DynamoDB의 구체화된 집계 쿼리에 글로벌 보조 인덱스 사용
빠르게 변화하는 데이터에 대해 근실시간 집계와 주요 지표를 유지하는 것이 빠르게 결정을 내려야 하는 비즈니스에 점점 더 중요해지고 있습니다. 예를 들어 음악 라이브러리에서 가장 많이 다운로드된 노래를 거의 실시간으로 표시하거나 전자 상거래 플랫폼에서 범주별로 유행하는 제품을 표시해야 할 수 있습니다.
DynamoDB는 기본적으로 항목 간에 SUM 또는 COUNT 같은 집계 작업을 지원하지 않으므로 읽기 시간에 이러한 값을 계산하려면 많은 수의 항목을 스캔해야 하므로 느리고 비용이 많이 들 수 있습니다. 대신 데이터가 변경될 때 집계를 사전 계산하고 결과를 테이블에 일반 항목으로 저장할 수 있습니다. 이 패턴을 구체화된 집계라고 합니다.
예제 시나리오 및 액세스 패턴
다음 요구 사항이 있는 음악 라이브러리 애플리케이션을 고려해 보겠습니다.
애플리케이션은 개별 노래 다운로드를 대용량(초당 수천 개)으로 기록합니다.
사용자는 한 달 동안 가장 많이 다운로드된 노래를 한 자릿수 밀리초의 지연 시간으로 확인해야 합니다.
또한 애플리케이션은 ‘이번 달 상위 10개 노래’ 및 ‘해당 월에 다운로드된 모든 노래’와 같은 쿼리를 지원해야 합니다.
이러한 규모에서 모든 다운로드 레코드를 스캔하여 읽기 시 다운로드 수를 계산하는 것은 비용이 많이 들 수 있습니다. 대신 다운로드가 발생할 때마다 업데이트되는 실행 횟수를 유지하고 효율적인 쿼리를 지원하는 방식으로 저장할 수 있습니다.
사전 계산 집계를 사용하는 이유
집계를 계산하는 방법에는 여러 가지가 있습니다. 다음 표에서는 일반적인 대안을 비교하고 DynamoDB의 구체화된 집계가 이러한 유형의 사용 사례에 가장 적합한 이유를 설명합니다.
| 접근 방식 | 단점 | 사용해야 하는 경우 |
|---|---|---|
| 읽기 시 스캔 및 계산 | 모든 쿼리에 대한 모든 다운로드 레코드를 읽어야 합니다. 지연 시간은 데이터 볼륨과 함께 증가하며 상당한 읽기 용량을 소비합니다. | 지연 시간이 문제가 되지 않는 매우 작은 데이터세트에만 적합합니다. |
| 외부 집계 저장소(예: Amazon ElastiCache) | 별도의 서비스를 관리해야 하므로 운영 복잡성이 증가합니다. DynamoDB와 캐시 간의 동기화 로직이 필요합니다. | 단순 수를 초과하는 밀리초 미만의 읽기 또는 복잡한 집계 로직이 필요한 경우. |
| 쓰기 시 애플리케이션 수준 집계 | 집계 로직을 쓰기 경로에 결합합니다. 다운로드를 기록한 후 개수를 업데이트하기 전에 애플리케이션이 실패하면 집계가 일관되지 않게 됩니다. | 동기식이며 강력히 일관된 집계가 필요한 경우 추가 쓰기 지연 시간을 허용할 수 있습니다. |
| 스트림 및 Lambda를 사용한 구체화된 집계 | 쓰기 경로에서 집계를 분리합니다. 집계는 최종적으로 일관됩니다(일반적으로 몇 초 뒤처짐). Lambda 간접 호출 비용을 추가합니다. | 읽기 지연 시간이 짧고 최종 일관성을 허용할 수 있는 실시간에 가까운 집계가 필요한 경우. 이는 이 페이지에서 설명하는 접근 방식입니다. |
구체화된 집계 접근 방식은 쓰기 경로를 단순하게 유지하고(다운로드만 기록하고), 집계를 비동기 프로세스로 오프로드하고, 결과를 DynamoDB에 저장하여 한 자릿수 밀리초 지연 시간으로 쿼리할 수 있습니다.
테이블 설계
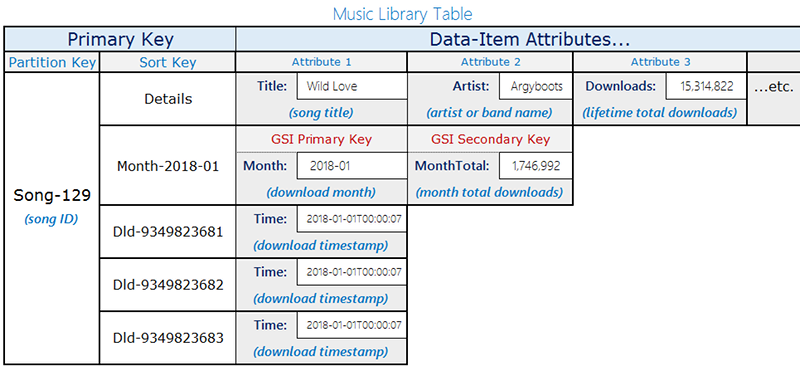
이 설계는 동일한 파티션 키(songID)를 공유하지만 서로 다른 정렬 키 패턴을 사용하여 두 항목 유형을 구분하는 두 개의 항목 유형이 있는 단일 테이블을 사용합니다.
레코드 다운로드 - 개별 다운로드 이벤트입니다. 정렬 키는
DownloadID(각 다운로드의 고유 식별자)입니다.월별 집계 항목 - 매월 노래당 사전 계산된 다운로드 수입니다. 정렬 키는
YYYY-MM형식의 월입니다(예:2018-01). 이러한 항목에는 실행 합계가 있는DownloadCount속성도 포함됩니다.
월별 집계 항목에만 Month 속성이 포함됩니다. 이러한 구분은 나중에 설명하는 희소 GSI 설계에 중요합니다.
다음 다이어그램은 두 항목 유형이 모두 있는 테이블 레이아웃을 보여줍니다.
| 항목 유형 | 파티션 키(songID) | Sort key | 추가 속성 |
|---|---|---|---|
| 레코드 다운로드 | song1 |
download-abc123 |
UserID, Timestamp |
| 월별 집계 | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
스트림 및 AWS Lambda를 사용한 집계 파이프라인
집계 파이프라인은 다음과 같이 작동합니다.
노래가 다운로드되면 애플리케이션은
Partition-Key=songID및Sort-Key=DownloadID를 사용하여 테이블에 새 항목을 작성합니다.DynamoDB Streams는 이 쓰기를 스트림 레코드로 캡처합니다.
스트림에 연결된 Lambda 함수는 새 레코드를 처리합니다.
songID및 이번 달을 식별한 다음DownloadCount속성을 증가시켜 해당 월별 집계 항목을 업데이트합니다.그런 다음 업데이트된 집계 항목을 희소 GSI를 통해 쿼리할 수 있습니다.
Lambda 함수는 ADD 표현식과 함께 UpdateItem 직접 호출을 사용하여 다운로드 수를 원자적으로 증가시킵니다. 이렇게 하면 read-modify-write 레이스 조건이 방지됩니다.
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
참고
업데이트된 집계 값을 작성한 후 Lambda 실행이 실패하면 스트림 레코드가 재시도될 수 있습니다. ADD 작업은 실행할 때마다 개수를 증가시키기 때문에 재시도는 동일한 다운로드에 대해 개수를 두 번 이상 증가시켜 대략적인 값을 남깁니다. 대부분의 분석 및 리더보드 사용 사례에서는 이 작은 오류 마진이 허용됩니다. 정확한 개수가 필요한 경우, 예를 들어 특정 DownloadID가 이미 처리되었는지 확인하는 조건 표현식을 사용하여 멱등성 로직을 추가하는 것이 좋습니다.
희소 GSI 설계
집계된 결과를 효율적으로 쿼리하려면 다음 키 스키마를 사용하여 글로벌 보조 인덱스를 생성합니다.
GSI 파티션 키:
Month(문자열)GSI 정렬 키:
DownloadCount(숫자)
월별 집계 항목에만 Month 속성이 포함되어 있기 때문에 이 GSI는 희소합니다. 개별 다운로드 레코드에는 이 속성이 없으므로 인덱스에서 자동으로 제외됩니다. 즉, GSI에는 테이블의 전체 항목 중 작은 부분인 사전 계산된 집계 항목만 포함됩니다.
희소 GSI는 두 가지 주요 이점을 제공합니다.
비용 절감 - 집계 항목만 인덱스에 복제되므로 테이블의 모든 항목이 포함된 인덱스에 비해 쓰기 용량과 스토리지를 훨씬 적게 소비합니다.
더 빠른 쿼리 - 인덱스에는 쿼리에 필요한 데이터만 포함되어 있으므로 읽기가 효율적이고 한 자릿수 밀리초 지연 시간으로 결과를 반환합니다.
희소 인덱스 작동 방식에 대한 자세한 내용은 희소 인덱스 활용 섹션을 참조하세요.
GSI 쿼리
희소 GSI를 사용하면 여러 유형의 쿼리에 효율적으로 응답할 수 있습니다.
지정된 달에 가장 많이 다운로드된 노래를 가져오려면 다음을 수행합니다.
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
ScanIndexForward를 false로 설정하면 DownloadCount가 결과를 내림차순으로 정렬하고 Limit=1이 상위 노래만 반환합니다.
지정된 달의 상위 10개 노래를 가져오려면 다음을 수행합니다.
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
지정된 달에 다운로드한 모든 노래 가져오기(다운로드 수 기준으로 정렬):
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
고려 사항
이 패턴을 구현할 때는 다음을 염두에 두세요.
최종 일관성 - 집계 값은 DynamoDB Streams 및 Lambda를 통해 비동기적으로 업데이트됩니다. 일반적으로 다운로드가 기록되는 시점과 집계가 업데이트되는 시점 사이에 몇 초의 지연이 있습니다. 즉, GSI는 실시간 데이터가 아닌 거의 실시간 데이터를 반영합니다.
Lambda 동시성 - 테이블의 쓰기 볼륨이 많은 경우 여러 Lambda 간접 호출이 동일한 집계 항목을 동시에 업데이트하려고 시도할 수 있습니다. 원자성
ADD작업은 이를 안전하게 처리하지만 Lambda 동시성 및 스로틀링 지표를 모니터링하여 함수가 스트림을 따라잡을 수 있도록 해야 합니다.GSI 쓰기 용량 - 희소 GSI에는 집계 항목만 포함되므로 기본 테이블보다 훨씬 적은 쓰기 용량이 필요합니다. 그러나 집계 업데이트 속도를 처리하기에 충분한 용량을 프로비저닝(또는 온디맨드 모드 사용)해야 합니다.
대략적인 수 - 앞서 언급했듯이 Lambda 재시도로 인해 수가 약간 과대 계산될 수 있습니다. 정확한 수가 필요한 사용 사례의 경우 Lambda 함수에서 멱등성 검사를 구현합니다.
