세분화된 액세스 제어를 위해 AWS Lake Formation과 함께 AWS Glue 사용
개요
AWS Glue 버전 5.0 이상을 사용하면 AWS Lake Formation을 사용하여 S3에서 지원하는 Data Catalog 테이블에 세분화된 액세스 제어를 적용할 수 있습니다. 이 기능을 사용하면 Apache Spark용 AWS Glue 작업 내에서 read 쿼리에 대한 테이블, 행, 열 및 셀 수준 액세스 제어를 구성할 수 있습니다. Lake Formation 및 이를 AWS Glue와 함께 사용하는 방법에 대해 자세히 알아보려면 다음 섹션을 참조하세요.
Glue 4.0 이하에서 지원되는 AWS Lake Formation 권한을 가진 GlueContext 기반 테이블 수준 액세스 제어는 Glue 5.0에서 지원되지 않습니다. Glue 5.0에서는 새로운 Spark 네이티브 세분화된 액세스 제어(FGAC)를 사용합니다. 다음의 세부 정보를 적어 둡니다.
row/column/cell 액세스 제어를 위한 세분화된 액세스 제어(FGAC)가 필요한 경우 Glue 4.0의
GlueContext/Glue DynamicFrame 및 이전 버전에서 Glue 5.0의 Spark 데이터프레임으로 마이그레이션해야 합니다. 예제는 GlueContext/Glue DynamicFrame에서 Spark DataFrame으로 마이그레이션 단원을 참조하십시오.전체 테이블 액세스(FTA) 제어가 필요한 경우 AWS Glue 5.0에서 DynamicFrames와 함께 FTA를 활용할 수 있습니다. 또한 AWS Lake Formation 테이블을 사용하여 탄력적 분산형 데이터세트(RDD), 사용자 지정 라이브러리 및 사용자 정의 함수(UDF)와 같은 추가 기능을 위해 네이티브 Spark 접근 방식으로 마이그레이션할 수 있습니다. 예제는 AWS Glue 4.0에서 AWS Glue 5.0으로 마이그레이션을 참조하세요.
FGAC가 필요하지 않은 경우, Spark 데이터프레임으로의 마이그레이션이 필요하지 않으며 작업 북마크, 푸시다운 조건자와 같은
GlueContext기능은 계속 작동합니다.FGAC를 사용하는 작업에는 사용자 드라이버 1, 시스템 드라이버 1, 시스템 실행기 1, 대기 사용자 실행기 1, 이렇게 작업자가 최소 4명 필요합니다.
AWS Glue를 AWS Lake Formation과 함께 사용하면 추가 요금이 발생합니다.
AWS Glue에서 AWS Lake Formation을 사용하는 방식
AWS Glue를 Lake Formation과 함께 사용하면 AWS Glue에서 작업을 실행하는 경우 Lake Formation 권한 제어를 적용하기 위해 각 Spark 작업에 권한 계층을 적용할 수 있습니다. AWS Glue는 Spark 리소스 프로파일
다음 개요에서는 AWS Glue가 Lake Formation 보안 정책에 따라 보호되는 데이터에 액세스하는 방법을 설명합니다.
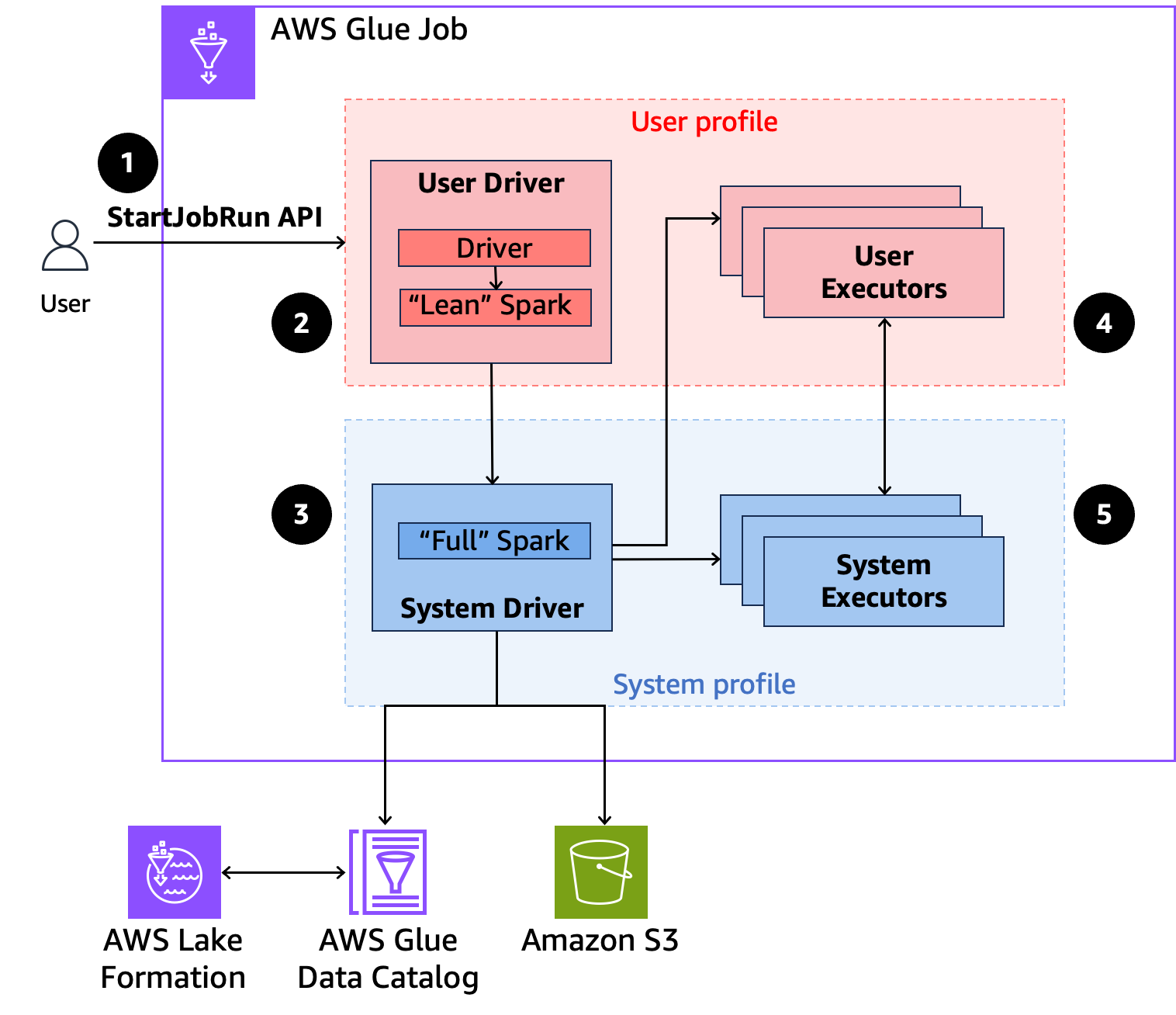
-
사용자가 AWS Lake Formation이 활성화된 AWS Glue 작업에서
StartJobRunAPI를 호출합니다. -
AWS Glue는 사용자 드라이버로 작업을 전송하고 사용자 프로파일에서 작업을 실행합니다. 사용자 드라이버는 태스크를 시작하고, 실행기를 요청하며, S3 또는 Glue Catalog에 액세스할 수 없는 린 버전의 Spark를 실행합니다. 작업 계획을 빌드합니다.
-
AWS Glue는 시스템 드라이버라는 두 번째 드라이버를 설정하고 시스템 프로파일(권한 있는 자격 증명 포함)에서 실행합니다. AWS Glue는 통신을 위해 두 드라이버 사이에서 암호화된 TLS 채널을 설정합니다. 사용자 드라이버는 채널을 사용하여 작업 계획을 시스템 드라이버로 전송합니다. 시스템 드라이버는 사용자가 제출한 코드를 실행하지 않습니다. 전체 Spark를 실행하고 S3 및 데이터 액세스를 위해 Data Catalog와 통신합니다. 실행기를 요청하고 작업 계획을 일련의 실행 단계로 컴파일합니다.
-
그런 다음, AWS Glue는 사용자 드라이버 또는 시스템 드라이버를 사용하여 실행기에서 단계를 실행합니다. 모든 단계의 사용자 코드는 사용자 프로파일 실행기에서만 실행됩니다.
-
AWS Lake Formation에서 보호하는 Data Catalog 테이블에서 데이터를 읽는 단계 또는 보안 필터를 적용하는 단계는 시스템 실행기로 위임됩니다.
최소 작업자 요구 사항
AWS Glue의 Lake Formation 지원 작업에는 사용자 드라이버 1, 시스템 드라이버 1, 시스템 실행기 1, 대기 사용자 실행기 1, 이렇게 작업자가 최소 4명 필요합니다. 이는 표준 AWS Glue 작업에 필요한 최소 작업자 2명보다 많습니다.
AWS Glue의 Lake Formation 지원 작업에는 시스템 프로필과 사용자 프로필에 대해 하나씩, 두 개의 Spark 드라이버가 사용됩니다. 마찬가지로 실행기도 두 프로필로 나뉨:
시스템 실행기: Lake Formation 데이터 필터가 적용되는 작업을 처리합니다.
사용자 실행기: 필요에 따라 시스템 드라이버가 요청합니다.
Spark 작업은 본질적으로 지연되므로 AWS Glue는 사용자 실행기에 대해 두 드라이버를 뺀 후 총 작업자의 10%(최소 1개)를 예약합니다.
모든 Lake Formation 지원 작업은 오토 스케일링이 활성화되어 있습니다. 즉, 사용자 실행기는 필요한 경우에만 시작됩니다.
예제 구성은 고려 사항 및 제한 사항을 참조하세요.
작업 런타임 역할 IAM 권한
Lake Formation 권한은 AWS Glue 데이터 카탈로그 리소스, Amazon S3 위치 및 해당 위치의 기본 데이터에 대한 액세스를 제어합니다. IAM 권한은 Lake Formation 및 AWS Glue API와 리소스에 대한 액세스를 제어합니다. Data Catalog의 테이블에 액세스할 수 있는 Lake Formation 권한이 있더라도(SELECT) glue:Get* API 작업에 IAM 권한이 없으면 작업이 실패합니다.
다음은 S3의 스크립트에 액세스할 수 있는 IAM 권한을 제공하는 방법, S3에 로그 업로드, AWS Glue API 권한 및 Lake Formation에 액세스할 수 있는 권한에 대한 정책 예제입니다.
작업 런타임 역할에 대한 Lake Formation 권한 설정
먼저 Lake Formation에 Hive 테이블의 위치를 등록합니다. 그런 다음, 원하는 테이블에서 작업 런타임 역할에 대한 권한을 생성합니다. Lake Formation에 대한 자세한 내용은 AWS Lake Formation 개발자 안내서의 What is AWS Lake Formation?을 참조하세요.
Lake Formation 권한을 설정한 후 AWS Glue에서 Spark 작업을 제출할 수 있습니다.
작업 실행 제출
Lake Formation 권한 부여 설정을 완료한 후 AWS Glue에서 Spark 작업을 제출할 수 있습니다. Iceberg 작업을 실행하려면 다음과 같은 Spark 구성을 제공해야 합니다. Glue 작업 파라미터를 통해 구성하려면 다음 파라미터를 입력합니다.
키:
--conf값:
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
대화형 세션 사용
AWS Lake Formation 권한 부여 설정을 완료한 후 AWS Glue에서 대화형 세션을 사용할 수 있습니다. 코드를 실행하기 전에 %%configure 매직을 통해 다음 Spark 구성을 제공해야 합니다.
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
Glue AWS 5.0 노트북용 FGAC 또는 대화형 세션
AWS Glue에서 FGAC(세분화된 액세스 제어)를 활성화하려면 첫 번째 셀을 생성하기 전에 Lake Formation에 필요한 Spark conf를 %%configure 매직의 일부로 지정해야 합니다.
나중에 SparkSession.builder().conf("").get() 또는 SparkSession.builder().conf("").create() 직접 호출을 사용하여 지정하는 것으로는 충분하지 않습니다. 이는 AWS Glue 4.0 동작에서 변경된 것입니다.
오픈 테이블 형식 지원
AWS Glue 버전 5.0 이상에는 Lake Formation을 기반으로 하는 세분화된 액세스 제어에 대한 지원이 포함되어 있습니다. AWS Glue는 Hive 및 Iceberg 테이블 유형을 지원합니다. 다음 표에서는 지원되는 모든 옵션을 설명합니다.
| 운영 | Hive | Iceberg |
|---|---|---|
| DDL 명령 | IAM 역할 권한만 있음 | IAM 역할 권한만 있음 |
| 증분 쿼리 | 해당 사항 없음 | 완전 지원 |
| 시간 이동 쿼리 | 이 테이블 형식에 해당되지 않음 | 완전 지원 |
| 메타데이터 테이블 | 이 테이블 형식에 해당되지 않음 | 지원되지만 특정 테이블은 숨겨집니다. 자세한 내용은 고려 사항 및 제한 사항을 참조하세요. |
DML INSERT |
IAM 권한만 있음 | IAM 권한만 있음 |
| DML UPDATE | 이 테이블 형식에 해당되지 않음 | IAM 권한만 있음 |
DML DELETE |
이 테이블 형식에 해당되지 않음 | IAM 권한만 있음 |
| 읽기 작업 | 완전 지원 | 완전 지원 |
| 저장 프로시저 | 해당 사항 없음 | register_table 및 migrate를 제외하고 지원됩니다. 자세한 내용은 고려 사항 및 제한 사항을 참조하세요. |
