Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Etiquetado de recursos
Una etiqueta es una designación de metadatos personalizada que usted agrega a un recurso para facilitar la identificación, la organización y la búsqueda de recursos. Las etiquetas se componen de dos partes individuales: una clave de etiqueta y un valor de etiqueta. Esto se denomina par key:value.
Una clave de etiqueta normalmente representa una categoría más grande, mientras que un valor de etiqueta representa un subconjunto de esa categoría. Por ejemplo, puede tener la etiqueta Key=Color y la etiqueta Value=Blue, lo que generaría el par clave:valor Color:Blue. Tenga en cuenta de que puede establecer el valor de una etiqueta como una cadena vacía, pero no puede asignarle un valor nulo. Omitir el valor de etiqueta es lo mismo que utilizar una cadena vacía.
sugerencia
Administración de facturación y costos de AWS puede usar etiquetas para separar sus facturas en categorías dinámicas. Por ejemplo, si agrega etiquetas para representar diferentes departamentos de su empresa, por ejemplo Department:Sales o Department:Legal, AWS puede proporcionarle la distribución de costos por departamento.
En Amazon Transcribe, puedes etiquetar los siguientes recursos:
Trabajos de transcripción
Trabajos de transcripción médica
Trabajos de transcripción posterior a la llamada de Call Analytics
Vocabularios personalizados
Vocabularios médicos personalizados
Filtros de vocabulario personalizados
Categorías de análisis de llamadas
Modelos de lenguaje personalizado
Las claves de etiquetas pueden tener una longitud máxima de 128 caracteres y los valores de las etiquetas pueden tener una longitud máxima de 256 caracteres; ambas distinguen mayúsculas de minúsculas. Amazon Transcribe admite hasta 50 etiquetas por recurso. Para cada recurso, cada clave de etiqueta debe ser única y sólo puede tener un valor. Tenga en cuenta que las etiquetas no pueden empezar aws: por él porque AWS reserva este prefijo para las etiquetas generadas por el sistema. No puede agregar, modificar ni eliminar etiquetas aws:* y no cuentan para el límite de etiquetas por recurso.
Operaciones de API específicas para el etiquetado de recursos
ListTagsForResource,
TagResource,
UntagResource
Para usar las API de etiquetado, debe incluir un nombre de recurso de Amazon (ARN) en su solicitud. Los ARN tienen el formato arn:partition:service:region:account-id:resource-type/resource-id. Por ejemplo, el ARN asociado a un trabajo de transcripción puede tener el siguiente aspecto: arn:.aws:transcribe:us-west-2:111122223333:transcription-job/my-transcription-job-name
Tag-based control de acceso
Puede utilizar etiquetas para controlar el acceso dentro de su Cuentas de AWS. En el caso del control de acceso basado en etiquetas, debe proporcionar la información sobre las etiquetas en el elemento de condición de una IAM política. A continuación, puede utilizar etiquetas y su clave de condición de etiqueta asociada para controlar el acceso a:
Recursos: controle el acceso a sus Amazon Transcribe recursos en función de las etiquetas que haya asignado a esos recursos.
Para ello, utilice la clave de condición
aws:ResourceTag/para especificar qué par de clave-valor de etiqueta debe adjuntarse al recurso.key-name
Solicitud: controla qué etiquetas se pueden pasar en una solicitud.
Usa la clave de
aws:RequestTag/condición para especificar qué etiquetas se pueden añadir, modificar o eliminar de un IAM usuario o rol.key-name
Procesos de autorización: controla el acceso basado en etiquetas para cualquier parte del proceso de autorización.
Utilice la clave de condición
aws:TagKeys/para controlar si se pueden utilizar claves de etiqueta específicas en un recurso, en una solicitud o por una entidad principal. En este caso, el valor de clave no importa.
Para ver ejemplos de políticas de control de acceso basadas en etiquetas, consulte Visualización de trabajos de transcripción basados en etiquetas.
Para obtener información detallada sobre el control de acceso basado en etiquetas, consulte Control de acceso a recursos de AWS mediante etiquetas.
Añadir etiquetas a su Amazon Transcribe recursos
Puede añadir etiquetas antes o después de ejecutar su Amazon Transcribe trabajo. Con las API Create* y Start* existentes, puede agregar etiquetas a su solicitud de transcripción.
Puede agregar, modificar o eliminar etiquetas mediante AWS Management Console, AWS CLI o los SDK de AWS ; consulte los ejemplos siguientes:
-
Inicie sesión en la AWS Management Console
. -
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
-
Desplácese hasta la parte inferior de la página Especificar detalles del trabajo para buscar el cuadro Etiquetas: opcional y selecciones Añadir nueva etiqueta.
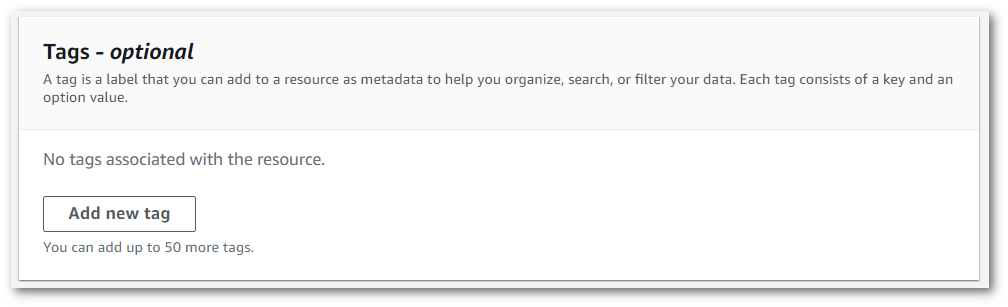
-
Complete la información para el campo Clave y, si lo desea, para el campo Valor.
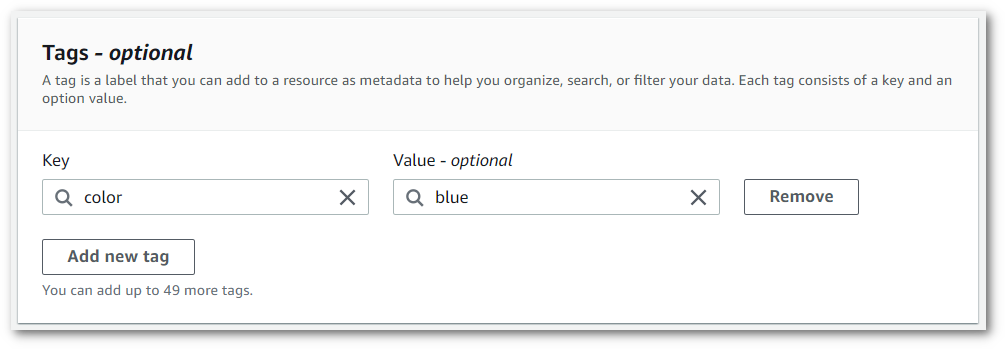
-
Rellene todos los campos que desee incluir en la página Especificar los detalles del trabajo y, a continuación, seleccione Siguiente. Esto lo llevará a la página Configurar trabajo: opcional.
Seleccione Crear trabajo para ejecutar su trabajo de transcripción.
-
Puede ver las etiquetas asociadas a un trabajo de transcripción navegando hasta la página Trabajos de transcripción, seleccionando un trabajo de transcripción y desplazándose hasta la parte inferior de la página de información de ese trabajo. Si desea editar las etiquetas, puede hacerlo seleccionando Administrar etiquetas.

En este ejemplo, se utilizan el comando start-transcription-jobTags. Para obtener más información, consulte StartTranscriptionJob y Tag.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --tags Key=color,Value=blueKey=shape,Value=square
Este es otro ejemplo en el que se usa el comando start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-tagging-job.json
El archivo my-first-vocab-table.json contiene el siguiente cuerpo de la solicitud.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Tags": [ { "Key": "color", "Value": "blue" }, { "Key": "shape", "Value": "square" } ] }
En el siguiente ejemplo, se utiliza AWS SDK para Python (Boto3) para añadir una etiqueta mediante el Tags argumento del método start_transcription_jobStartTranscriptionJob y Tag.
Para ver ejemplos adicionales sobre el uso de los AWS SDK, incluidos ejemplos de funciones específicas, escenarios y servicios cruzados, consulta el capítulo. Ejemplos de código para Amazon Transcribe usando AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Tags = [ { 'Key':'color', 'Value':'blue' } ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
