本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Neptune 入門
Amazon Neptune 是一種全受管圖形資料庫服務,其可擴展以處理數十億種關係,並讓您以毫秒的延遲查詢它們,而這類容量的成本很低。
如果您正在尋找有關 Neptune 的更多詳細資訊,請參閱 Amazon Neptune 功能概觀。
如果您已經知道圖形,請跳到 快速開始使用 CloudShell或 搭配圖形筆記本使用 Neptune。或者,如果您想要立即建立 Neptune 資料庫,請參閱 使用 建立 Amazon Neptune 叢集 AWS CloudFormation。
否則,您可能想要在開始前進一步了解圖形資料庫。
圖形資料庫金鑰概念
圖形資料庫會進行最佳化,以儲存和查詢資料項目之間的關係。
它們會將資料項目本身儲存為圖形的頂點,並將它們之間的關係儲存為邊緣。每個邊緣都有一個類型,且會從一個頂點 (起點) 導向到另一個頂點 (終點)。關係可以稱為述詞以及邊緣,而頂點有時也稱為節點。在所謂的屬性圖中,頂點和邊緣也都可以具有與它們相關聯的額外屬性。
以下是代表社交網路中朋友和興趣的小圖:
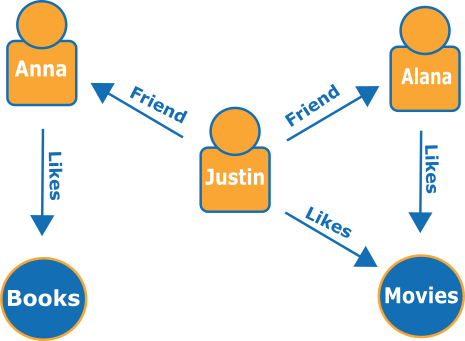
邊緣顯示為具名箭頭,而頂點代表特定人物及其連結的興趣。
僅需簡單地周遊此圖形,即可了解 Justin 朋友的喜好。
為什麼要使用圖形資料庫?
每當實體間的連線或關係位於您嘗試要建立模型的資料核心時,圖形資料庫自然會成為您的心中首選。
首先,很容易將資料互連建成圖形模型,然後撰寫複雜的查詢,從圖形中擷取真實世界的資訊。
使用關聯式資料庫建置對等應用程式,需要您建立大量具有多個外部索引鍵的資料表,然後撰寫巢狀 SQL 查詢和複雜聯結。從編碼的角度來看,這種方法不僅迅速變得效率低下,而且隨著資料量的增加,其效能也會迅速下降。
相比之下,像 Neptune 這樣的圖形資料庫可以查詢數十億個頂點之間的關係,而不會陷入困境。
可以使用圖形資料庫做什麼?
圖形可以透過許多方式根據行為、所有權、家世、購買選擇、個人關係、家庭關係等表示真實世界實體的相互關係。
以下是一些使用圖形資料庫的最常見領域:
-
知識圖 – 知識圖可讓您組織和查詢各種有關聯的資訊來回答一般問題。使用知識圖,您可以將主題資訊新增至產品目錄,並為 Wikidata
中包含的各種資訊建立模型。 若要進一步了解知識圖的運作方式以及在何處使用它們,請參閱 AWS上的知識圖
。 -
身分圖 – 在圖形資料庫中,您可以儲存資訊類別 (例如客戶興趣、朋友和購買歷史記錄) 之間的關係,然後查詢該資料以做出個人化且相關的建議。
例如,您可以使用圖形資料庫,根據關注相同運動且擁有相似購買歷史記錄的其他人所購買的產品,向使用者推薦產品。或者,您可以找出有共同朋友但還不認識彼此的使用者,藉此推薦朋友人選。
這種圖形被稱為身分圖,廣泛用於將與使用者的互動個人化。若要深入了解,請參閱 AWS上的身分圖
。若要開始建置自己的身分圖,您可以從使用 Amazon Neptune 的身分圖 範例開始。 -
欺詐圖 – 這是圖形資料庫的常見用途。它們可以協助您追蹤信用卡購物和購買地點,以偵測異常使用情況,或偵測購買者是否正在嘗試使用與已知欺詐案件中相同的電子郵件地址和信用卡。它們可讓您檢查是否有多個人與個人電子郵件地址相關聯,或是否在不同實體位置有多個人共用相同 IP 地址。
請考慮下列圖形。其會顯示三個使用者之間的關係,以及其身分的相關資訊。每位使用者都有一個地址、銀行帳戶與身分證號碼。不過,我們可以看見 Matt 和 Justin 共用相同的身分證號碼,這是非常不尋常的狀況,表示他們其中一個可能進行詐騙。對欺詐圖的查詢可以揭示此類關聯,以便可以對其進行審查。
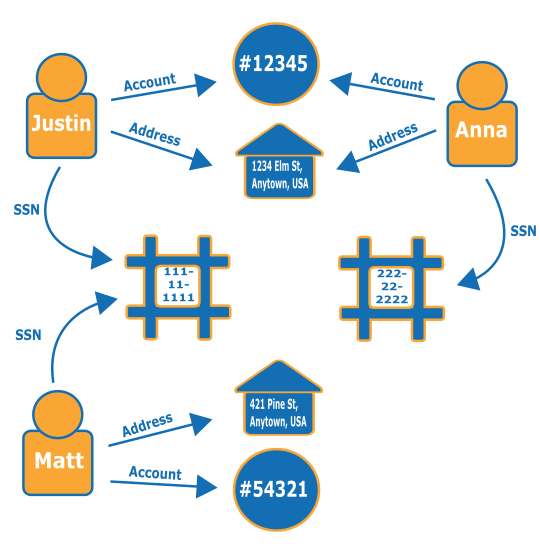
若要進一步了解欺詐圖以及在何處使用它們,請參閱 AWS上的欺詐圖
。 -
社交網路 – 使用圖形資料庫的其中一個最常見領域,就是社交網路應用程式。
舉例來說,假設您想要在網站中建立社群摘要。您可以在後端輕鬆地使用圖形資料庫,將反映最新更新的結果提供給使用者,而這些更新來自家人、朋友、他們「喜歡」其更新的人,以及住在他們附近的人。
行車路線 – 鑒於目前交通情況和典型的交通模式,圖形可以協助您找到從起點到目的地的最佳路線。
物流 – 圖形可以協助識別最有效的方式來使用可用的運輸和配銷資源,以滿足客戶的需求。
診斷 – 圖形可以代表複雜的診斷樹,您可以查詢這些診斷樹,來識別觀察到的問題和失敗來源。
科學研究 – 使用圖形資料庫,您可以建置應用程式,使用靜態加密來儲存和導覽科學資料,甚至是敏感的醫療資訊。例如,您可以儲存疾病和基因互動的模型。您可以搜尋蛋白質化學反應的圖形模式,尋找與疾病相關聯的其他基因。您也能夠建立化合物圖形模型,並在分子結構中查詢模式。您可以將來自不同系統中醫療記錄的患者資料建立關聯。您可以依主題整理研究期刊,快速尋找相關資訊。
法規 – 您可以將複雜的法規需求儲存為圖形,並查詢它們,以偵測這些需求可能適用於您日常業務營運的情況。
-
網路拓撲與事件 – 圖形資料庫可以協助您管理和保護 IT 網路。將網路拓撲儲存為圖形時,您也可以在網路上儲存和處理許多不同種類的事件。您可以回答問題,例如有多少主機正在執行特定的應用程式。您可以查詢可能顯示特定主機已遭惡意程式入侵的模式,並查詢連線資料,而這些資料可協助追蹤程式至下載該程式的原始主機。
如何查詢圖形?
Neptune 支援三種特殊用途的查詢語言,這些語言是專為查詢不同種類的圖形資料而設計。您可以使用下列語言來新增、修改、刪除和查詢 Neptune 圖形資料庫中的資料:
-
Gremlin 是一種適用於屬性圖的圖形周遊語言。Grimlin 中的查詢是由離散步驟組成的周遊,每個步驟都沿著一個邊緣到一個節點。如需詳細資訊,請參閱 Apache TinkerPop
的 Gremlin 文件。 Gremlin 的 Neptune 實作與其他實作有一些不同,尤其是使用 Gremlin-Groovy 時 (以序列化的文字傳送的 Gremlin 查詢)。如需詳細資訊,請參閱Amazon Neptune 中的 Gremlin 標準合規。
-
openCypher – OpenCypher 是屬性圖的宣告式查詢語言,最初由 Neo4j 開發,然後在 2015 年成為開放原始碼,並在 Apache 2 開放原始碼授權下投入 OpenCypher
專案。如需語言規格,請參閱 Cypher 查詢語言參考 (第 9 版) ,以及如需額外資訊,請參閱 Cypher 樣式指南 。 -
SPARQL 是 RDF
資料的宣告式查詢語言,以全球資訊網協會 (W3C) 制定的標準圖形模式配對為基礎,於 SPARQL 1.1 概觀 和 SPARQL 1.1 查詢語言 規格中描述。如需 SPARQL 的 Neptune 實作的特定詳細資訊,請參閱 Amazon Neptune 中的 SPARQL 標準合規。
比對 Gremlin 和 SPARQL 查詢的範例
根據以下的人物 (節點) 與其關係 (邊緣) 圖形,您可以找出特定對象的「朋友的朋友」,例如,Howard 朋友的朋友。
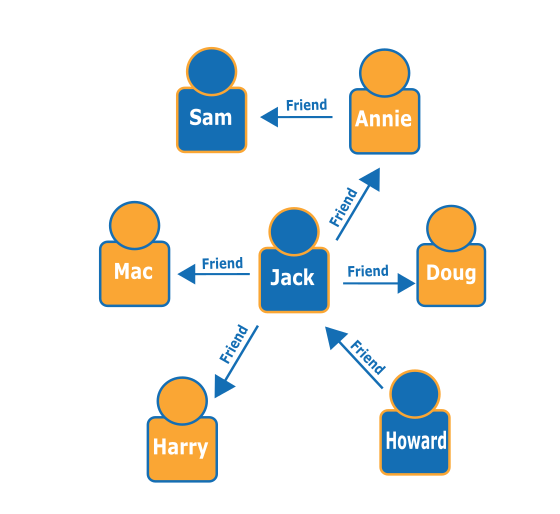
您可以從圖中發現 Howard 有一位朋友 Jack,而 Jack 則有四位朋友:Annie、Harry、Doug 和 Mac。此處採用的簡單範例是搭配簡易圖形使用,但您可以依複雜度、資料集大小與結果大小來擴大這些類型的查詢規模。
以下是進行 Gremlin 周遊查詢後,系統搜尋 Howard 朋友的朋友所傳回的姓名結果:
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
以下是進行 SPARQL 查詢後,系統搜尋 Howard 朋友的朋友所傳回的姓名結果:
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
注意
任何資源描述架構 (RDF) 三元組的每個部分都具備與其相關的 URI。在上述範例中,刻意精簡了 URI 字首。
參加使用 Amazon Neptune 的線上課程
如果您喜歡透過影片學習, 會在 AWS 線上AWS 技術講座中提供線上
使用 Amazon Neptune 的圖形資料庫簡介、深入探討和示範
深入挖掘圖形參考架構
當您考慮圖形資料庫可以為您解決哪些問題,以及如何處理這些問題時,最好的起點之一就是 Neptune 圖形參考架構 GitHub 專案
您可以在那裡找到圖形工作負載類型的詳細描述,以及三個章節,協助您設計有效的圖形資料庫:
資料模型和查詢語言
– 本節會為您逐步解說 Gremlin 和 SPARQL 之間的差異,以及如何在它們之間進行選擇。 圖形資料模型
– 這是如何做出圖形資料建模決策的全面討論,包括使用 Gremlin 進行屬性圖建模的詳細逐步解說,以及使用 SPARQL 進行 RDF 建模。 將其他資料模型轉換為圖形模型
– 在這裡您可以了解如何將關係資料模型轉換成圖形模型。
還有三個章節為您逐步解說使用 Neptune 的特定步驟:
從 Neptune VPC 外部的用戶端連線至 Amazon Neptune
– 本節顯示從資料庫叢集所在的 VPC 外部連線到 Neptune 的幾個選項。 從 AWS Lambda 函數存取 Amazon Neptune
– 在這裡,您將了解如何從 Lambda 函數可靠地連線至 Neptune。 從 Amazon Kinesis Data Streams 寫入 Amazon Neptune
– 本節可協助您使用 Neptune 處理高寫入輸送量案例。
