Componentes básicos da modelagem de dados no DynamoDB
Esta seção abordará a camada de componentes básicos que oferecem os padrões de design a serem utilizados na aplicação.
Tópicos
Componente básico: chave de classificação composta
Quando as pessoas pensam em NoSQL, é possível que elas também o imaginem como não relacional. Em última análise, não há motivo que impeça a inserção de relações em um esquema do DynamoDB. Elas só parecem diferentes dos bancos de dados relacionais e das respectivas chaves externas. Um dos padrões mais importantes que podemos usar para desenvolver uma hierarquia lógica de nossos dados no DynamoDB é uma chave de classificação composta. A maneira mais comum de criar uma é separar cada camada da hierarquia (camada pai > camada filha > camada neta) com uma hashtag. Por exemplo, PARENT#CHILD#GRANDCHILD#ETC.
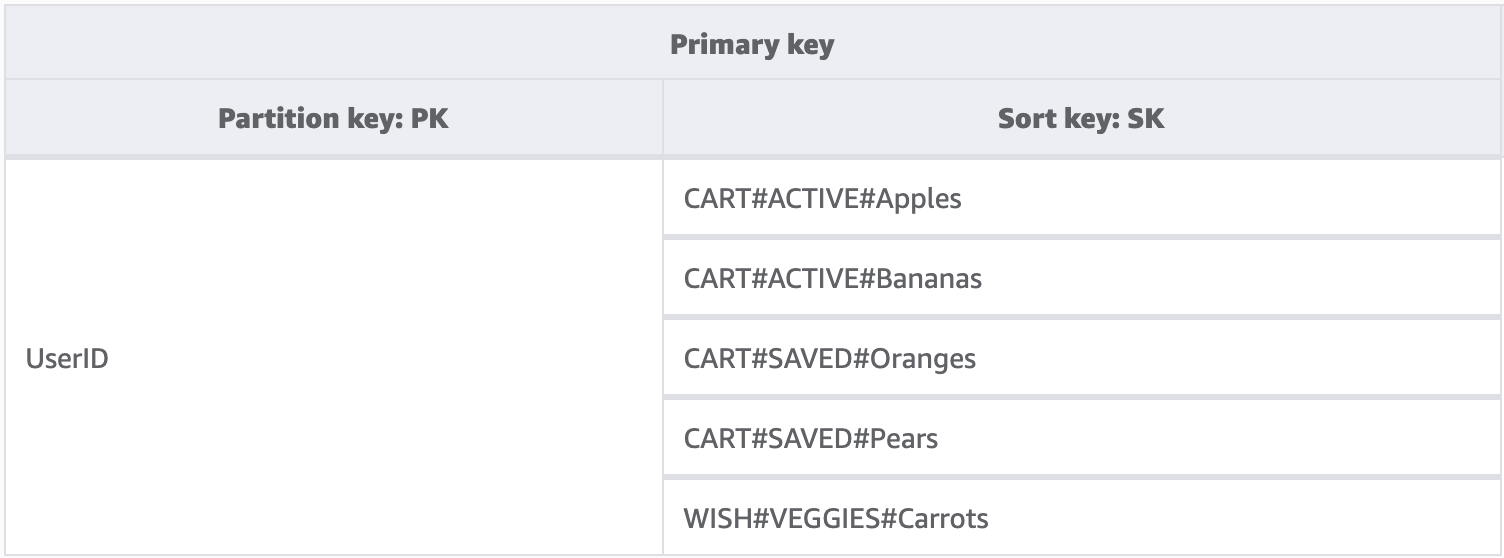
Embora uma chave de partição no DynamoDB sempre exija o valor exato para consulta de dados, podemos aplicar uma condição parcial à chave de classificação da esquerda para a direita, de modo semelhante a percorrer uma árvore binária.
No exemplo acima, temos uma loja de comércio eletrônico em que é necessário manter o carrinho de compras em todas as sessões do usuário. Sempre que o usuário fizer login, talvez queira ver o carrinho de compras completo, incluindo itens salvos para outro momento. Porém, quando ele entra na finalização da compra, somente os itens no carrinho ativo devem ser carregados para compra. Como ambas as KeyConditions solicitam explicitamente as chaves de classificação CART, os dados adicionais da lista de desejos simplesmente são ignorados pelo DynamoDB no momento da leitura. Embora os itens salvos e ativos façam parte do mesmo carrinho, precisamos tratá-los de forma distinta em diferentes partes da aplicação. Portanto, aplicar uma KeyCondition ao prefixo da chave de classificação é a melhor maneira de recuperar somente os dados necessários para cada parte da aplicação.
Principais atributos deste componente básico
-
Os itens relacionados são armazenados lado a lado no mesmo local para tornar o acesso aos dados eficaz.
-
Por meio de expressões
KeyCondition, é possível recuperar seletivamente os subconjuntos da hierarquia, o que significa que não há desperdício de RCUs. -
Diferentes partes da aplicação podem armazenar os respectivos itens sob um prefixo específico, evitando itens sobrescritos ou gravações conflitantes.
Componente básico: multilocação
Muitos clientes usam o DynamoDB para hospedar dados de aplicações de vários locatários. Para essas circunstâncias, nosso objetivo é projetar o esquema de uma forma que mantenha todos os dados de um único locatário em sua própria partição lógica da tabela. Essa ideia se baseia no conceito de coleção de itens, que é um termo para todos os itens em uma tabela do DynamoDB que têm a mesma chave de partição. Para obter mais informações sobre como o DynamoDB aborda a multilocação, consulte Multilocação no DynamoDB.
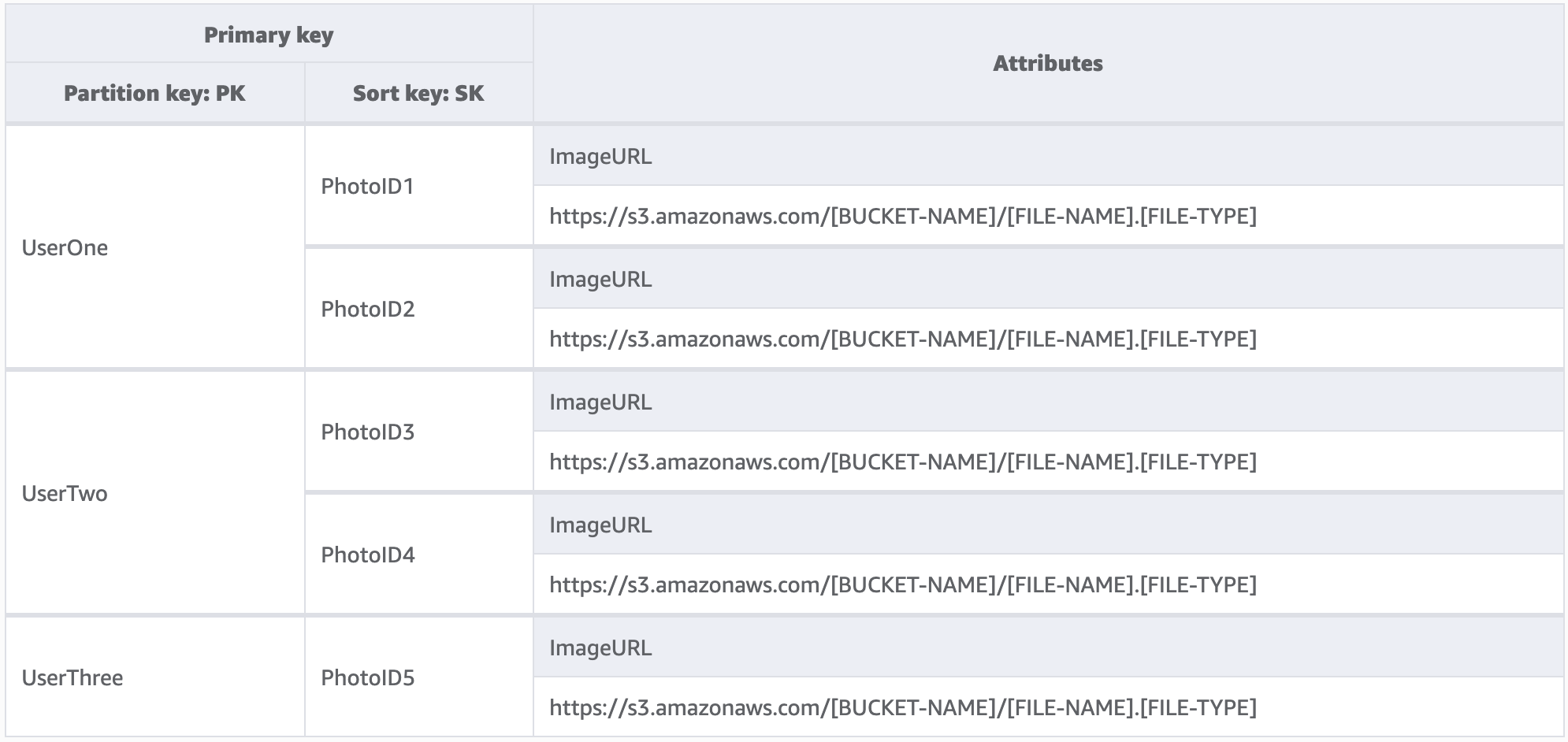
Neste exemplo, estamos administrando um site de hospedagem que provavelmente tem milhares de usuários. Inicialmente, cada usuário só carregará fotos em seu próprio perfil, mas, por padrão, não permitiremos que um veja as fotos do outro. Em condições ideais, seria adicionado um nível a mais de isolamento à autorização da chamada de cada usuário à sua API para garantir que todos solicitem apenas dados da partição deles. Entretanto, no nível do esquema, chaves de partição exclusivas são adequadas.
Principais atributos deste componente básico
-
A quantidade de dados lidos por qualquer usuário ou locatário só pode ser igual à quantidade total de itens na partição dele.
-
A remoção dos dados de um locatário devido ao encerramento de uma conta ou a uma solicitação de conformidade pode ser feita de forma discreta e econômica. Basta realizar uma consulta em que a chave de partição seja igual ao ID do locatário e, em seguida, executar uma operação
DeleteItempara cada chave primária retornada.
nota
Como a multilocação faz parte do conceito, é possível usar diferentes provedores de chaves de criptografia em uma única tabela para isolar dados com segurança. AWS O SDK de criptografia de banco de dados para o Amazon DynamoDB possibilita que você inclua criptografia do lado do cliente em workloads do DynamoDB. Você pode realizar a criptografia em cada atributo, o que permite criptografar valores de atributos específicos antes de armazená-los na tabela do DynamoDB e pesquisar atributos criptografados sem descriptografar o banco de dados inteiro de antemão.
Componente básico: índice esparso
Às vezes, um padrão de acesso exige a busca de itens que correspondam a um item raro ou recebam um status (o que exige uma resposta escalada). Em vez de consultar regularmente todo o conjunto de dados em busca desses itens, podemos nos valer do fato de os índices secundários globais (GSI) serem escassamente carregados de dados. Isso significa que apenas os itens na tabela base que tenham os atributos definidos no índice serão replicados no índice.
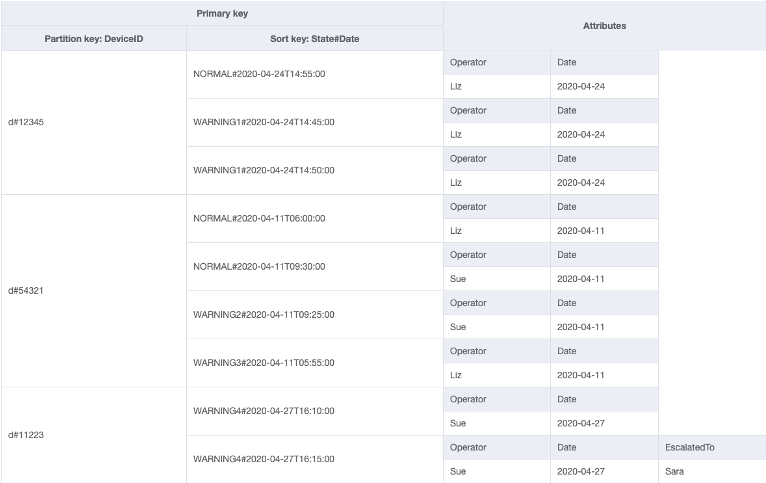

Neste exemplo, vemos um caso de uso de IoT em que cada dispositivo no campo relata um status regularmente. Na maioria dos relatórios, esperamos que o dispositivo informe que está tudo bem, mas às vezes pode haver uma falha e ser necessário encaminhá-la a um técnico de reparos. Para relatórios com escalonamento, o atributo EscalatedTo é adicionado ao item, mas não está presente de outra forma. Neste exemplo, o GSI é particionado por EscalatedTo e, como ele traz as chaves da tabela base, ainda podemos ver qual DeviceID relatou a falha e em que momento.
Embora no DynamoDB as leituras sejam mais baratas do que as gravações, os índices esparsos são uma ferramenta muito eficaz para casos de uso em que as instâncias de um tipo específico de item são raras mas as leituras para encontrá-las são comuns.
Principais atributos deste componente básico
-
Os custos de gravação e armazenamento do GSI esparso só se aplicam a itens que correspondam ao padrão de chave; portanto, o custo do GSI pode ser significativamente menor do que o de outros GSIs em que todos os itens são replicados neles.
-
É possível também usar uma chave de classificação composta para restringir ainda mais os itens que correspondam à consulta desejada; por exemplo, um carimbo de data e hora pode ser usado para que a chave de classificação veja somente as falhas relatadas nos últimos X minutos (). (
SK > 5 minutes ago, ScanIndexForward: False)
Componente básico: vida útil
A maioria dos dados tem um tempo durante o qual se considera útil mantê-los em um datastore primário. Para lidar com o envelhecimento dos dados no DynamoDB, ele tem um atributo chamado vida útil (TTL). O TTL possibilita definir um recurso específico por tabela que precisa ser monitorado em relação a itens com um carimbo de data e hora de época (que esteja no passado). Isso possibilita que você exclua registros expirados da tabela gratuitamente.
nota
Se estiver usando Global Tables versão 2019.11.21 (atual) das tabelas globais e também usar o recurso Vida útil, o DynamoDB replicará as exclusões do TTL em todas as tabelas de réplica. A exclusão inicial do TTL não consome capacidade de gravação na região onde o TTL expira. No entanto, a exclusão do TTL replicada para as tabelas-réplica consome capacidade de gravação replicada em cada uma das regiões de réplica e, nesse caso, se aplicam cobranças.
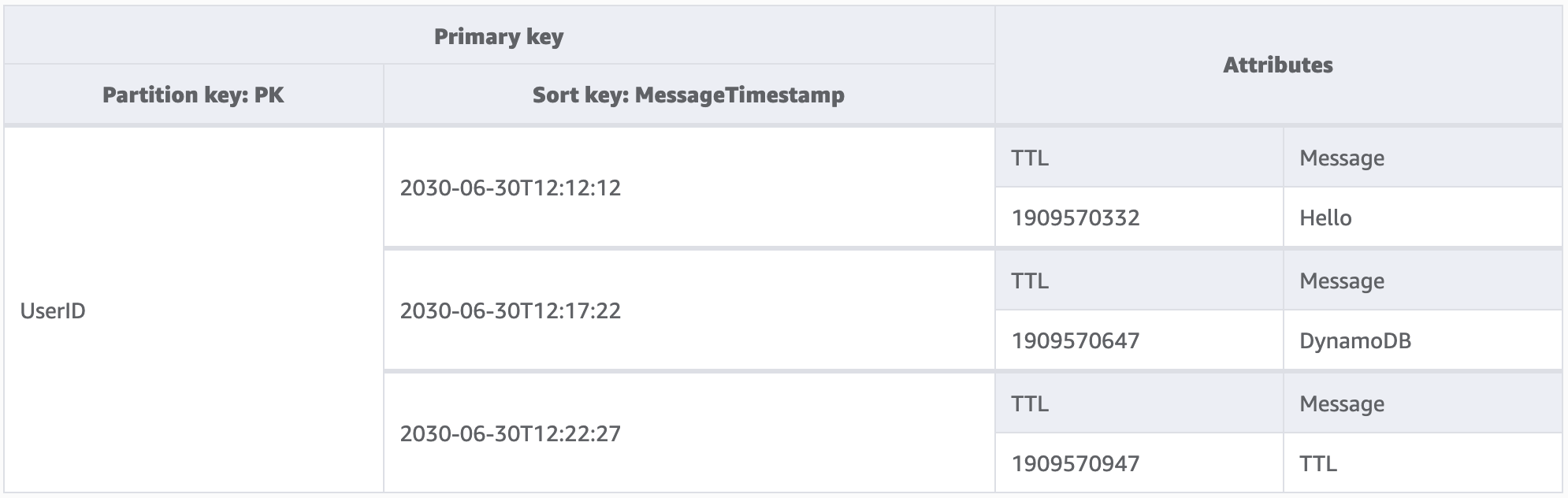
Neste exemplo, temos uma aplicação projetada para permitir que um usuário crie mensagens de curta duração. Quando se cria uma mensagem no DynamoDB, o atributo TTL é definido como uma data de sete dias no futuro pelo código da aplicação. Em aproximadamente sete dias, o DynamoDB verificará se o carimbo de data e hora de época desses itens está no passado e os excluirá.
Como as exclusões feitas pelo TTL são gratuitas, é altamente recomendável usar esse atributo para remover dados históricos da tabela. Isso reduzirá a conta geral de armazenamento a cada mês e provavelmente diminuirá os custos das leituras do usuário, pois haverá menos dados a serem recuperados pelas consultas. Embora o TTL seja habilitado em nível de tabela, cabe a você decidir para quais itens ou entidades criará um atributo TTL e definir o carimbo de data e hora de época futuro.
Principais atributos deste componente básico
-
As exclusões de TTL são executadas nos bastidores e não afetam a performance da tabela
-
Embora o TTL seja um processo assíncrono que é executado a cada 6 horas, aproximadamente, a exclusão de um registro expirado pode levar mais de 48 horas.
-
Não conte com as exclusões de TTL para casos de uso, como registros de bloqueio ou gerenciamento de estado, se houver necessidade de limpar dados obsoletos em menos de 48 horas
-
-
Você pode dar um nome de atributo válido ao TTL, mas o valor deve ser numérico.
Componente básico: vida útil para arquivamento
Embora o TTL seja uma ferramenta eficaz para excluir dados antigos do DynamoDB, muitos casos de uso exigem que os dados sejam mantidos arquivados por um período mais longo do que o do datastore primário. Nesse caso, podemos utilizar a exclusão cronometrada de registros do TTL para enviar registros expirados a um datastore de longo prazo.
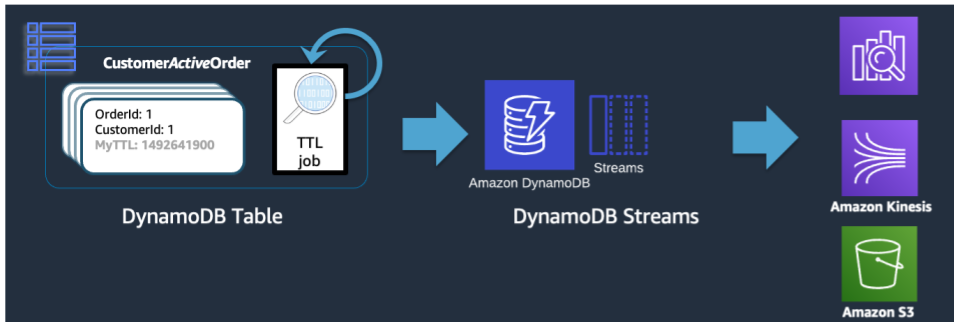
Quando uma exclusão de TTL é feita pelo DynamoDB, ela ainda é enviada ao DynamoDB Stream como um evento Delete. No entanto, quando a exclusão é realizada pelo TTL do DynamoDB, há um atributo principal:dynamodb no registro de fluxo. Usando um assinante do Lambda do DynamoDB Stream, podemos aplicar um filtro de eventos somente ao atributo da entidade principal do DynamoDB e ter certeza de que todos os registros que correspondam a esse filtro sejam enviados a um armazenamento de arquivos, como o Amazon Glacier.
Principais atributos deste componente básico
-
Quando as leituras de baixa latência do DynamoDB não são mais necessárias para os itens históricos, migrá-las para um serviço de armazenamento mais frio, como o Amazon Glacier, pode reduzir significativamente os custos de armazenamento e, ao mesmo tempo, atender às necessidades de conformidade de dados de seu caso de uso.
-
Se os dados persistirem no Amazon S3, poderão ser usadas ferramentas de análise econômicas, como o Amazon Athena ou o Redshift Spectrum, para realizar análises históricas dos dados.
Componente básico: particionamento vertical
Os usuários que já conhecem um banco de dados de modelos de documentos estarão familiarizados com a ideia de armazenar todos os dados relacionados em um único documento JSON. Embora o DynamoDB seja compatível com tipos de dados JSON, ele não comporta a execução de KeyConditions em JSON aninhado. Como KeyConditions são os fatores que determinam a quantidade de dados lidos do disco e, efetivamente, quantas RCUs uma consulta consome, isso pode gerar ineficiência em grande escala. Para otimizar ainda mais as gravações e leituras do DynamoDB, recomendamos dividir as entidades individuais do documento em itens individuais do DynamoDB, técnica também chamada de particionamento vertical.

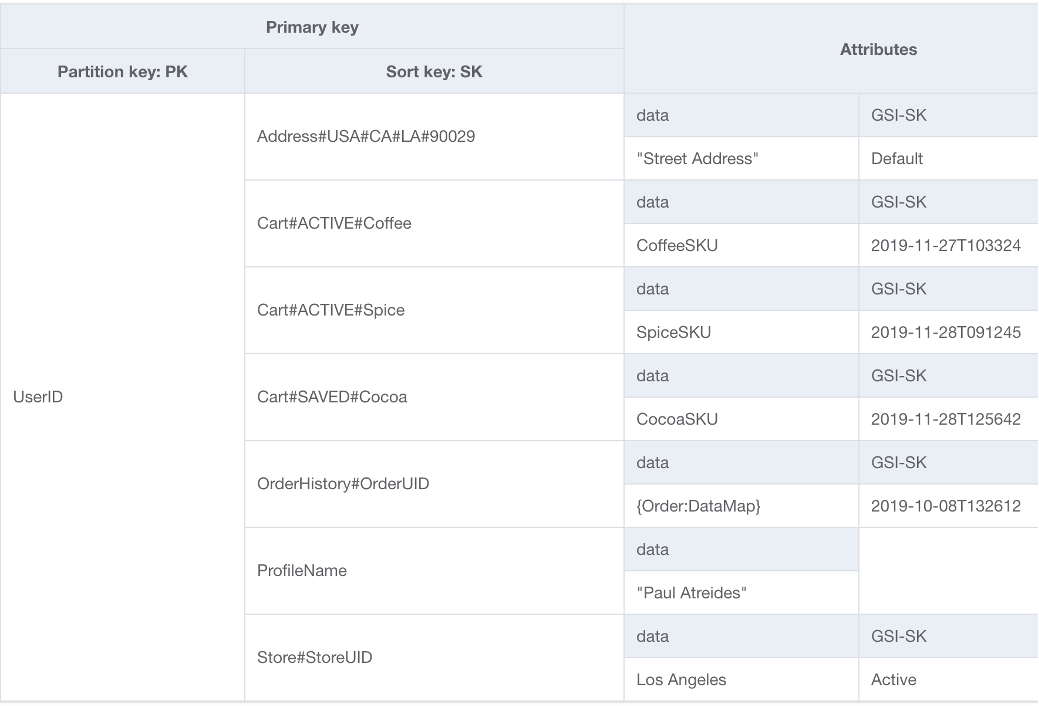
O particionamento vertical, conforme mostrado acima, é um exemplo básico de design de tabela única em ação, mas também é possível implementá-lo em várias tabelas, se desejado. Como o DynamoDB fatura as gravações em incrementos de 1 KB, o ideal é particionar o documento de uma maneira que resulte em itens com menos de 1 KB.
Principais atributos deste componente básico
-
Uma hierarquia de relacionamentos de dados é mantida por meio de prefixos de chave de classificação para que seja possível reconstruir a estrutura singular do documento no lado do cliente, se necessário.
-
É possível atualizar componentes singulares da estrutura de dados de maneira independente, o que resulta em atualizações de itens tão pequenos quanto 1 WCU.
-
Usando a chave de classificação
BeginsWith, a aplicação pode recuperar dados semelhantes em uma única consulta, agregando custos de leitura para reduzir o custo e latência totais. -
Documentos grandes podem ultrapassar facilmente o limite de tamanho de item individual de 400 KB no DynamoDB, e o particionamento vertical ajuda a contornar esse limite
Componente básico: fragmentação de gravação
Um dos poucos limites rígidos do DynamoDB é a restrição ao throughput que uma única partição física pode manter por segundo (não necessariamente uma única chave de partição). No momento, esses limites são:
-
1.000 WCU (ou 1.000 <= 1 KB itens gravados por segundo) e 3.000 RCU (ou 3.000 <= 4 KB de leituras por segundo) altamente consistentes ou
-
6.000 leituras <= 4 KB por segundo finais consistentes
Caso as solicitações da tabela excedam qualquer um desses limites, um erro é enviado de volta ao SDK do cliente ThroughputExceededException, mais comumente chamado de controle de utilização. Os casos de uso que exigem operações de leitura além desse limite geralmente são mais bem atendidos por meio da colocação de um cache de leitura na frente do DynamoDB, mas as operações de gravação exigem um design em nível de esquema conhecido como fragmentação de gravação.
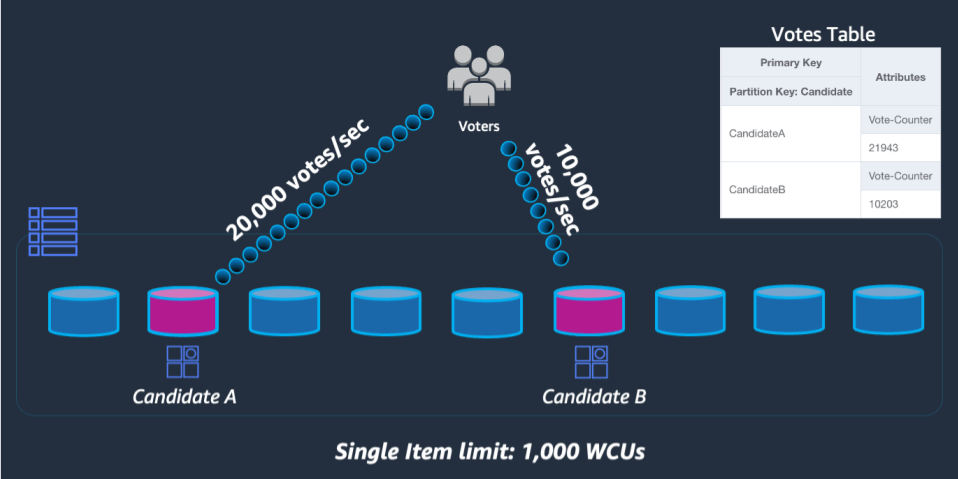
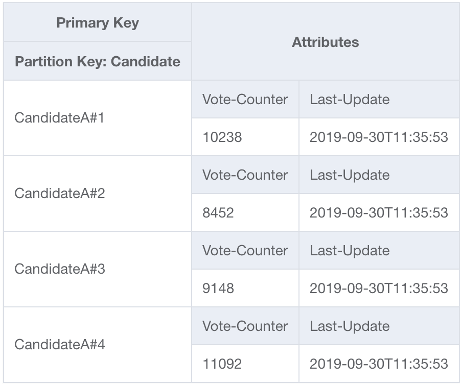
Para resolver esse problema, acrescentaremos um número inteiro aleatório ao final da chave de partição para cada candidato no código UpdateItem da aplicação. O intervalo do gerador de números inteiros aleatórios precisará ter um limite superior correspondente ou acima da quantidade esperada de gravações por segundo para determinado candidato dividido por 1.000. Para atender a 20.000 votos por segundo, teríamos rand(0,19). Agora que os dados estão armazenados em partições lógicas separadas, eles devem ser combinados novamente no momento da leitura. Como o total de votos não precisa ser em tempo real, uma função do Lambda programada para ler todas as partições de votos a cada X minutos pode realizar uma agregação ocasional para cada candidato e gravá-la de volta em um único registro de total de votos para leituras ao vivo.
Principais atributos deste componente básico
-
Para casos de uso com um throughput extremamente alto para determinada chave de partição que não pode ser evitada, as operações de gravação podem ser distribuídas artificialmente por várias partições do DynamoDB.
-
Os GSIs com uma chave de partição com baixa cardinalidade também devem utilizar esse padrão, pois o controle de utilização em um GSI aplicará uma pressão contrária nas operações de gravação na tabela base.
