셔플링은 데이터가 파티션 간에 재배열될 때마다 Spark 작업에서 중요한 단계입니다. 이는 join,
groupByKey, reduceByKey, repartition 등의 광범위한 변환이 처리를 완료하기 위해 다른 파티션의 정보를 필요로 하기 때문에 필요합니다. Spark는 각 파티션에서 필요한 데이터를 수집하여 새 파티션으로 결합합니다. 셔플 중에 데이터가 디스크에 기록되고 네트워크를 통해 전송됩니다. 결과적으로 셔플 작업은 로컬 디스크 용량에 바인딩됩니다. Spark는 실행기에 디스크 공간이 충분하지 않고 복구가 없을 때 No space left on device 또는
MetadataFetchFailedException 오류를 발생시킵니다.
참고
Amazon S3의 AWS Glue Spark 셔플 플러그인은 AWS Glue ETL 작업에서만 지원됩니다.
Solution
AWS Glue에서는 이제 Amazon S3를 사용하여 Spark 셔플 데이터를 저장할 수 있습니다. Amazon S3는 업계 최고의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다. 이 솔루션은 Spark 작업에 대한 컴퓨팅 및 스토리지를 분해하고 완전한 탄력성과 저비용 셔플 스토리지를 제공하여 가장 셔플 집약적인 워크로드를 안정적으로 실행할 수 있도록 합니다.
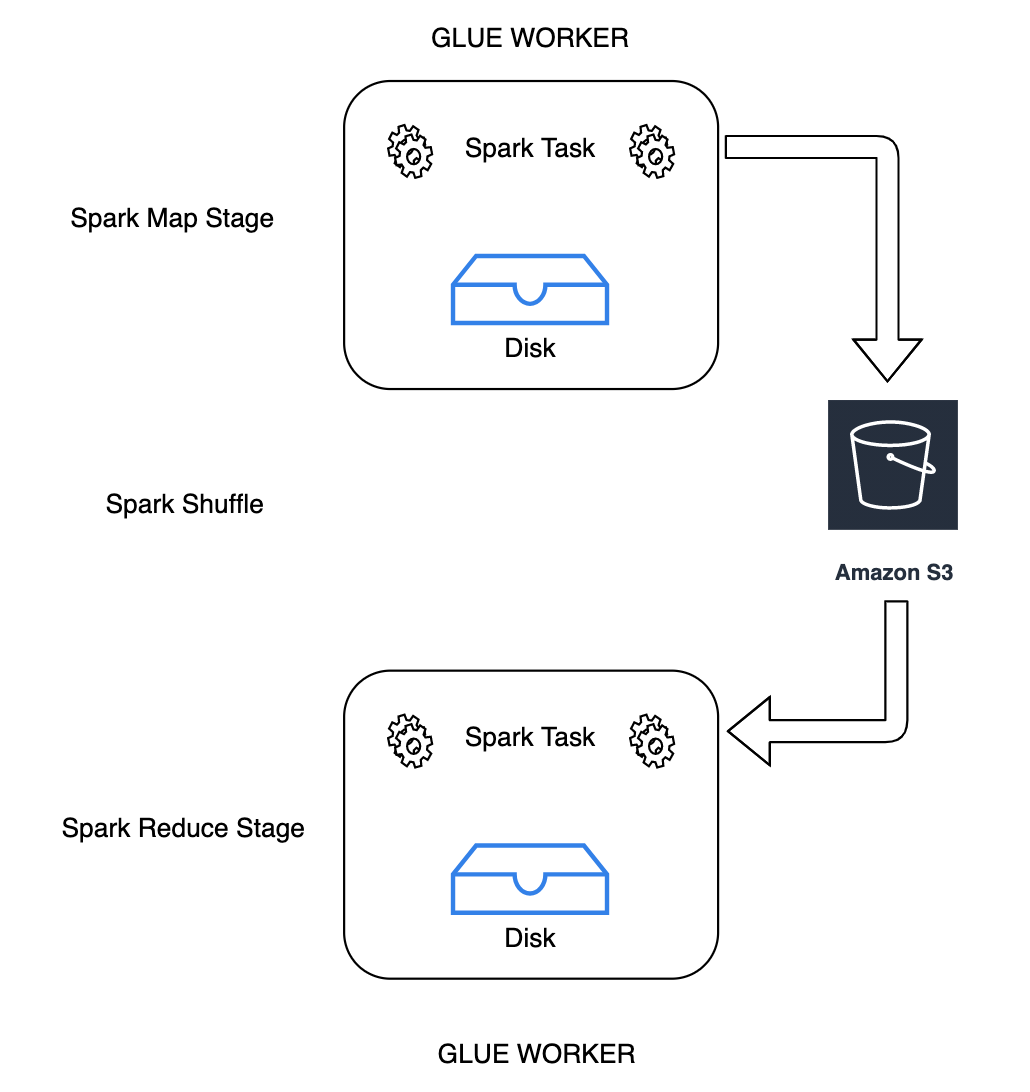
Amazon S3를 사용하기 위한 새로운 Apache Spark용 클라우드 셔플 스토리지 플러그인을 소개합니다. 대규모 셔플 작업을 위한 로컬 디스크 용량에 의해 제한되는 것으로 알려진 경우 Amazon S3 셔플링을 켜서 AWS Glue 작업을 실패 없이 안정적으로 실행할 수 있습니다. 경우에 따라 Amazon S3에 기록된 작은 파티션이나 셔플 파일이 많은 경우 Amazon S3로의 셔플링은 로컬 디스크(또는 EBS)보다 약간 느립니다.
클라우드 셔플 스토리지 플러그인 사용을 위한 필수 조건
클라우드 셔플 스토리지 플러그인을 AWS Glue ETL 작업에서 사용하려면 다음이 필요합니다.
-
중간 셔플 및 유출된 데이터를 저장할, 작업 실행과 동일한 리전에 위치한 Amazon S3 버킷. 셔플 스토리지의 Amazon S3 접두사는 다음 예제와 같이
--conf spark.shuffle.glue.s3ShuffleBucket=s3://으로 지정될 수 있습니다.shuffle-bucket/prefix/--conf spark.shuffle.glue.s3ShuffleBucket=s3://glue-shuffle-123456789-us-east-1/glue-shuffle-data/ -
셔플 관리자는 작업이 완료된 후 파일을 정리하지 않으므로 접두사(예:
glue-shuffle-data)에서 Amazon S3 스토리지 수명 주기 정책을 설정합니다. 중간 셔플 및 유출된 데이터는 작업 완료 후 삭제해야 합니다. 사용자는 접두사에 간단한 수명 주기 정책을 설정할 수 있습니다. Amazon S3 수명 주기 정책 설정 지침은 Amazon Simple Storage Service Console 사용 설명서의 버킷에서 수명 주기 구성 설정을 참조하세요.
AWS 콘솔에서 AWS Glue Spark 셔플 관리자 사용
작업을 구성할 때 AWS Glue 콘솔 또는 AWS Glue Studio를 사용하여 AWS Glue Spark 셔플 관리자를 설정하려면 --write-shuffle-files-to-s3 작업 파라미터를 선택하여 작업에 대해 Amazon S3 셔플을 설정합니다.
AWS Glue Spark 셔플 플러그인 사용
다음 작업 파라미터는 AWS Glue 셔플 매니저를 설정하고 조정합니다. 이러한 파라미터는 플래그이므로 제공된 값은 고려되지 않습니다.
-
--write-shuffle-files-to-s3- AWS Glue Spark 셔플 관리자가 Amazon S3 버킷을 사용하여 셔플 데이터를 쓰고 읽을 수 있도록 하는 기본 플래그입니다. 플래그가 지정되지 않은 경우 셔플 관리자가 사용되지 않습니다. -
--write-shuffle-spills-to-s3- (AWS Glue 버전 2.0에서만 지원됨). 유출 파일을 Amazon S3 버킷으로 오프로드하도록 허용하는 선택적 플래그로, Spark 작업에 복원력을 추가로 제공합니다. 이는 많은 데이터를 디스크로 유출하는 대규모 워크로드에만 필요합니다. 플래그를 지정하지 않으면 중간 유출 파일이 작성되지 않습니다. -
--conf spark.shuffle.glue.s3ShuffleBucket=s3://<shuffle-bucket>- 셔플 파일을 작성하는 Amazon S3 버킷을 지정하는 또 다른 선택적 플래그입니다. 기본값은--TempDir/shuffle-data입니다. AWS Glue 3.0 이상에서는--conf spark.shuffle.glue.s3ShuffleBucket=s3://에서와 같이 쉼표 구분자를 사용해 버킷을 지정함으로써 여러 버킷에 셔플 파일을 쓸 수 있도록 지원합니다. 버킷을 여러 개 사용하면 성능이 향상됩니다.shuffle-bucket-1/prefix,s3://shuffle-bucket-2/prefix/
셔플 데이터의 유휴 암호화를 활성화하려면 보안 구성 설정을 제공해야 합니다. 보안 구성에 대한 자세한 내용은 AWS Glue에서 암호화 설정 섹션을 참조하세요. AWS Glue는 Spark에서 제공하는 다른 모든 셔플 관련 구성을 지원합니다.
클라우드 셔플 스토리지 플러그인을 위한 소프트웨어 바이너리
또한 Apache 2.0 라이선스에 따라 Apache Spark용 클라우드 셔플 스토리지 플러그인의 소프트웨어 바이너리를 다운로드하여 Spark 환경에서 실행할 수 있습니다. 새 플러그인은 Amazon S3에 대한 기본 지원과 함께 제공되며 Google Cloud Storage 및 Microsoft Azure Blob Storage
참고 및 제한 사항
다음은 AWS Glue 셔플 관리자에 대한 참고 또는 제한 사항입니다.
-
AWS Glue 셔플 관리자는 작업이 완료된 후 Amazon S3 버킷에 저장된 (임시) 셔플 데이터 파일을 자동으로 삭제하지 않습니다. 데이터를 보호하려면 클라우드 셔플 스토리지 플러그인을 활성화하기 전에 클라우드 셔플 스토리지 플러그인 사용을 위한 필수 조건의 지침을 따릅니다.
-
데이터가 왜곡된 경우 이 기능을 사용할 수 있습니다.
