이 섹션에서는 데이터 품질 대시보드와 이 대시보드에서 제공하는 다양한 기능을 살펴보겠습니다.
높은 수준의 데이터 품질 지표와 추세를 시각화하고 이해합니다.
작업이 성공하면 데이터 품질 탭을 선택하여 데이터 품질 점수와 이상을 확인하세요.
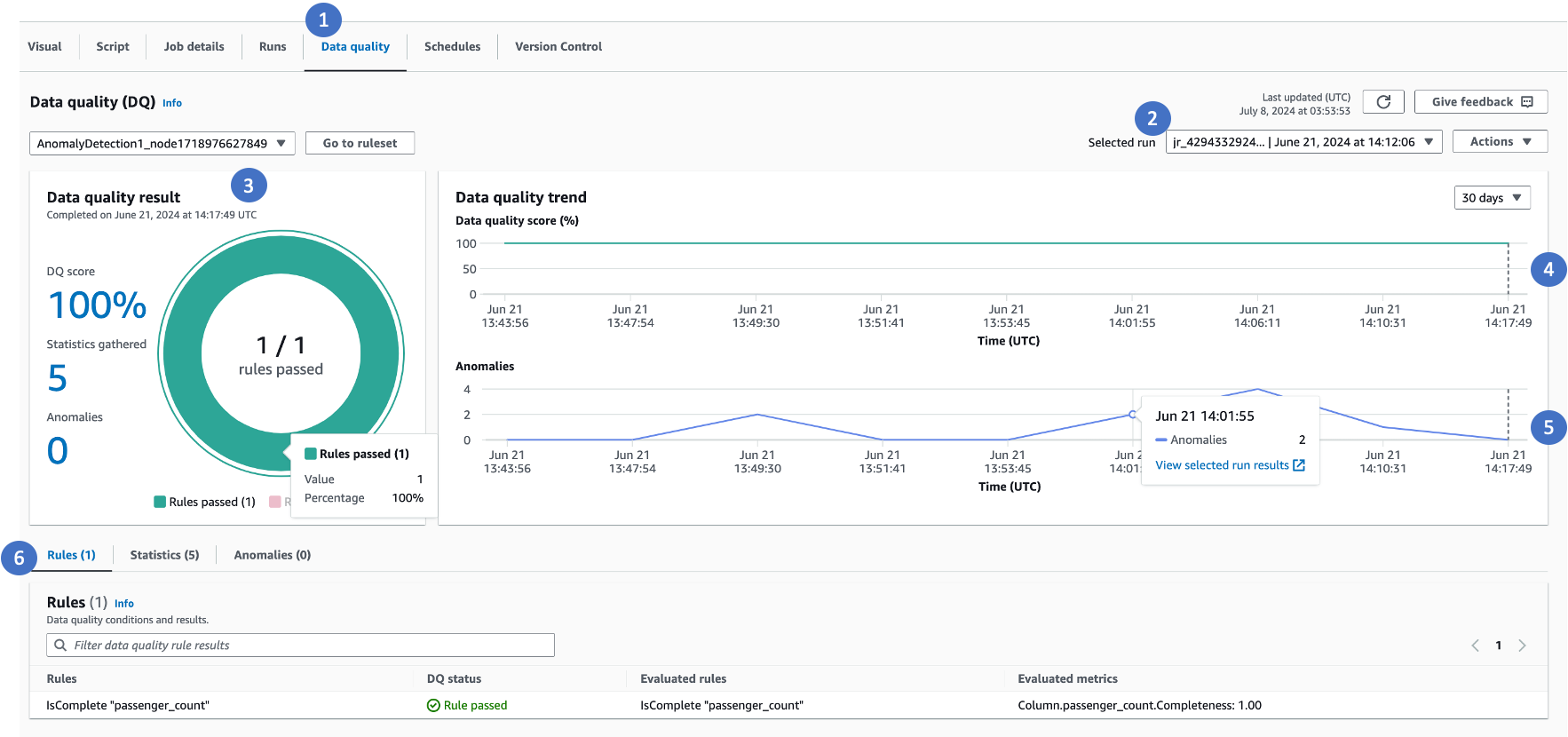
데이터 품질 탭의 다음 구성 요소에서는 유용한 정보를 확인할 수 있습니다.
-
데이터 품질 지표를 보려면 데이터 품질 탭을 선택합니다.
-
데이터 품질 점수를 보려면 특정 작업 실행 ID를 선택합니다.
-
이 창에는 세 가지 중요한 정보가 표시됩니다. 각각을 선택하여 특정 테이블로 이동하면 이상, 데이터 통계 또는 규칙을 볼 수 있습니다.
-
규칙 구성 시 데이터 품질 점수
-
규칙 및 분석기에서 수집한 통계 수
-
탐지된 총 이상 수
-
-
이 추세 차트는 시간 경과에 따른 데이터 품질 추세를 보여줍니다. 추세를 마우스로 가리키면 데이터 품질 점수가 하락한 특정 시점으로 이동할 수 있습니다.
-
시간 경과에 따른 이상 추세는 시간 경과에 따라 탐지된 이상의 수를 보여줍니다.
-
탭:
-
규칙 탭은 모든 규칙 및 상태 목록을 보여주는 기본 탭입니다. 평가된 규칙은 동적 규칙의 경우 규칙을 평가한 실제 결과 값을 보는 데 유용합니다.
-
통계 탭에는 모든 통계가 나열되므로 시간 경과에 따른 지표와 추세를 볼 수 있습니다.
-
이상 탭에는 탐지된 이상 목록이 표시됩니다.
-
이상 보기 및 이상 탐지 알고리즘 훈련
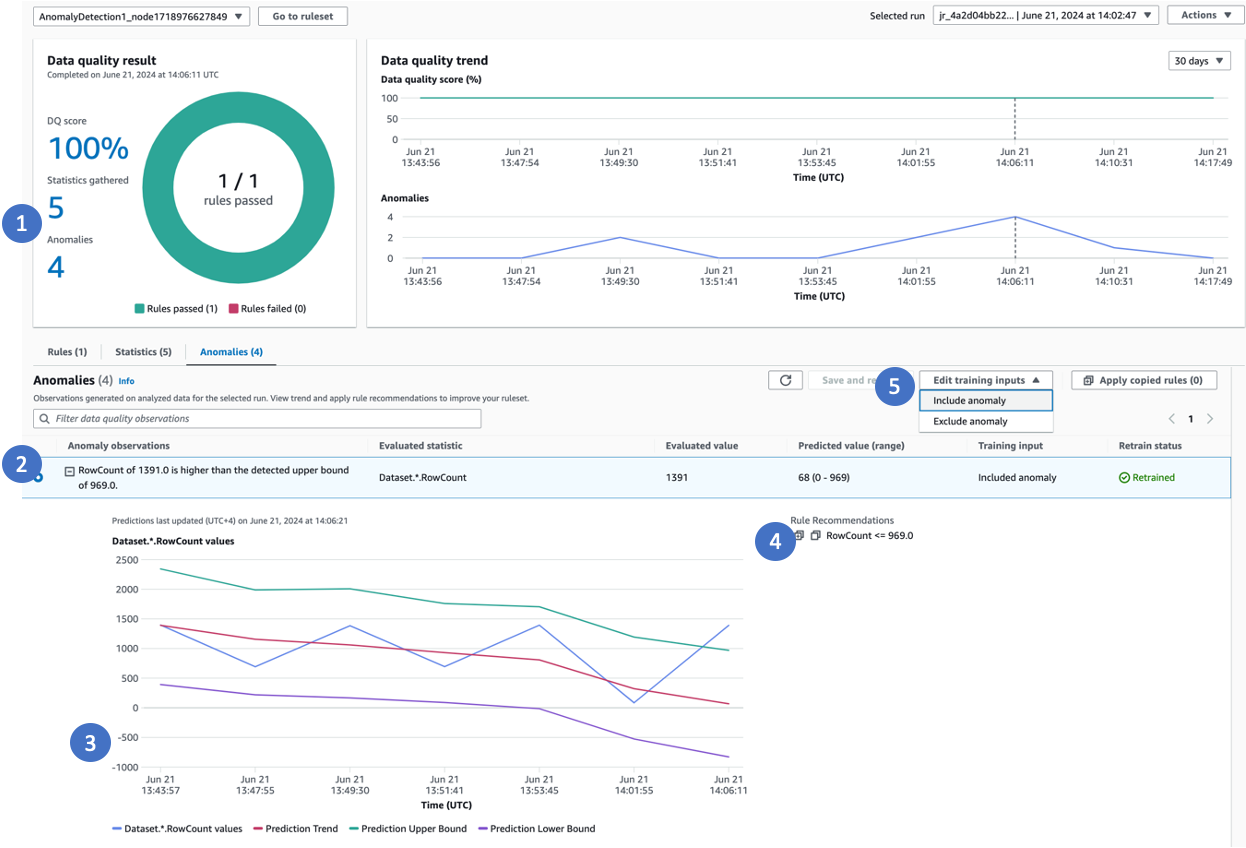
위의 이미지에 대한 콜아웃:
-
이상이 탐지되면 이상을 클릭하거나 이상 탭을 선택합니다.
-
AWS Glue Data Quality가 이상, 실제 값, 예측 범위에 대한 자세한 설명을 제공합니다.
-
AWS Glue Data Quality이 추세선을 보여줍니다. 여기에는 실제 값, 실제 값을 기반으로 도출된 추세(빨간색 선), 상한 및 하한이 있습니다.
-
AWS Glue Data Quality가 미래의 패턴을 캡처하는 데 사용할 수 있는 데이터 품질 규칙을 추천합니다. 권장되는 모든 규칙을 복사하고 데이터 품질 노드에 적용하여 이러한 패턴을 효과적으로 캡처할 수 있습니다.
-
기계 학습(ML) 모델에 입력을 제공하여 이상 값을 제외함으로써 향후 실행에서 이상을 정확하게 탐지하도록 할 수 있습니다. 이상을 명시적으로 제외하지 않으면 AWS Glue Data Quality가 자동으로 향후 예측 시에 이를 모델의 일부로 간주합니다. 입력한 모델 입력은 최신 실행에만 반영된다는 점에 유의해야 합니다. 예를 들어 이전 실행으로 돌아가서 몇 번의 실행에서 이상 포인트를 제외한 경우, 최근 실행에서 모델 입력을 확인하고 업데이트하지 않는 한 모델에 해당 변경 사항이 반영되지 않습니다. 가장 최근 실행에서 필요한 조정을 할 때까지 모델은 이전에 제공된 입력을 계속 사용합니다. 이상 값 제외를 적극적으로 관리하면 특정 데이터 패턴 및 요구 사항의 이상을 구성하는 요소에 대한 ML 모델의 이해도를 높여, 시간이 지남에 따라 이상을 더 정확하게 탐지하도록 할 수 있습니다.
시간 경과에 따른 데이터 통계 보기 및 훈련 입력 제공
데이터 통계 또는 데이터 프로필을 보고 시간 경과에 따라 어떻게 변화하는지 확인해야 할 경우도 있습니다. 이렇게 하려면 통계를 선택하거나 통계 탭을 엽니다. 그러면 AWS Glue Data Quality에서 수집한 최신 데이터 통계를 볼 수 있습니다.
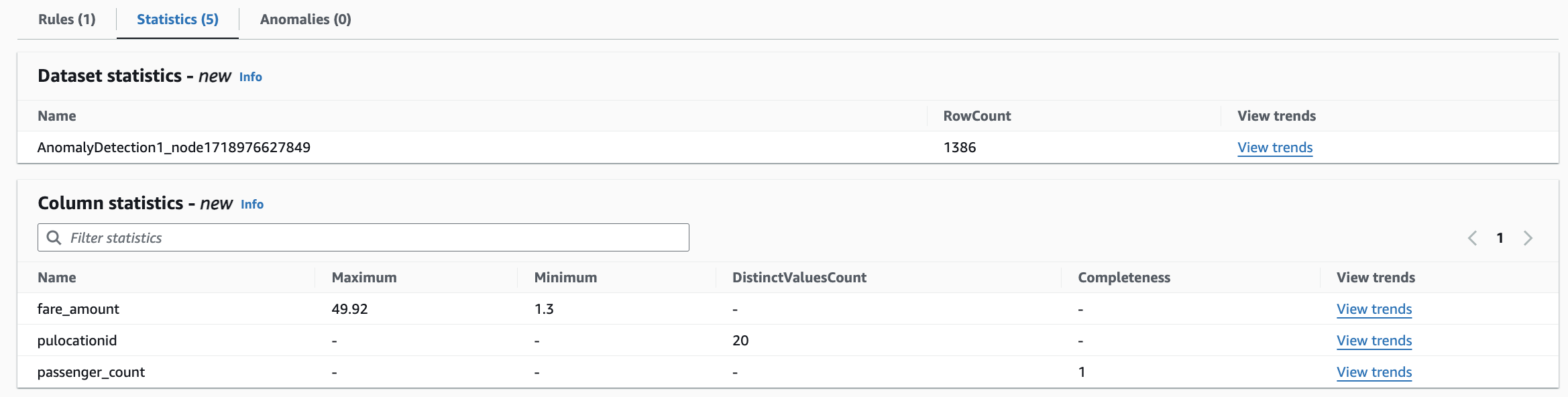
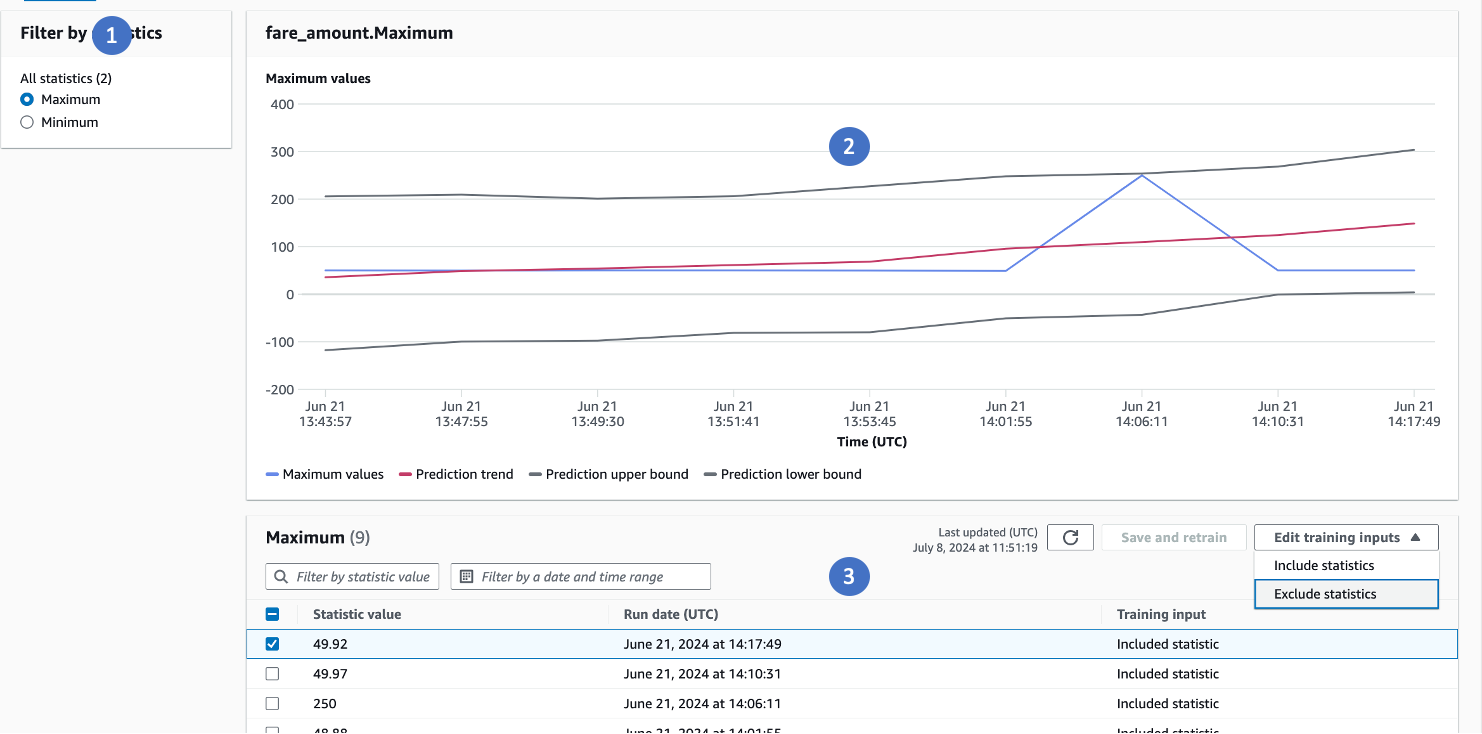
추세 보기를 클릭하면 시간 경과에 따른 각 통계의 변화를 확인할 수 있습니다.
-
특정 열의 통계를 선택할 수 있습니다.
-
추세가 어떻게 변화하는지 확인할 수 있습니다.
-
이상 값을 선택하고 제외하거나 포함하도록 선택할 수 있습니다. 이 피드백을 제공하면 알고리즘이 식별된 이상 데이터 포인트를 제외하거나 포함시키고 모델을 재훈련합니다. 사용자가 제공한 피드백을 통해 어떤 값을 이상으로 간주해야 하는지 아닌지를 모델이 학습하므로, 이 재훈련 프로세스를 거치면서 이상을 정확하게 탐지할 수 있게 됩니다.
이 피드백 루프를 통해 특정 데이터 패턴 및 비즈니스 요구 사항에 맞는 이상을 구성하는 요소에 대한 알고리즘의 이해도를 높일 수 있습니다. 이상으로 표시해서는 안 되는 값을 제외하거나 누락된 값을 포함함으로써 재훈련된 모델은 예상 데이터 포인트와 실제 이상 데이터 포인트를 더 잘 구분하게 됩니다.
