DynamoDB를 Amazon Managed Streaming for Apache Kafka와 통합
Amazon Managed Streaming for Apache Kafka(Amazon MSK)를 사용하면 완전관리형의 고가용성 Apache Kafka 서비스를 통해 스트리밍 데이터를 실시간으로 쉽게 수집하고 처리할 수 있습니다.
Apache Kafka
이러한 기능으로 인해 Apache Kafka는 실시간 스트리밍 데이터 파이프라인을 구축하는 데 자주 사용됩니다. 데이터 파이프라인은 한 시스템에서 다른 시스템으로 데이터를 안정적으로 처리하고 이동하며, 각기 다른 사용 사례를 지원하는 여러 데이터베이스를 쉽게 사용할 수 있도록 하여 목적별 데이터베이스 전략을 채택하는 데 중요한 역할을 할 수 있습니다.
Amazon DynamoDB는 키-값 또는 문서 데이터 모델을 사용하고 일관된 한 자릿수 밀리초 성능과 함께 무한한 확장성이 필요한 애플리케이션을 지원하기 위해 이러한 데이터 파이프라인에서 일반적인 대상으로 사용됩니다.
작동 방식
Amazon MSK와 DynamoDB 간의 통합은 Lambda 함수를 사용하여 Amazon MSK의 레코드를 사용하고 DynamoDB에 씁니다.
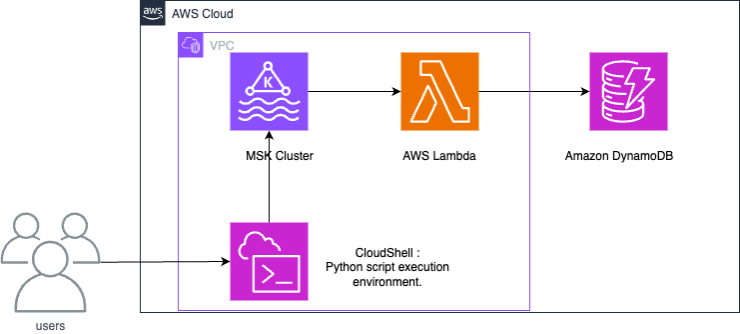
Lambda는 Amazon MSK의 새 메시지를 내부적으로 폴링한 다음 대상 Lambda 함수를 동기적으로 간접 호출합니다. Lambda 함수의 이벤트 페이로드에는 Amazon MSK의 메시지 배치가 포함되어 있습니다. Amazon MSK와 DynamoDB 간의 통합을 위해 Lambda 함수는 이러한 메시지를 DynamoDB에 씁니다.
Amazon MSK와 DynamoDB 간의 통합 설정
참고
다음 GitHub 리포지토리
아래 단계는 Amazon MSK와 Amazon DynamoDB 간의 샘플 통합을 설정하는 방법을 보여줍니다. 이 예제는 사물 인터넷(IoT) 디바이스에서 생성되어 Amazon MSK로 수집된 데이터를 나타냅니다. 데이터가 Amazon MSK에 수집되면 Apache Kafka와 호환되는 분석 서비스 또는 타사 도구와 통합할 수 있으므로 다양한 분석 사용 사례가 가능합니다. DynamoDB도 통합하면 개별 디바이스 레코드의 키 값 조회가 가능합니다.
이 예제에서는 Python 스크립트가 Amazon MSK에 IoT 센서 데이터를 쓰는 방법을 보여줍니다. 그런 다음 Lambda 함수는 파티션 키 ‘deviceid’를 사용하여 DynamoDB에 항목을 씁니다.
제공된 CloudFormation 템플릿은 Amazon S3 버킷, Amazon VPC, Amazon MSK 클러스터 및 데이터 작업 테스트를 위한 AWS CloudShell의 리소스를 만듭니다.
테스트 데이터를 만들려면 Amazon MSK 주제를 만든 다음 DynamoDB 테이블을 만듭니다. 관리 콘솔에서 Session Manager를 사용하여 CloudShell의 운영 체제에 로그인하고 Python 스크립트를 실행할 수 있습니다.
CloudFormation 템플릿을 실행한 후 다음 작업을 수행하여 이 아키텍처 구축을 완료할 수 있습니다.
-
CloudFormation 템플릿
S3bucket.yaml을 실행하여 S3 버킷을 만듭니다. 후속 스크립트 또는 작업의 경우 동일한 리전에서 실행합니다. CloudFormation 스택의 이름으로ForMSKTestS3를 입력합니다.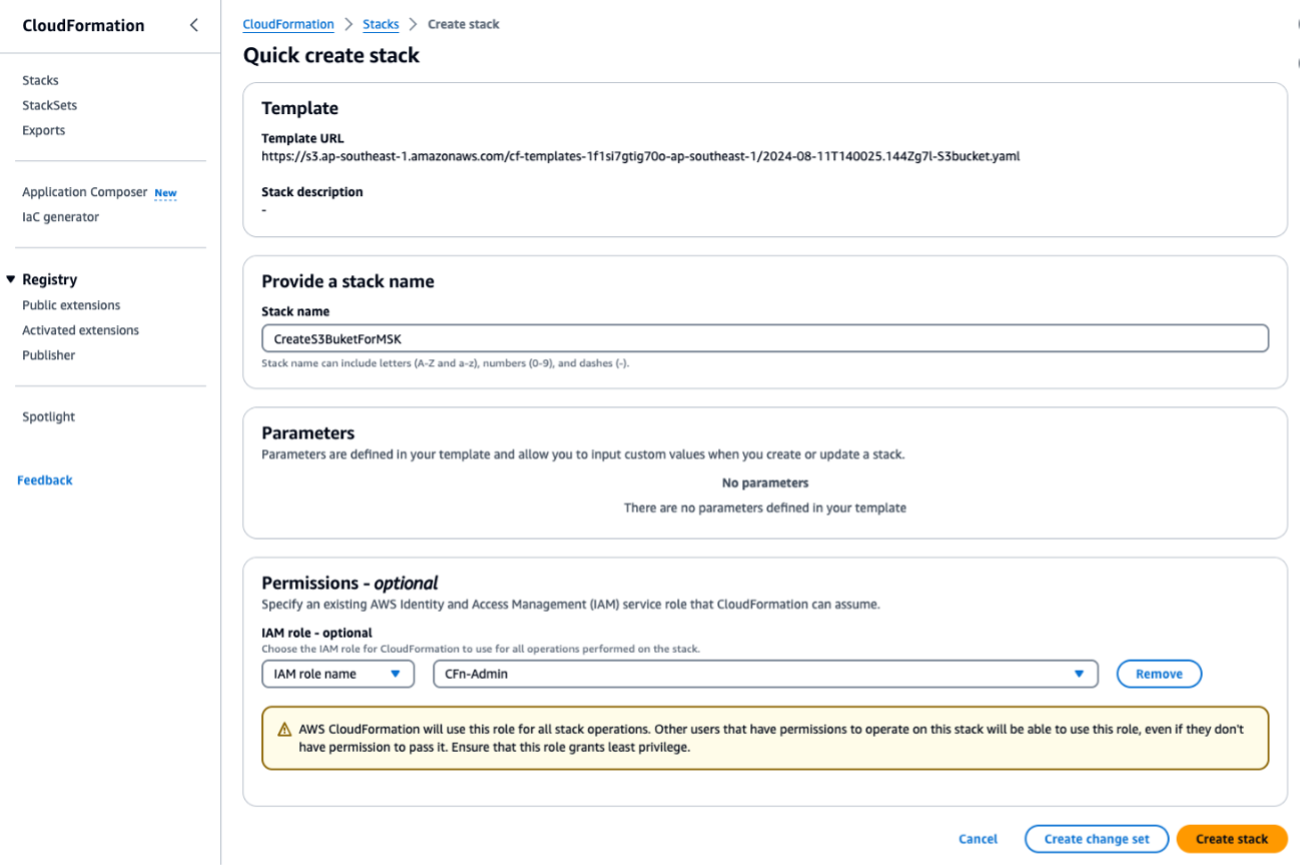
이 작업이 완료되면 출력 아래에 있는 S3 버킷 이름 출력을 기록해 둡니다. 3단계에서 이 이름이 필요합니다.

-
다운로드한 ZIP 파일
fromMSK.zip을 방금 만든 S3 버킷으로 업로드합니다.
-
CloudFormation 템플릿
VPC.yaml을 실행하여 VPC, Amazon MSK 클러스터 및 Lambda 함수를 만듭니다. S3 버킷을 요청하는 파라미터 입력 화면이 표시되면 1단계에서 생성한 S3 버킷 이름을 입력합니다. CloudFormation 스택 이름을ForMSKTestVPC로 설정합니다.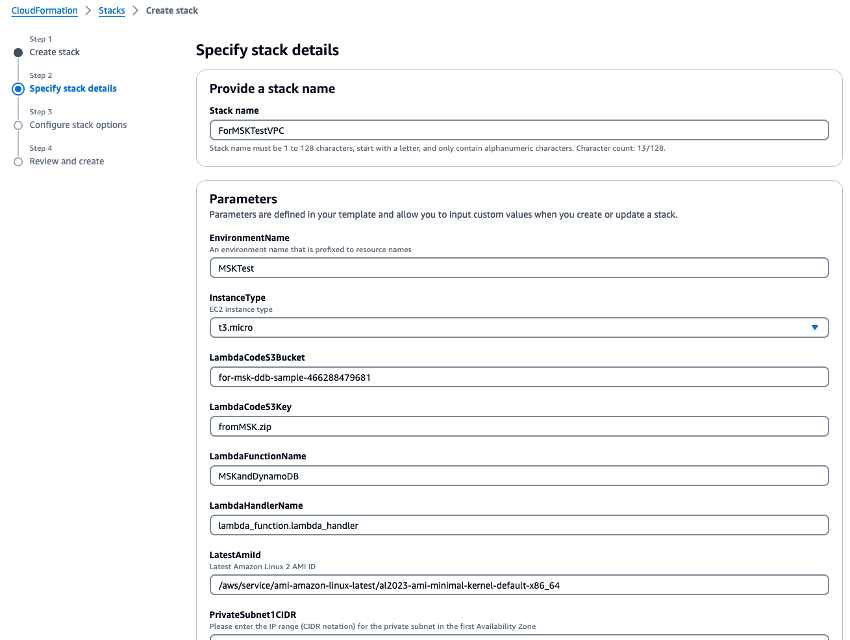
-
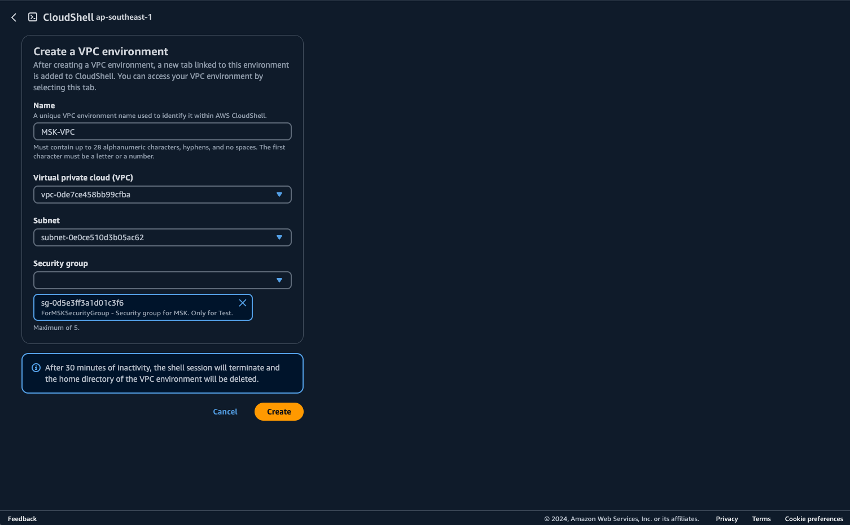
CloudShell에서 Python 스크립트를 실행하기 위한 환경을 준비합니다. AWS Management Console에서 CloudShell을 사용할 수 있습니다. CloudShell 사용에 대한 자세한 내용은 AWS CloudShell 시작하기를 참조하세요. CloudShell을 시작한 후 Amazon MSK 클러스터에 연결하기 위해 방금 만든 VPC에 속하는 CloudShell을 만듭니다. 프라이빗 서브넷에서 CloudShell을 만듭니다. 다음 필드를 입력합니다.
-
이름 - 원하는 이름으로 설정할 수 있습니다. 예를 들어, MSK-VPC가 될 수 있습니다.
-
VPC - MSKTest를 선택합니다.
-
서브넷 - MSKTest 프라이빗 서브넷(AZ1)을 선택합니다.
-
SecurityGroup - ForMSKSecurityGroup을 선택합니다.

프라이빗 서브넷에 속하는 CloudShell이 시작되면 다음 명령을 실행합니다.
pip install boto3 kafka-python aws-msk-iam-sasl-signer-python -
-
S3 버킷에서 Python 스크립트를 다운로드합니다.
aws s3 cp s3://[YOUR-BUCKET-NAME]/pythonScripts.zip ./ unzip pythonScripts.zip -
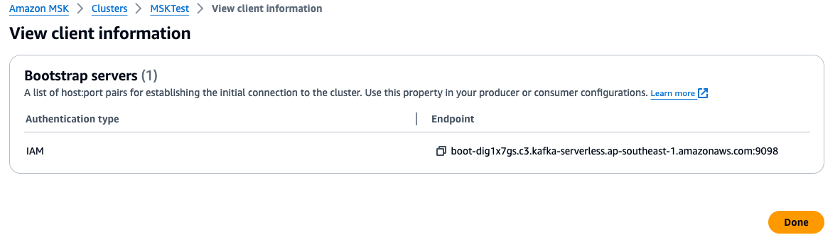
관리 콘솔을 확인하고 Python 스크립트에서 브로커 URL 및 리전 값에 대한 환경 변수를 설정합니다. 관리 콘솔에서 Amazon MSK 클러스터 브로커 엔드포인트를 확인합니다.

-
CloudShell에서 환경 변수를 설정합니다. 미국 서부(오리건)를 사용하는 경우:
export AWS_REGION="us-west-2" export MSK_BROKER="boot-YOURMSKCLUSTER.c3.kafka-serverless.ap-southeast-1.amazonaws.com:9098" -
다음 Python 스크립트를 실행합니다.
Amazon MSK 주제 만들기:
python ./createTopic.pyDynamoDB 테이블 만들기:
python ./createTable.pyAmazon MSK 주제에 테스트 데이터 쓰기:
python ./kafkaDataGen.py -
생성된 Amazon MSK, Lambda 및 DynamoDB 리소스에 대한 CloudWatch 지표를 확인하고 DynamoDB Data Explorer로
device_status테이블에 저장된 데이터를 확인하여 모든 프로세스가 올바르게 실행되었는지 확인합니다. 각 프로세스가 오류 없이 실행되는 경우 CloudShell에서 Amazon MSK로 쓰인 테스트 데이터가 DynamoDB에도 쓰였는지 확인할 수 있습니다.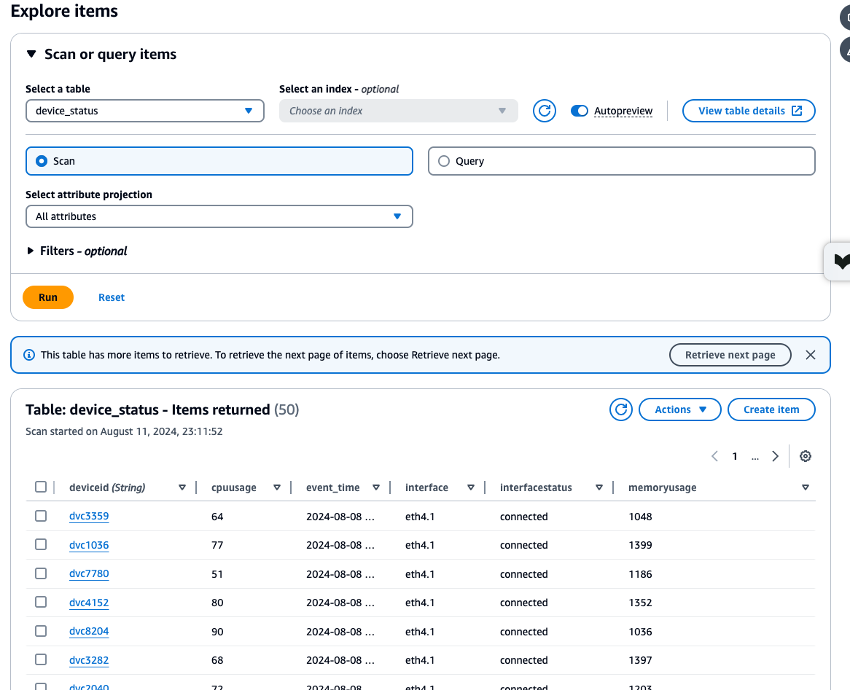
-
이 예제를 마치면 이 자습서에서 만든 리소스를 삭제합니다.
ForMSKTestS3및ForMSKTestVPC의 두 CloudFormation 스택을 삭제합니다. 스택 삭제가 성공적으로 완료되면 모든 리소스가 삭제됩니다.
다음 단계
참고
이 예제를 따르는 동안 리소스를 만든 경우 예상치 못한 요금이 발생하지 않도록 리소스를 삭제해야 합니다.
통합은 Amazon MSK와 DynamoDB를 연결하여 스트림 데이터가 OLTP 워크로드를 지원할 수 있도록 하는 아키텍처를 식별했습니다. 여기서 DynamoDB를 OpenSearch Service와 연결하여 더 복잡한 검색을 실현할 수 있습니다. 더욱 복잡한 이벤트 중심 요구 사항이 있다면 EventBridge와 통합하고, 더 높은 처리량과 짧은 지연 시간이 필요하다면 Amazon Managed Service for Apache Flink와 같은 확장을 고려하세요.
