Monitoramento das atualizações de status do dispositivo no DynamoDB
Esse caso de uso aborda o uso do DynamoDB para monitorar atualizações de status de dispositivos (ou alterações no estado dos dispositivos) no DynamoDB.
Caso de uso
Em casos de uso de IoT (uma fábrica inteligente, por exemplo), muitos dispositivos precisam ser monitorados pelos operadores e eles enviam periodicamente seus status ou logs para um sistema de monitoramento. Quando há um problema com um dispositivo, o status dele muda de normal para aviso. Existem diferentes níveis ou status de log, dependendo da gravidade e do tipo de comportamento anormal no dispositivo. O sistema então designa um operador para verificar o dispositivo e ele pode encaminhar o problema ao supervisor, se necessário.
Alguns padrões de acesso típicos desse sistema incluem:
-
Criar entrada de log para um dispositivo
-
Obter todos os logs de um estado específico do dispositivo, mostrando primeiro os logs mais recentes
-
Obter todos os logs de determinado operador entre duas datas
-
Obter todos os logs encaminhados a determinado supervisor
-
Obter todos os logs encaminhados com um estado de dispositivo específico para determinado supervisor
-
Obter todos os logs encaminhados com um estado de dispositivo específico para determinado supervisor em uma data específica
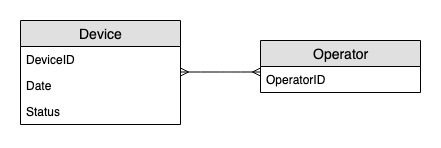
Diagrama de relacionamento de entidades
Este é o diagrama de relacionamento de entidades (ERD) que usaremos para monitorar atualizações de status de dispositivos.
Padrões de acesso
Esses são os padrões de acesso que vamos considerar para monitorar atualizações de status de dispositivos.
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
Evolução do design do esquema
Etapa 1: abordar os padrões de acesso 1 (createLogEntryForSpecificDevice) e 2 (getLogsForSpecificDevice)
A unidade de escala de um sistema de rastreamento de dispositivos seriam dispositivos individuais. Nesse sistema, um deviceID identifica de forma exclusiva um dispositivo. Isso tornar deviceID um bom candidato para a chave de partição. Cada dispositivo envia informações ao sistema de rastreamento periodicamente (digamos, a cada cinco minutos, mais ou menos). Essa ordem torna a data um critério lógico de classificação e, portanto, a chave de classificação. Os dados de amostra, nesse caso, ficariam mais ou menos assim:
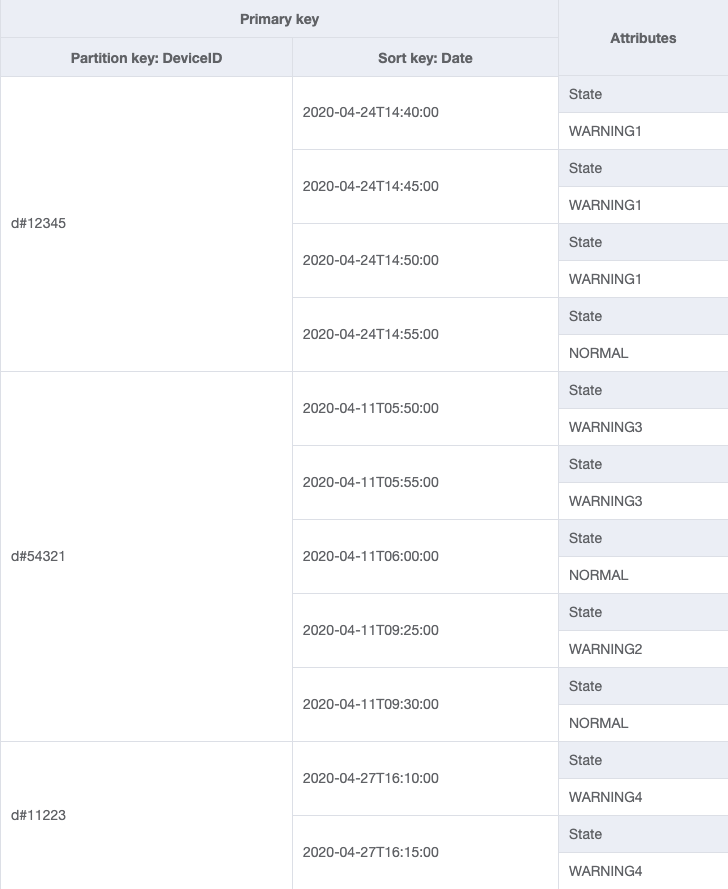
Para buscar entradas de log para um dispositivo específico, podemos realizar uma operação de consulta com a chave de partição DeviceID="d#12345".
Etapa 2: abordar o padrão de acesso 3 (getWarningLogsForSpecificDevice)
Como State é um atributo não chave, abordar o padrão de acesso 3 com o esquema atual exigiria uma expressão de filtro. No DynamoDB, as expressões de filtro são aplicadas depois que os dados são lidos usando expressões de condição de chave. Por exemplo, se fôssemos obter os logs de aviso para d#12345, a operação de consulta com a chave de partição DeviceID="d#12345" leria quatro itens da tabela acima e, depois, filtraria o único item sem o status aviso. Essa abordagem não é eficiente em grande escala. Uma expressão de filtro pode ser uma boa maneira de excluir itens que são consultados se a proporção de itens excluídos for baixa ou se a consulta for realizada com pouca frequência. No entanto, nos casos em que muitos itens são recuperados de uma tabela e a maioria dos itens é excluída após a filtragem, podemos continuar desenvolvendo nosso design de tabela para que funcione com maior eficiência.
Vamos mudar a forma de lidar com esse padrão de acesso usando chaves de classificação compostas. É possível importar dados de amostra do DeviceStateLog_3.jsonState#Date. Essa chave de classificação é a composição dos atributos State, # e Date. Nesse exemplo, # é usado como um delimitador. Os dados agora ficam mais ou menos assim:
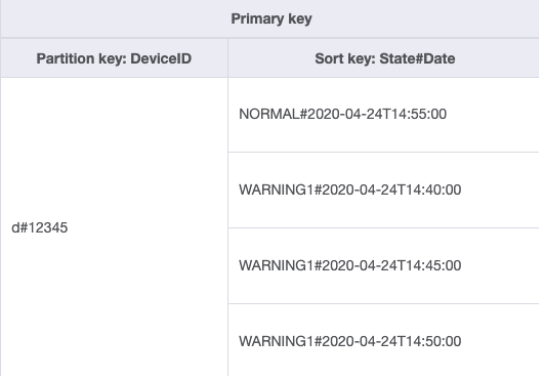
Para obter somente logs de aviso de um dispositivo, a consulta se torna mais direcionada com esse esquema. A condição de chave para a consulta usa a chave de partição DeviceID="d#12345" e a chave de classificação State#Date begins_with
“WARNING”. Essa consulta lerá somente os três itens relevantes com o estado aviso.
Etapa 3: abordar o padrão de acesso 4 (getLogsForOperatorBetweenTwoDates)
É possível importar DeviceStateLog_4.jsonOperator foi adicionado à tabela DeviceStateLog com dados de exemplo.
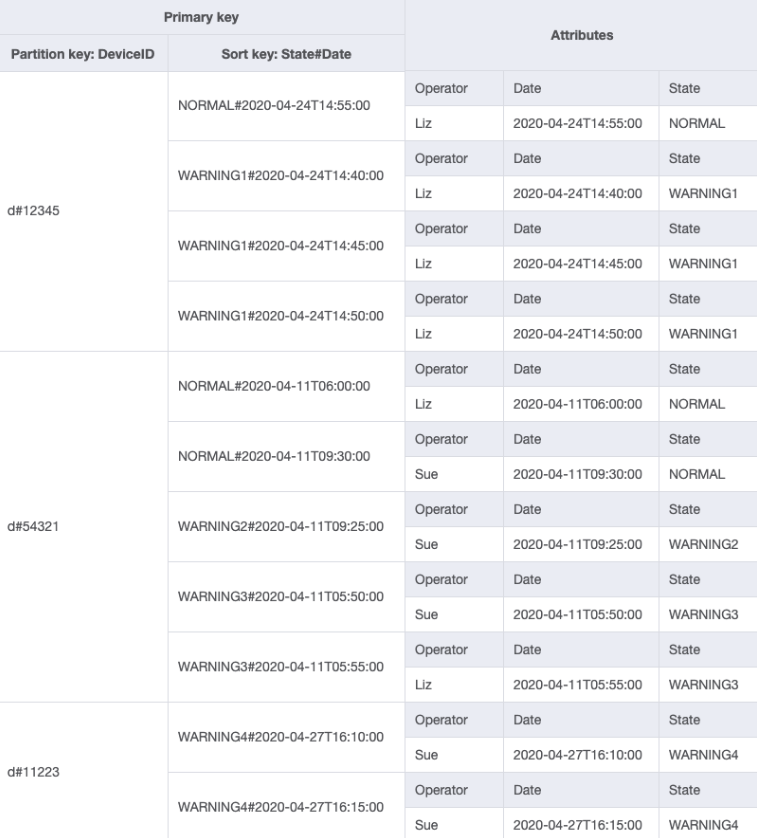
Como no momento Operator não é uma chave de partição, não há como realizar uma pesquisa direta de chave-valor nessa tabela com base em OperatorID. Precisaremos criar uma coleção de itens com um índice secundário global em OperatorID. O padrão de acesso requer uma pesquisa com base em datas, então Data é o atributo da chave de classificação do índice secundário global (GSI). É assim que o GSI se parece agora:
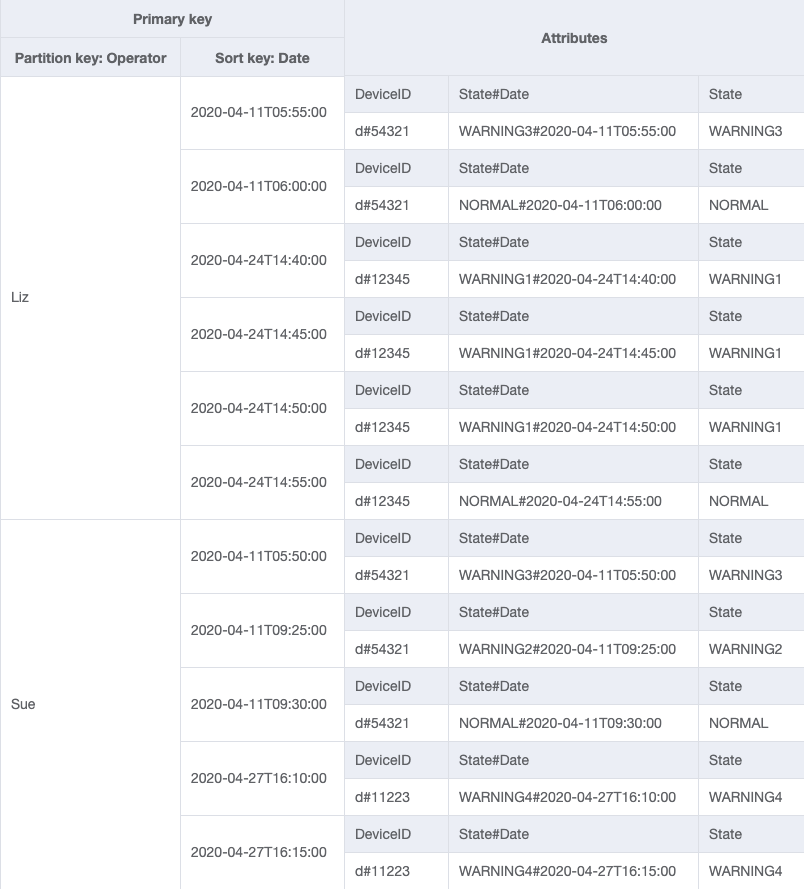
Para o padrão de acesso 4 (getLogsForOperatorBetweenTwoDates), é possível consultar esse GSI com a chave de partição OperatorID=Liz e a chave de classificação Date entre 2020-04-11T05:58:00 e 2020-04-24T14:50:00.
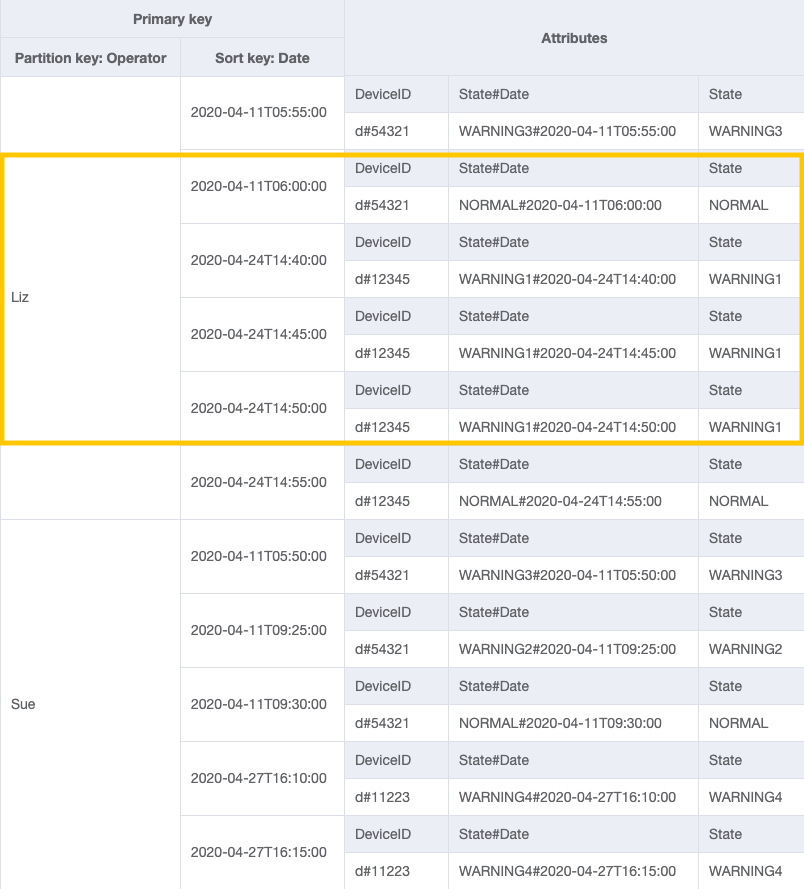
Etapa 4: abordar os padrões de acesso 5 (getEscalatedLogsForSupervisor), 6 (getEscalatedLogsWithSpecificStatusForSupervisor) e 7 (getEscalatedLogsWithSpecificStatusForSupervisorForDate)
Usaremos um índice esparso para abordar esses padrões de acesso.
Os índices secundários globais são esparsos por padrão; portanto, somente os itens na tabela base que contêm atributos de chave primária do índice realmente aparecerão no índice. Essa é outra forma de excluir itens que não são relevantes para o padrão de acesso que está sendo modelado.
É possível importar DeviceStateLog_6.jsonEscalatedTo foi adicionado à tabela DeviceStateLog com dados de exemplo. Conforme mencionado anteriormente, nem todos os logs são encaminhados para um supervisor.
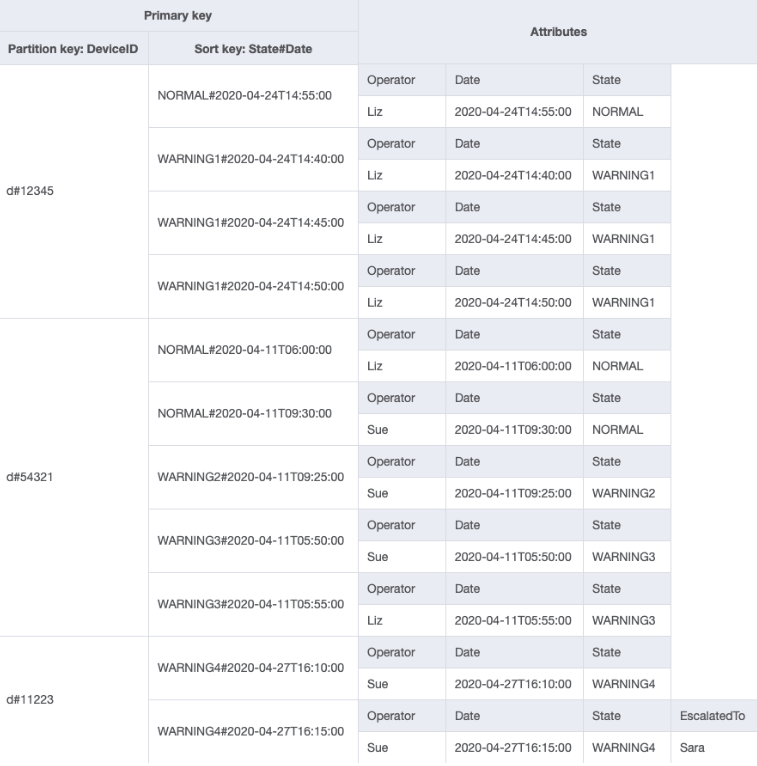
Agora você pode criar um novo GSI em que EscalatedTo é a chave de partição e State#Date é a chave de classificação. Observe que somente itens que têm ambos os atributos EscalatedTo e State#Date aparecem no índice.

O restante dos padrões de acesso está resumido da seguinte forma:
Todos os padrões de acesso e a forma como o design do esquema os aborda estão resumidos na tabela abaixo:
| Padrão de acesso | Tabela base/GSI/LSI | Operation | Valor da chave de partição | Valores de chave de classificação | Outras condições/filtros |
|---|---|---|---|---|---|
| createLogEntryForSpecificDevice | Tabela base | PutItem | DeviceID=deviceId | State#Date=state#date | |
| getLogsForSpecificDevice | Tabela base | Consulta | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = False |
| getWarningLogsForSpecificDevice | Tabela base | Consulta | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| getLogsForOperatorBetweenTwoDates | GSI-1 | Consulta | Operator=operatorName | Data entre date1 e date2 | |
| getEscalatedLogsForSupervisor | GSI-2 | Consulta | EscalatedTo=supervisorName | ||
| getEscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | Consulta | EscalatedTo=supervisorName | State#Date begins_with "state1#" | |
| getEscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | Consulta | EscalatedTo=supervisorName | State#Date begins_with "state1#date1" |
Esquema final
Veja aqui os designs do esquema final. Para baixar esse design de esquema como arquivo JSON, consulte DynamoDB Examples
Tabela base
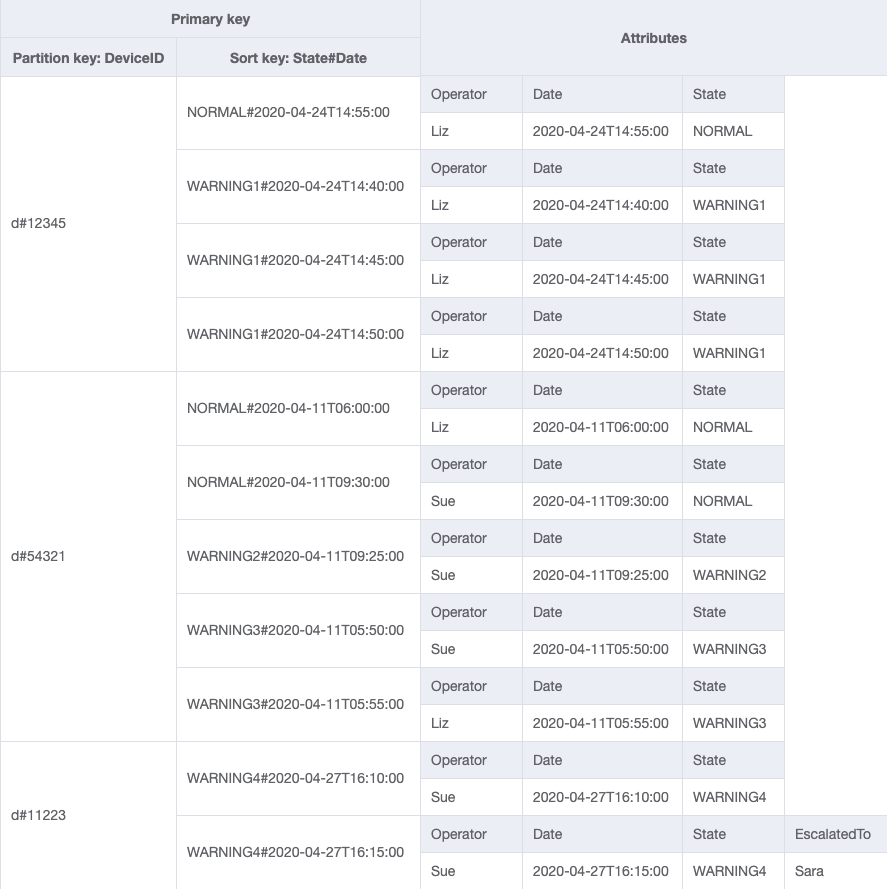
GSI-1
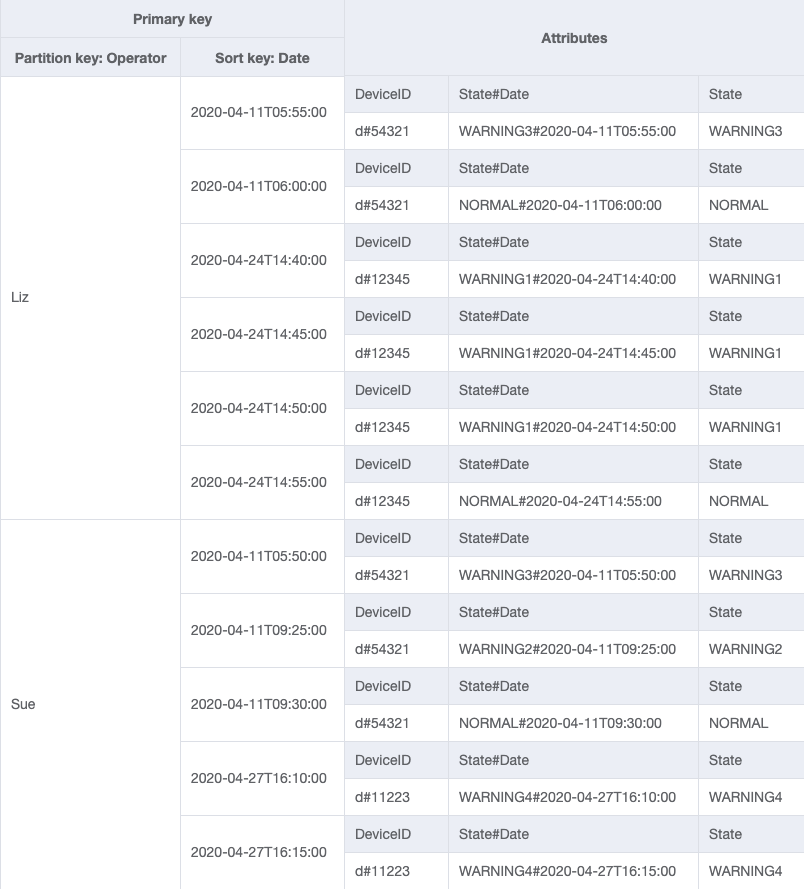
GSI-2
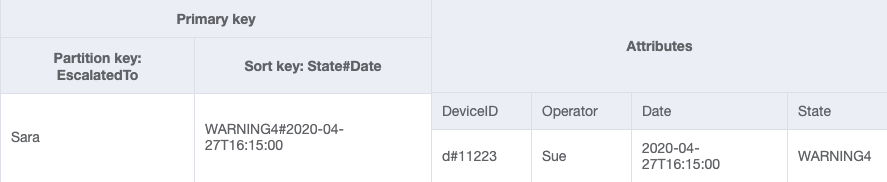
Como usar o NoSQL Workbench com esse design de esquema
Você pode importar esse esquema final para o NoSQL Workbench, uma ferramenta visual que fornece atributos de modelagem de dados, visualização de dados e desenvolvimento de consultas para o DynamoDB, se quiser explorar e editar ainda mais seu novo projeto. Para começar, siga estas etapas:
-
Baixe o NoSQL Workbench. Para obter mais informações, consulte Baixar o NoSQL Workbench para DynamoDB.
-
Baixe o arquivo do esquema JSON listado acima, que já está no formato do modelo NoSQL Workbench.
-
Importe o arquivo do esquema JSON para o NoSQL Workbench. Para obter mais informações, consulte Importar um modelo de dados existente.
-
Depois de importar para o NOSQL Workbench, você pode editar o modelo de dados. Para obter mais informações, consulte Editar um modelo de dados existente.
