Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Transcripciones alternativas
Cuando Amazon Transcribe transcribe audio, crea diferentes versiones de la misma transcripción y asigna una puntuación de confianza a cada versión. En una transcripción típica, sólo se obtiene la versión con la puntuación de confianza más alta.
Si activas las transcripciones alternativas, Amazon Transcribe devuelve otras versiones de la transcripción que tengan niveles de confianza más bajos. Puede elegir una devolución de hasta 10 transcripciones alternativas. Si especifica un número de alternativas superior al que Amazon Transcribe identifica, solo se devolverá el número real de alternativas.
Todas las alternativas se ubican en el mismo archivo de salida de la transcripción y se presentan a nivel de segmento. Los segmentos se definen a través de las pausas naturales del habla, como un cambio de interlocutor o una pausa en el audio.
Las transcripciones alternativas sólo están disponibles para las transcripciones por lotes.
El resultado de la transcripción está estructurado de la siguiente manera. Los puntos suspensivos (...) de los ejemplos de código indican dónde se ha eliminado el contenido por motivos de brevedad.
Una transcripción final completa de un segmento determinado.
"results": { "language_code": "en-US", "transcripts": [ { "transcript": "The amazon is the largest rainforest on the planet." } ],Una puntuación de confianza para cada palabra de la sección de
transcriptanterior."items": [ { "start_time": "1.15", "end_time": "1.35", "alternatives": [ { "confidence": "1.0", "content": "The" } ], "type": "pronunciation" }, { "start_time": "1.35", "end_time": "2.05", "alternatives": [ { "confidence": "1.0", "content": "amazon" } ], "type": "pronunciation" },-
Las transcripciones alternativas se encuentran en la parte
segmentsdel resultado de la transcripción. Las alternativas para cada segmento se ordenan por puntuación de confianza descendente."segments": [ { "start_time": "1.04", "end_time": "5.065", "alternatives": [ {..."transcript": "The amazon is the largest rain forest on the planet.", "items": [ { "start_time": "1.15", "confidence": "1.0", "end_time": "1.35", "type": "pronunciation", "content": "The" },...{ "start_time": "3.06", "confidence": "0.0037", "end_time": "3.38", "type": "pronunciation", "content": "rain" }, { "start_time": "3.38", "confidence": "0.0037", "end_time": "3.96", "type": "pronunciation", "content": "forest" }, -
Un status al final del resultado de la transcripción.
"status": "COMPLETED" }
Solicitud de transcripciones alternativas
Puede solicitar transcripciones alternativas mediante AWS Management ConsoleAWS CLI, o AWS SDKs; consulte los siguientes ejemplos:
-
Inicie sesión en la AWS Management Console
. -
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
-
Rellene los campos que desee incluir en la página Especificar los detalles del trabajo y, a continuación, seleccione Siguiente. Esto lo llevará a la página Configurar trabajo: opcional.
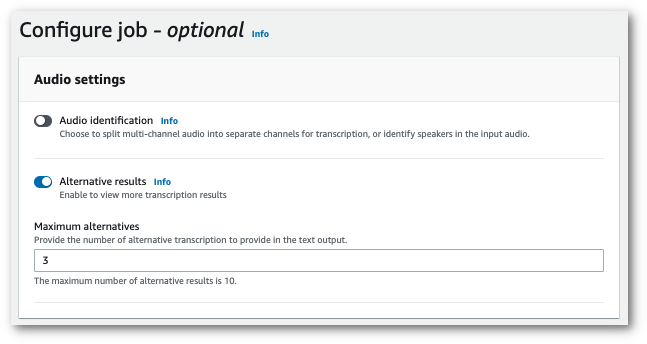
Seleccione Resultados alternativos y especifique el número máximo de alternativas que desee incluir en el resultado de la transcripción.
-
Seleccione Crear trabajo para ejecutar su trabajo de transcripción.
-
Inicie sesión en la AWS Management Console
. -
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
-
Rellene los campos que desee incluir en la página Especificar los detalles del trabajo y, a continuación, seleccione Siguiente. Esto lo llevará a la página Configurar trabajo: opcional.
Seleccione Resultados alternativos y especifique el número máximo de alternativas que desee incluir en el resultado de la transcripción.
-
Seleccione Crear trabajo para ejecutar su trabajo de transcripción.
En este ejemplo se utilizan el start-transcription-jobShowAlternatives el parámetro. Para obtener más información, consulte StartTranscriptionJob y ShowAlternatives.
Tenga en cuenta que si incluye ShowAlternatives=true en su solicitud, también debe incluir MaxAlternatives.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ShowAlternatives=true,MaxAlternatives=4
Este es otro ejemplo en el que se utiliza el start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-alt-transcription-job.json
El archivo my-first-alt-transcription-job.json contiene el siguiente cuerpo de solicitud.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Settings": {
"ShowAlternatives": true,
"MaxAlternatives": 4
}
}En el siguiente ejemplo, se utiliza AWS SDK para Python (Boto3) para solicitar transcripciones alternativas mediante el ShowAlternatives argumento del método start_transcription_job.StartTranscriptionJob y ShowAlternatives.
Para ver más ejemplos en los que se utilizan escenarios y servicios cruzados AWS SDKs, incluidos ejemplos específicos de funciones, consulte el capítulo. Ejemplos de código para Amazon Transcribe usando AWS SDKs
Tenga en cuenta que si incluye 'ShowAlternatives':True en su solicitud, también debe incluir MaxAlternatives.
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Settings = {
'ShowAlternatives':True,
'MaxAlternatives':4
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)