AWS Glue는 콘솔 및 API 작업을 제공하여 워크로드를 추출, 변환 및 로드(ETL)하는 것을 설정하고 관리합니다. 특정 언어의 SDK 및 AWS Command Line Interface(AWS CLI)를 통해 API 작업을 사용할 수 있습니다. AWS CLI 사용에 대한 자세한 내용은 AWS CLI Command Reference를 참조하세요.
AWS Glue는 AWS Glue Data Catalog를 사용하여 데이터 원본, 변환 및 대상의 메타데이터를 저장합니다. Data Catalog는 Apache Hive Metastore의 드롭인 교체물입니다. AWS Glue Jobs system는 데이터의 ETL 작업을 정의, 일정 관리 및 실행하기 위한 관리된 인프라를 제공합니다. AWS Glue API에 대한 자세한 내용은 AWS Glue API을 참조하십시오.
AWS Glue 콘솔
AWS Glue 콘솔을 사용하여 ETL 워크플로우를 정의하고 관리할 수 있습니다. 콘솔은 AWS Glue Data Catalog 및 AWS Glue Jobs system에서 몇 가지 API 작업을 호출하여 다음 작업을 실행합니다.
-
작업, 테이블, 크롤러 및 연결과 같은 AWS Glue 객체를 정의합니다.
-
크롤러를 실행하는 일정
-
작업 트리거를 위한 이벤트 또는 일정을 정의합니다.
-
AWS Glue 객체 목록을 검색하고 필터링합니다.
-
변환 스크립트를 편집합니다.
AWS Glue Data Catalog
AWS Glue Data Catalog는 AWS 클라우드에 있는 영구적 기술 메타데이터 스토어입니다.
각 AWS 계정에는 AWS 리전당 AWS Glue Data Catalog가 하나씩 있습니다. 각 데이터 카탈로그는 데이터베이스로 구성된 확장성이 뛰어난 테이블 모음입니다. 테이블은 Amazon RDS, Apache Hadoop 분산 파일 시스템, Amazon OpenSearch Service 등의 소스에 저장된 정형 또는 반정형 데이터 모음을 메타데이터로 표현한 것입니다. AWS Glue Data Catalog는 일정한 리포지토리를 제공합니다. 그러면 전혀 다른 시스템들이 메타데이터를 저장하고 탐색하여 데이터 사일로에서 데이터를 추적할 수 있습니다. 그런 다음 메타데이터를 사용하여 다양한 애플리케이션에서 일관된 방식으로 해당 데이터를 쿼리하고 변환할 수 있습니다.
데이터 카탈로그를 AWS Identity and Access Management 정책 및 Lake Formation과 함께 사용하여 테이블 및 데이터베이스에 대한 액세스를 제어합니다. 이렇게 하면 기업의 여러 그룹이 더 광범위한 조직에 데이터를 안전하게 게시하면서 매우 세분화된 방식으로 민감한 정보를 보호할 수 있습니다.
데이터 카탈로그는 CloudTrail 및 Lake Formation과 함께 스키마 변경 추적 및 데이터 액세스 제어와 함께 포괄적인 감사 및 거버넌스 기능도 제공합니다. 이렇게 하면 데이터가 부적절하게 수정되거나 실수로 공유되지 않도록 보장할 수 있습니다.
AWS Glue Data Catalog 보안 및 감사에 대한 자세한 내용은 다음을 참조하세요.
-
AWS Lake Formation – 자세한 내용은 AWS Lake Formation 개발자 안내서의 AWS Lake Formation이란 무엇입니까?를 참조하세요.
-
CloudTrail – 자세한 내용은 AWS CloudTrail 사용 설명서의 CloudTrail이란 무엇입니까?를 참조하세요.
다음은 AWS Glue Data Catalog를 사용하는 기타 AWS 서비스 및 오픈 소스 프로젝트입니다.
-
Amazon Athena – 자세한 내용은 Amazon Athena 사용 설명서의 테이블, 데이터베이스, 데이터 카탈로그 이해를 참조하세요.
-
Amazon Redshift Spectrum – 자세한 내용은 Amazon Redshift 데이터베이스 개발자 안내서의 Amazon Redshift Spectrum을 사용하여 외부 데이터 쿼리를 참조하세요.
-
Amazon EMR – 자세한 내용은 Amazon EMR 관리 안내서의 AWS Glue Data Catalog에 대한 Amazon EMR 액세스에 리소스 기반 정책 사용을 참조하세요.
-
Apache Hive 메타스토어용 AWS Glue Data Catalog 클라이언트 – 이 GitHub 프로젝트에 대한 자세한 내용은 AWS Glue Data Catalog Client for Apache Hive Metastore
를 참조하세요.
AWS Glue 크롤러 및 분류자
AWS Glue는 모든 종류의 리포지토리에서 데이터를 스캔하고 분류하며, 스키마 정보를 추출하고, AWS Glue Data Catalog에서 자동적으로 메타데이터를 저장하는 크롤러를 설정할 수 있습니다. AWS Glue Data Catalog를 사용하여 ETL 작업을 관리할 수 있습니다.
크롤러 및 분류자 설정 방법에 대한 자세한 내용은 크롤러를 사용하여 데이터 카탈로그 채우기 단원을 참조하십시오. AWS Glue API를 사용하는 크롤러 및 분류자를 프로그래밍하는 방법에 대한 자세한 내용은 크롤러 및 분류자 API 단원을 참조하십시오.
AWS Glue ETL 연산
Data Catalog에서 메타데이터를 사용하여 AWS Glue는 다양한 ETL 작업을 실행할 때 사용하고 수정할 수 있는 AWS Glue 확장자를 붙여 Scala 또는 PySpark(Apache Spark용 Python API) 스크립트를 자동으로 생성할 수 있습니다. 예를 들어, 원 데이터를 추출, 정리 및 변환한 다음 결과가 쿼리되고 분석될 수 있는 다른 리포지토리에 결과를 저장할 수 있습니다. 이러한 스크립트는 CSV 파일을 관계 형식으로 변환하고 Amazon Redshift에 저장할 수 있습니다.
AWS Glue ETL 기능을 사용하는 방법에 대한 자세한 내용은 Spark 스크립트 프로그래밍 단원을 참조하십시오.
AWS Glue의 스트리밍 ETL
AWS Glue를 사용하면 지속적으로 실행되는 작업을 사용하여 스트리밍 데이터에 대해 ETL 작업을 수행할 수 있습니다. AWS Glue 스트리밍 ETL은 Apache Spark Structured Streaming 엔진을 기반으로 하며 Amazon Kinesis Data Streams, Apache Kafka 및 Amazon Managed Streaming for Apache Kafka (Amazon MSK)에서 스트림을 수집할 수 있습니다. 스트리밍 ETL은 스트리밍 데이터를 정리하고 변환하여 Amazon S3 또는 JDBC 데이터 스토어에 로드할 수 있습니다. AWS Glue의 스트리밍 ETL을 사용하여 IoT 스트림, 클릭스트림 및 네트워크 로그와 같은 이벤트 데이터를 처리합니다.
스트리밍 데이터 원본의 스키마를 알고 있는 경우 Data Catalog 테이블에서 지정할 수 있습니다. 그렇지 않은 경우 스트리밍 ETL 작업에서 스키마 감지를 사용할 수 있습니다. 그런 다음 작업은 들어오는 데이터에서 스키마를 자동으로 결정합니다.
스트리밍 ETL 작업은 AWS Glue 기본 제공 변환과 Apache Spark Structured Streaming에 대한 기본 변환을 모두 사용할 수 있습니다. 자세한 내용은 Apache Spark 웹 사이트의 Operations on streaming DataFrames/Datasets
자세한 내용은 AWS Glue에서 스트리밍 ETL 작업 단원을 참조하십시오.
AWS Glue 작업 시스템
AWS Glue Jobs system는 관리된 인프라를 사용하여 ETL 워크플로우를 관리할 수 있습니다. 사용하는 스크립트를 통해 자동적으로 데이터를 다른 위치로 추출, 변환 및 전송할 수 있는 작업을 AWS Glue에 생성할 수 있습니다. 작업은 일정이 정해지고 모을 수 있고 새로운 데이터가 도착하는 것과 같은 이벤트에 의해 촉발될 수 있습니다.
AWS Glue Jobs system 사용에 대한 자세한 내용은 AWS Glue 모니터링 단원을 참조하십시오. AWS Glue Jobs system API를 사용하여 프로그래밍하는 것에 대한 자세한 내용은 작업 API 단원을 참조하십시오.
시각적 ETL 구성 요소
AWS Glue에서는 사용자가 조작할 수 있는 시각적 캔버스를 통해 ETL 작업을 생성할 수 있습니다.
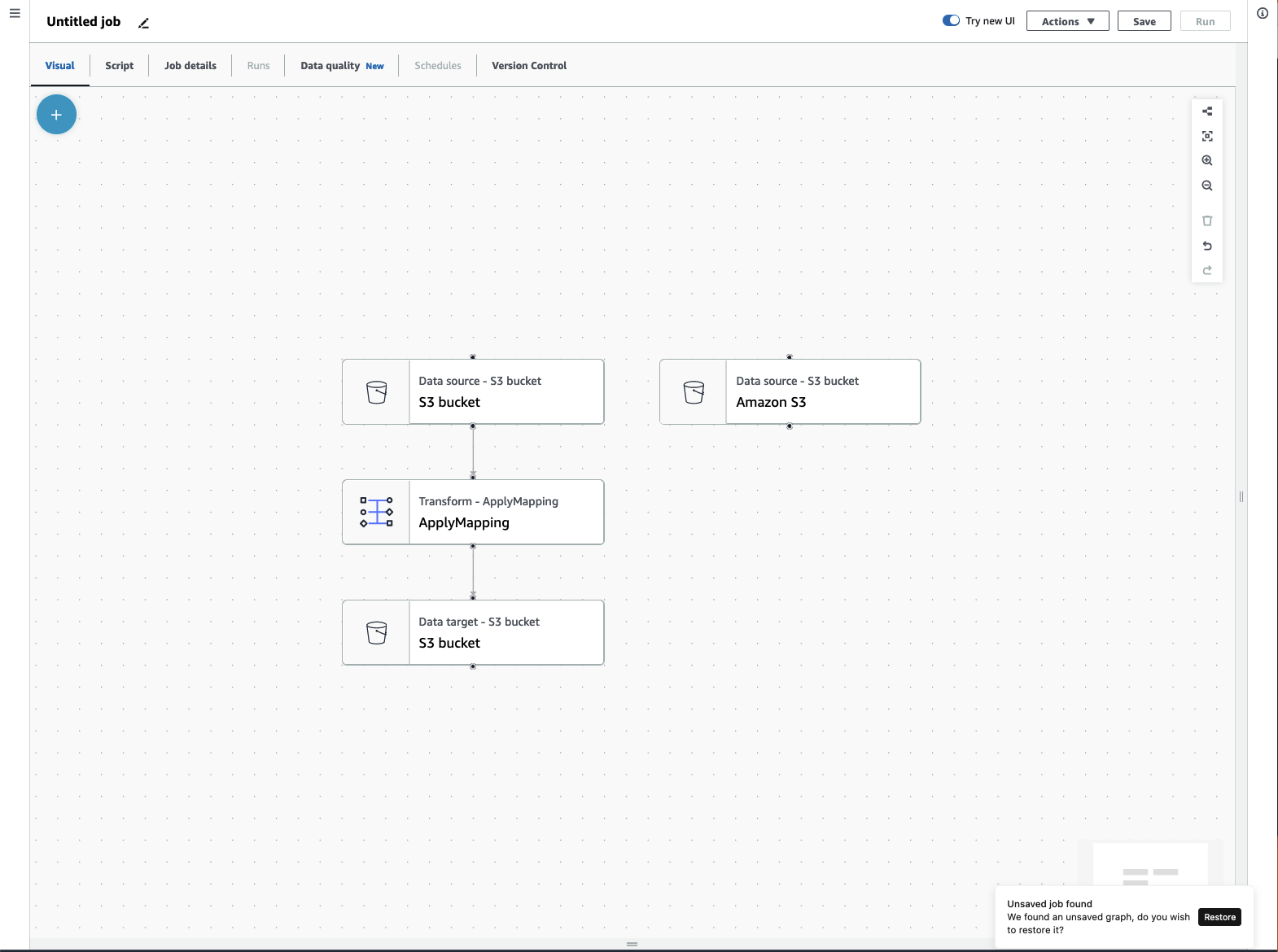
ETL 작업 메뉴
캔버스 상단의 메뉴 옵션을 통해 작업에 대한 다양한 보기 및 구성 세부 정보에 액세스할 수 있습니다.
-
시각적 - 시각적 작업 편집기 캔버스입니다. 여기서 노드를 추가하여 작업을 생성할 수 있습니다.
-
스크립트 - ETL 작업의 스크립트 표현입니다. AWS Glue는 작업의 시각적 표현을 기반으로 스크립트를 생성합니다. 스크립트를 편집하거나 다운로드할 수도 있습니다.
참고
스크립트를 편집하려는 경우 작업 작성 환경이 스크립트 전용 모드로 영구적으로 전환됩니다. 이후에는 더 이상 시각적 편집기를 사용하여 작업을 편집할 수 없습니다. 스크립트 편집을 선택하기 전에 모든 작업 소스, 변환 및 대상을 추가하고 시각적 편집기를 사용하여 필요한 모든 변경 사항을 수행해야 합니다.
-
작업 세부 정보 - 작업 세부 정보 탭에서는 작업 속성을 설정하여 작업을 구성할 수 있습니다. 여기에는 기본 속성(예: 작업 이름 및 설명, IAM 역할, 작업 유형, AWS Glue 버전, 언어, 작업자 유형, 작업자 유형, 작업자 수, 작업 북마크, Flex 실행, 사용 중지 횟수, 작업 제한 시간 초과)과 함께, 연결, 라이브러리, 작업 파라미터, 태그와 같은 고급 속성도 있습니다.
-
실행 - 작업을 실행한 후 이 탭에 액세스하여 이전 작업 실행을 볼 수 있습니다.
-
데이터 품질 - 데이터 품질에서는 데이터 자산의 품질을 평가하고 모니터링합니다. 이 탭에서 데이터 품질을 사용하는 방법에 대해 자세히 알아보고 작업에 데이터 품질 변환을 추가할 수 있습니다.
-
일정 - 예약한 작업이 이 탭에 표시됩니다. 이 작업에 연결된 일정이 없는 경우 이 탭에는 액세스할 수 없습니다.
-
버전 제어 - 작업을 Git 리포지토리로 구성하여 작업에서 Git를 사용할 수 있습니다.
시각적 ETL 패널
캔버스에서 작업하는 경우 노드를 구성하거나 데이터를 미리 보고 출력 스키마를 보는 데 도움이 되는 여러 패널을 사용할 수 있습니다.
-
속성 - 캔버스에서 노드를 선택하면 속성 패널이 나타납니다.
-
데이터 미리 보기 - 데이터 미리 보기 패널에서는 데이터 출력의 미리 보기를 제공하므로 작업을 실행하기 전에 결정을 내리고 출력을 살펴볼 수 있습니다.
-
출력 스키마 - 출력 스키마 탭을 사용하면 변환 노드의 스키마를 보고 편집할 수 있습니다.
패널 크기 조정
데이터 미리 보기 및 출력 스키마 탭이 포함된 하단 패널과 화면 오른쪽에 있는 속성 패널은 패널 가장자리를 클릭한 상태로 좌우 또는 위아래로 끌어 크기를 조정할 수 있습니다.
-
속성 패널 - 화면 오른쪽의 캔버스 가장자리를 클릭한 상태로 끌어 속성 패널의 크기를 조정한 후 왼쪽으로 끌어 너비를 확장합니다. 기본적으로 패널은 축소된 상태이며, 노드를 선택하면 속성 패널이 기본 크기로 열립니다.
-
데이터 미리 보기 및 출력 스키마 패널 - 화면 하단에서 캔버스 하단 가장자리를 클릭한 상태로 끌어 하단 패널의 크기를 조정한 후 위로 끌어 높이를 확장합니다. 기본적으로 패널은 축소된 상태이며, 노드를 선택하면 하단 패널이 기본 크기로 열립니다.
작업 캔버스
시각적 ETL 캔버스에서 직접 노드를 추가, 제거, 이동/재정렬할 수 있습니다. 작업 캔버스는 데이터 소스로 시작하고 데이터 대상으로 끝날 수 있는 완전한 기능을 갖춘 ETL 작업을 생성할 수 있는 작업 공간과 같습니다.
캔버스에서 노드에 대한 작업을 수행할 때 확대 및 축소, 노드 제거, 노드 간 연결 설정 또는 편집, 작업 흐름 방향 변경, 작업 실행 취소 또는 재실행 등을 도와주는 도구 모음이 있습니다.

부동 도구 모음은 캔버스의 오른쪽 상단 크기로 고정되어 있으며 다음과 같이 작업을 수행하는 여러 이미지를 포함합니다.
-
레이아웃 아이콘 - 도구 모음의 첫 번째 아이콘은 레이아웃 아이콘입니다. 기본적으로 시각적 작업의 방향은 위에서 아래 방향입니다. 노드를 왼쪽에서 오른쪽으로 가로로 정렬하여 시각적 작업의 방향을 재정렬할 수 있습니다. 레이아웃 아이콘을 다시 클릭하면 방향이 위에서 아래로 다시 바뀝니다.
-
가운데 재정렬 아이콘 - 가운데 재정렬 아이콘은 캔버스 보기를 가운데에 배치하여 변경합니다. 대규모 작업의 경우 이 아이콘을 사용하여 가운데 위치로 돌아갈 수 있습니다.
-
확대 아이콘 - 확대 아이콘은 캔버스의 노드 크기를 확대합니다.
-
축소 아이콘 - 축소 아이콘은 캔버스의 노드 크기를 축소합니다.
-
휴지통 아이콘 - 휴지통 아이콘은 시각적 작업에서 노드를 제거합니다. 먼저 노드를 선택해야 합니다.
-
실행 취소 아이콘 - 실행 취소 아이콘은 시각적 작업에서 수행한 마지막 작업을 되돌립니다.
-
다시 실행 아이콘 - 다시 실행 아이콘은 시각적 작업에서 수행한 마지막 작업을 반복합니다.
미니 맵 사용

리소스 패널
리소스 패널에는 사용자가 사용할 수 있는 모든 데이터 소스, 변환 작업 및 연결이 포함되어 있습니다. '+' 아이콘을 클릭하여 캔버스에서 리소스 패널을 엽니다. 그러면 리소스 패널이 열립니다.
리소스 패널을 닫으려면 리소스 패널의 오른쪽 상단에 있는 X를 클릭합니다. 그러면 패널을 다시 열 준비가 될 때까지 패널을 숨깁니다.
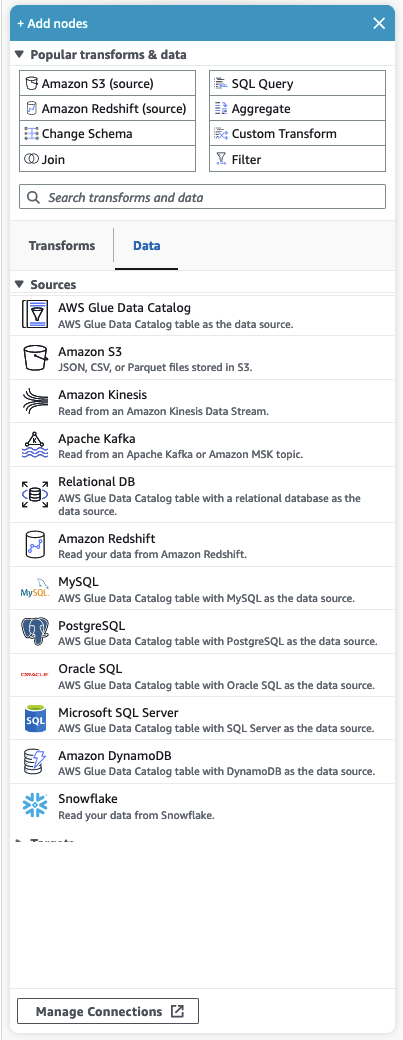
자주 사용하는 변환 및 데이터
패널 상단에는 자주 사용하는 변환 및 데이터 컬렉션이 있습니다. 이 노드는 일반적으로 AWS Glue에서 사용됩니다. 하나를 선택하여 캔버스에 추가합니다. 자주 사용하는 변환 및 데이터 제목 옆의 삼각형을 클릭하여 자주 사용하는 변환 및 데이터를 숨길 수도 있습니다.
자주 사용하는 변환 및 데이터 섹션 아래에서 변환 및 데이터 소스 노드를 검색할 수 있습니다. 내용을 입력하면 결과가 표시됩니다. 검색 쿼리를 길게 입력할수록 결과 목록이 작아집니다. 검색 결과는 노드 이름 및/또는 설명으로 채워집니다. 노드를 선택하여 캔버스에 추가합니다.
변환 및 데이터
노드를 변환 및 데이터로 구성하는 두 개의 탭이 있습니다.
변환 - 변환 탭을 선택하면 사용 가능한 모든 변환을 선택할 수 있습니다. 변환을 선택하여 캔버스에 추가합니다. 변환 목록 하단에서 변환 추가를 선택할 수도 있습니다. 그러면 사용자 지정 시각적 변환 생성에 관한 설명서의 새 페이지가 열립니다. 단계를 따라 직접 변환을 생성할 수 있습니다. 그러면 변환이 사용 가능한 변환 목록에 표시됩니다.
데이터 - 데이터 탭에는 소스 및 대상의 모든 노드가 포함되어 있습니다. 소스 또는 대상 제목 옆의 삼각형을 클릭하여 소스 및 대상을 숨길 수 있습니다. 삼각형을 다시 클릭하면 숨긴 소스 및 대상을 다시 표시할 수 있습니다. 소스 또는 대상 노드를 선택하여 캔버스에 추가합니다. 연결 관리를 선택하여 새 연결을 추가할 수도 있습니다. 그러면 콘솔에서 커넥터 페이지가 열립니다.
