma consulta para uma coleção de itens pré-agrupados geralmente exibe uma melhor latência do que um banco de dados SQL que realize uma junção de várias tabelas. No entanto, isso dificulta a tarefa de migração. Uma visualização SQL pode fazer o trabalho no banco de dados de origem para preparar um único conjunto de dados representando todas as quatro tabelas em um conjunto.
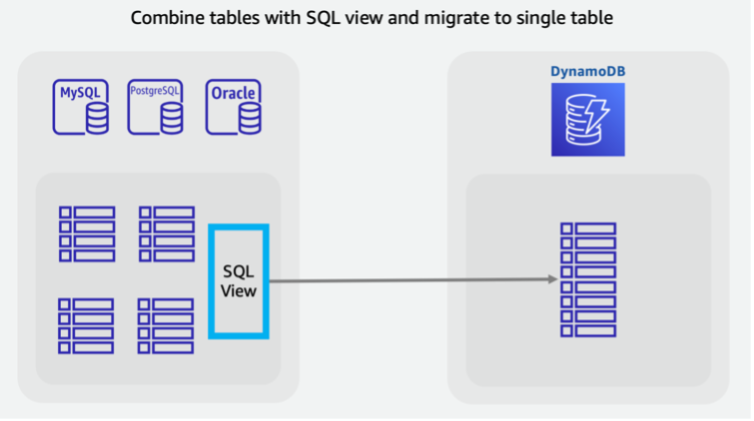
Essa visualização pode JOIN tabelas em um formato desnormalizado ou manter as entidades normalizadas e empilhar tabelas usando um SQL UNION. As principais decisões sobre a reformulação de dados relacionais são abordadas neste vídeo
Plano
Executar uma migração off-line usando o Amazon S3
Ferramentas
-
Um trabalho de ETL para extrair e transformar dados SQL e armazená-los em um bucket do S3, como:
-
AWS Database Migration Service, um serviço que pode carregar históricos de dados em massa e também processar registros de captura de dados de alteração (CDC) para sincronizar tabelas de origem e destino.
-
AWS Glue
-
Amazon EMR
-
Seu próprio código personalizado.
-
-
O recurso de importação do DynamoDB do S3.
Etapas de migração off-line:
-
Crie um trabalho de ETL que possa consultar o banco de dados SQL, transformar os dados da tabela no formato JSON ou CSV do DynamoDB e salvá-los em um bucket do S3.
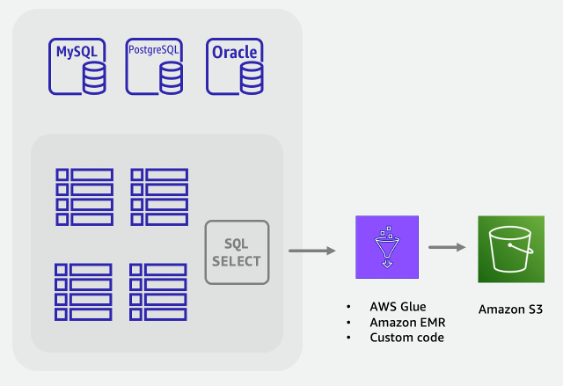
-
O recurso de importação do DynamoDB do S3 é invocado para criar uma tabela e carregar automaticamente os dados do bucket do S3.
A migração totalmente off-line é simples e direta, mas pode não ser popular entre proprietários e usuários de aplicações. Os usuários se beneficiariam se a aplicação pudesse fornecer níveis reduzidos de serviço durante a migração, em vez de nenhum serviço.
É possível adicionar uma funcionalidade para desabilitar as gravações durante a migração off-line, permitindo que as leituras continuem normalmente. Os usuários da aplicação ainda podem navegar e consultar com segurança os dados existentes enquanto os dados relacionais estão sendo migrados. Se é isso que você está procurando, continue lendo para saber mais sobre migrações híbridas.
Realizar uma migração híbrida para o DynamoDB
Embora todas as aplicações de banco de dados realizem operações de leitura e gravação, os tipos de operações de gravação que estão sendo realizadas devem ser considerados ao planejar uma migração híbrida ou on-line. As gravações de banco de dados podem ser classificadas em três buckets: inserções, atualizações e exclusões. Algumas aplicações podem não exigir o processamento imediato das exclusões. Por exemplo, essas aplicações podem adiar as exclusões para um processo de limpeza em massa no final do mês. Esses tipos de aplicações podem ser mais simples de migrar e, ao mesmo tempo, possibilitam tempo de atividade parcial.
Planejamento
Realizar uma migração híbrida on-line/off-line com gravações duplas de aplicações
Ferramentas
-
Um trabalho de ETL para extrair e transformar dados SQL e armazená-los em um bucket do S3, como:
-
AWS DMS
-
AWS Glue
-
Amazon EMR
-
Seu próprio código personalizado.
-
Etapas de migração híbridas:
-
Criar uma tabela do DynamoDB de destino. Essa tabela receberá dados históricos em massa e novos dados ativos.
-
Crie uma versão da aplicação herdada que tenha as exclusões e as atualizações desabilitadas enquanto executa todas as inserções como gravações duplas no banco de dados SQL e no DynamoDB
-
Iniciar o trabalho de ETL ou a tarefa AWS DMS para alocar os dados existentes e implantar a nova versão da aplicação ao mesmo tempo
-
Quando a alocação for concluída, o DynamoDB terá todos os registros novos e existentes e estará pronto para a substituição da aplicação.
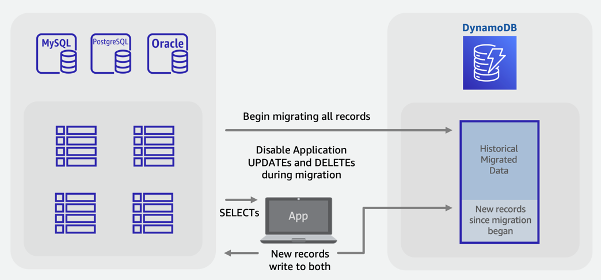
nota
A tarefa de alocação grava diretamente do SQL no DynamoDB. Não é possível usar o recurso de importação do S3 como no exemplo de migração off-line, pois esse recurso cria uma nova tabela que não estará ativa até que o DynamoDB carregue os dados.
Realizar uma migração on-line para o DynamoDB migrando cada tabela 1:1
Muitos bancos de dados relacionais têm um recurso chamado captura de dados de alterações (CDC), em que o banco de dados permite que os usuários solicitem uma lista das alterações em uma tabela que ocorreram antes ou depois de um momento específico. A CDC usa logs internos para habilitar esse recurso e não exige nenhuma coluna de carimbo de data e hora para a tabela funcionar.
Ao migrar um esquema de tabelas SQL para um banco de dados NoSQL, convém combinar e remodelar os dados em menos tabelas. Isso permitirá que você colete dados em um único local e evite a necessidade de unir manualmente os dados relacionados em operações de leitura em várias etapas. No entanto, a modelagem de dados de tabela única nem sempre é necessária e, às vezes, você migrará tabelas 1 para 1 para o DynamoDB. Essas migrações de tabelas 1 para 1 são menos complicadas, pois é possível utilizar o recurso CDC do banco de dados de origem, usando ferramentas ETL comuns que comportam esse tipo de migração. Os dados de cada linha ainda podem ser transformados em novos formatos, mas o escopo de cada tabela permanece o mesmo.
Pense em migrar tabelas SQL de 1 para 1 para o DynamoDB, com a ressalva de que o DynamoDB não comporta junções do lado do servidor. Você precisará adicionar lógica à aplicação para combinar dados de várias tabelas.
Planejamento
Realizar uma migração on-line de cada tabela para o DynamoDB usando o AWS DMS.
Ferramentas
Etapas de migração on-line:
-
Identificar as tabelas no esquema de origem que serão migradas.
-
Criar o mesmo número de tabelas no DynamoDB com a estrutura de chaves da origem
-
Criar um servidor de replicação em AWS DMS e configure os endpoints de origem e destino.
-
Definir todas as transformações necessárias por linha (como colunas concatenadas ou conversão de datas no formato de string ISO-8601).
-
Criar uma tarefa de migração para cada tabela para Carregamento total e captura de dados de alterações.
-
Monitorar essas tarefas até que a fase de replicação contínua tenha começado.
-
Nesse ponto, é possível realizar qualquer auditoria de validação e, depois, transferir os usuários para a aplicação que lê e grava no DynamoDB.
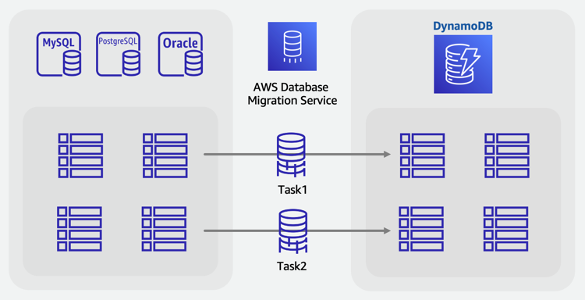
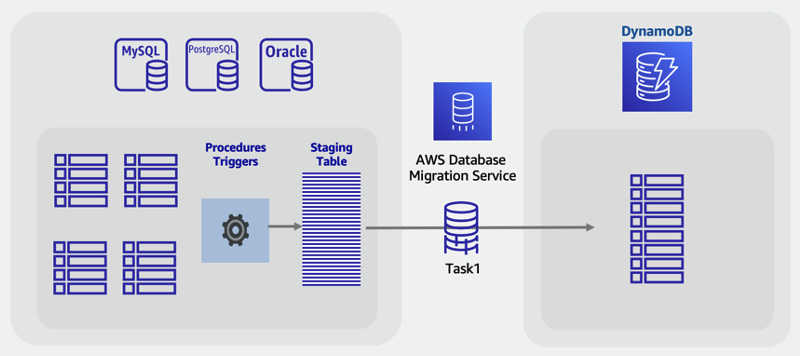
Realizar uma migração on-line para o DynamoDB usando tabela de preparação personalizada.
De forma semelhante ao cenário de migração off-line, você pode combinar tabelas para utilizar padrões exclusivos de acesso ao NoSQL (por exemplo, transformar quatro tabelas herdadas em uma única tabela do DynamoDB). Um SQL VIEW pode fazer o trabalho no banco de dados de origem para preparar um único conjunto de dados representando todas as quatro tabelas em um conjunto.
No entanto, para migrações on-line com dados dinâmicos e variáveis, não é possível utilizar os recursos da CDC, pois eles não são aceitos pelas VIEWs. Se suas tabelas incluírem uma coluna de carimbo de data e hora da última atualização e elas forem incorporadas à VIEW, você poderá criar um trabalho de ETL personalizado que as use para obter uma carga em massa com a sincronização.
Uma nova abordagem para esse desafio é usar recursos SQL padrão, como visualizações, procedimentos armazenados e gatilhos, para criar uma tabela SQL que esteja no formato final desejado do NoSQL do DynamoDB.
Se o servidor de banco de dados tiver capacidade sobressalente, será possível criar essa única tabela de preparação antes do início da migração. Isso seria feito escrevendo um procedimento armazenado que leria as tabelas existentes, transformaria os dados conforme necessário e gravaria na nova tabela de preparação. É possível adicionar um conjunto de gatilhos para replicar as alterações nas tabelas na tabela de preparação em tempo real. Se os gatilhos não forem permitidos de acordo com a política da empresa, as alterações nos procedimentos armazenados poderão ter o mesmo resultado. Você adicionaria algumas linhas de código a qualquer procedimento que grave dados para, além disso, gravar as mesmas alterações na tabela de preparação.
Ter essa tabela de preparação pronta e totalmente sincronizada com as tabelas de aplicações herdadas proporcionará um excelente ponto de partida para uma migração dinâmica. Ferramentas que usam a CDC do banco de dados para realizar migrações em tempo real, como o AWS DMS, agora podem ser usadas nessa tabela. Uma vantagem dessa abordagem é que ela usa habilidades e recursos SQL conhecidos disponíveis no mecanismo de banco de dados relacional.
Planejamento
Executar uma migração on-line com uma tabela de preparação SQL usando o AWS DMS.
Ferramentas
-
Procedimentos ou gatilhos armazenados em SQL personalizados
Etapas de migração on-line:
-
No mecanismo de banco de dados relacional de origem, verifique se há espaço em disco e capacidade de processamento extras.
-
Criar uma tabela de preparação no banco de dados SQL, com carimbos de data e hora ou recursos de CDC habilitados.
-
Gravar e realizar um procedimento armazenado para copiar os dados da tabela relacional existente na tabela de preparação.
-
Implantar gatilhos ou modificar os procedimentos existentes para gravação dupla na nova tabela de preparação enquanto executa gravações normais nas tabelas existentes.
-
Execute AWS DMS para migrar e sincronizar essa tabela de origem com uma tabela de destino do DynamoDB.
Este guia apresentou várias considerações e abordagens para migrar dados de bancos de dados relacionais para o DynamoDB, com foco em minimizar o tempo de inatividade e usar ferramentas e técnicas comuns de banco de dados. Para saber mais, consulte:
