DynamoDB의 소셜 네트워크 스키마 설계
소셜 네트워크 비즈니스 사용 사례
이 사용 사례에서는 DynamoDB를 소셜 네트워크로 사용하는 방법을 설명합니다. 소셜 네트워크는 여러 사용자가 서로 상호 작용할 수 있는 온라인 서비스입니다. 설계할 소셜 네트워크에서 사용자는 자신의 게시물, 팔로워, 팔로우하는 사람, 팔로우하는 사람이 작성한 게시물로 구성된 타임라인을 볼 수 있습니다. 이 스키마 설계의 액세스 패턴은 다음과 같습니다.
-
주어진 userID의 사용자 정보 가져오기
-
주어진 userID의 팔로워 목록 가져오기
-
주어진 userID가 팔로우하는 사용자 목록 가져오기
-
주어진 userID의 게시물 목록 가져오기
-
주어진 postID의 게시물을 좋아하는 사용자 목록 가져오기
-
주어진 postID의 좋아요 개수 가져오기
-
주어진 userID의 타임라인 가져오기
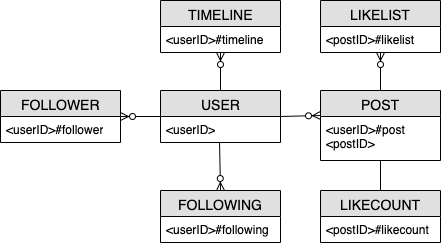
소셜 네트워크 엔터티 관계 다이어그램
다음은 소셜 네트워크 스키마 설계에 사용할 엔터티 관계 다이어그램(ERD)입니다.
소셜 네트워크 액세스 패턴
다음은 소셜 네트워크 스키마 설계 시 고려할 액세스 패턴입니다.
-
getUserInfoByUserID -
getFollowerListByUserID -
getFollowingListByUserID -
getPostListByUserID -
getUserLikesByPostID -
getLikeCountByPostID -
getTimelineByUserID
소셜 네트워크 스키마 설계 진화
DynamoDB는 NoSQL 데이터베이스이므로 여러 데이터베이스의 데이터를 결합하는 조인 작업은 수행할 수 없습니다. DynamoDB에 익숙하지 않은 고객은 그럴 필요가 없을 때 관계형 데이터베이스 관리 시스템(RDBMS) 설계 철학(예: 각 엔터티별 테이블 생성)을 DynamoDB에 적용할 수 있습니다. DynamoDB의 단일 테이블 설계의 목적은 애플리케이션의 액세스 패턴에 따라 미리 조인된 형태로 데이터를 쓴 다음 추가 계산 없이 데이터를 즉시 사용하는 것입니다. 자세한 내용은 Single-table vs. multi-table design in DynamoDB
이제 모든 액세스 패턴을 처리하도록 스키마 설계를 발전시키는 방법을 단계별로 살펴보겠습니다.
1단계: 액세스 패턴 1(getUserInfoByUserID) 처리
주어진 사용자의 정보를 가져오려면 키 조건 PK=<userID>를 사용하여 기본 테이블을 Query해야 합니다. 쿼리 작업을 사용하면 결과에 페이지를 매길 수 있으며, 이는 사용자의 팔로어가 많을 때 유용할 수 있습니다. 쿼리에 대한 자세한 내용은 DynamoDB에서 테이블 쿼리 섹션을 참조하세요.
이 예제에서는 'count'와 'info'라는 두 가지 유형의 사용자 데이터를 추적합니다. 사용자의 'count'에는 사용자의 팔로워 수, 사용자가 팔로우 중인 사용자 수, 사용자가 작성한 게시물 수가 반영됩니다. 사용자의 'info'에는 이름과 같은 개인 정보가 반영됩니다.
이 두 종류의 데이터는 아래의 두 항목으로 표현됩니다. 정렬 키(SK)에 'count'가 있는 항목은 'info'가 있는 항목보다 변경될 가능성이 높습니다. DynamoDB는 업데이트 전후에 표시되는 항목 크기를 고려하며, 사용된 프로비저닝된 처리량은 이러한 항목 크기 중 더 큰 크기를 반영합니다. 따라서 항목 속성의 하위 집합을 업데이트하더라도 UpdateItem은 프로비저닝된 처리량(이전 항목 크기와 이후 항목 크기 중 더 큰 것)을 모두 소비합니다. 한 번의 Query 작업으로 항목을 가져오고 UpdateItem을 사용하여 기존 숫자 속성에 더하거나 뺄 수 있습니다.

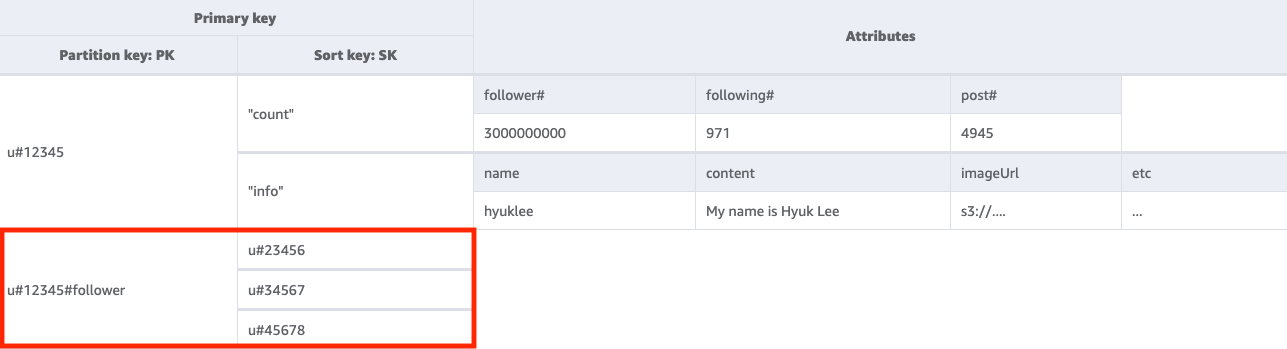
2단계: 액세스 패턴 2(getFollowerListByUserID) 처리
주어진 사용자를 팔로우하는 사용자 목록을 가져오려면 키 조건 PK=<userID>#follower를 사용하여 기본 테이블을 Query해야 합니다.
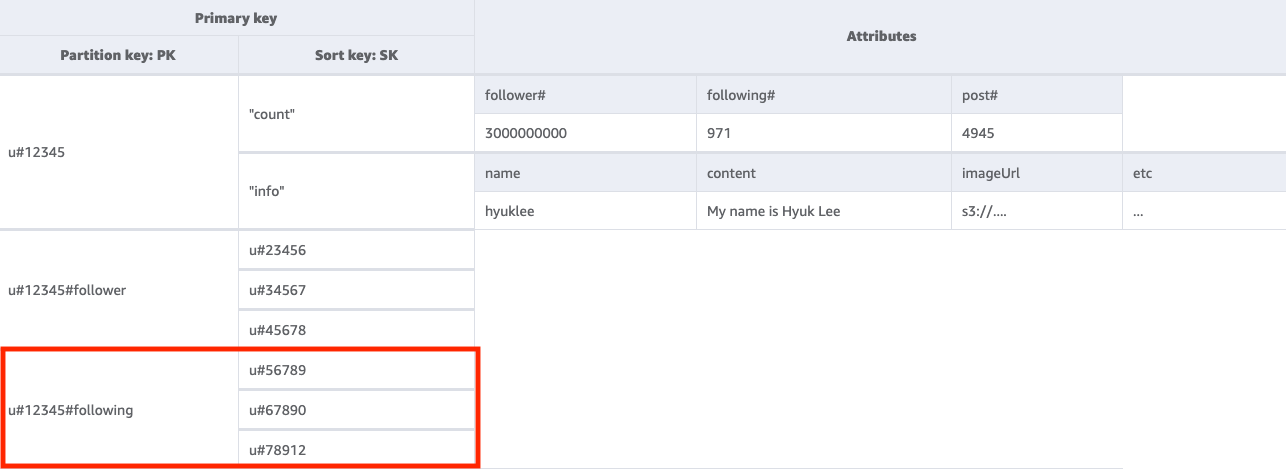
3단계: 액세스 패턴 3(getFollowingListByUserID) 처리
주어진 사용자가 팔로우하는 사용자 목록을 가져오려면 키 조건 PK=<userID>#following를 사용하여 기본 테이블을 Query해야 합니다. 그런 다음 TransactWriteItems 작업을 사용하여 여러 요청을 그룹화하고 다음을 수행할 수 있습니다.
-
사용자 A를 사용자 B의 팔로워 목록에 추가한 다음 사용자 B의 팔로워 수를 1 늘립니다.
-
사용자 B를 사용자 A의 팔로워 목록에 추가한 다음 사용자 A의 팔로워 수를 1 늘립니다.
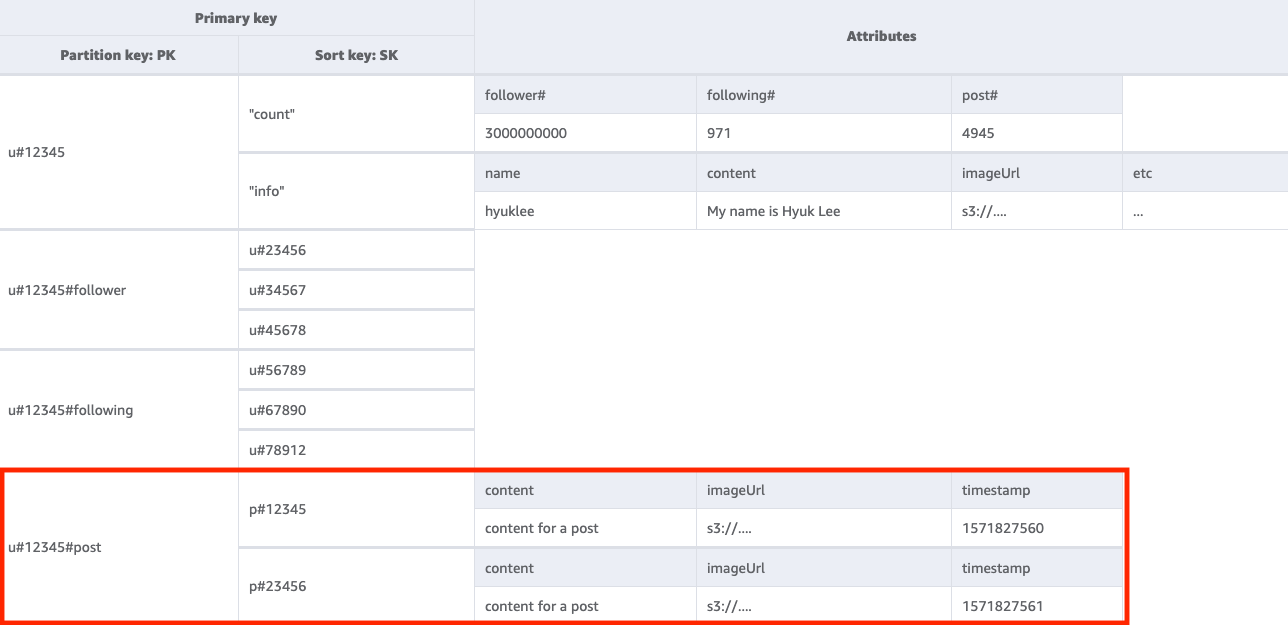
4단계: 액세스 패턴 4(getPostListByUserID) 처리
주어진 사용자가 작성한 게시물 목록을 가져오려면 키 조건 PK=<userID>#post를 사용하여 기본 테이블을 Query해야 합니다. 여기서 한 가지 중요한 점은 사용자의 postID가 증분적이어야 한다는 것입니다. 즉, 두 번째 postID 값은 첫 번째 postID 값보다 커야 합니다(사용자는 자신의 게시물을 정렬된 방식으로 보기 원하므로). 이렇게 하려면 ULID(Universally Unique Lexicographically Sortable Identifier) 같은 시간 값을 기반으로 postID를 생성하면 됩니다.
5단계: 액세스 패턴 5(getUserLikesByPostID) 처리
주어진 사용자의 게시물에 좋아요를 누른 사용자 목록을 가져오려면 키 조건 PK=<postID>#likelist를 사용하여 기본 테이블을 Query해야 합니다. 이 접근 방식은 액세스 패턴 2(getFollowerListByUserID)와 액세스 패턴 3(getFollowingListByUserID)에서 팔로워 목록 및 팔로우하는 사용자 목록을 검색하는 데 사용한 것과 동일한 패턴입니다.
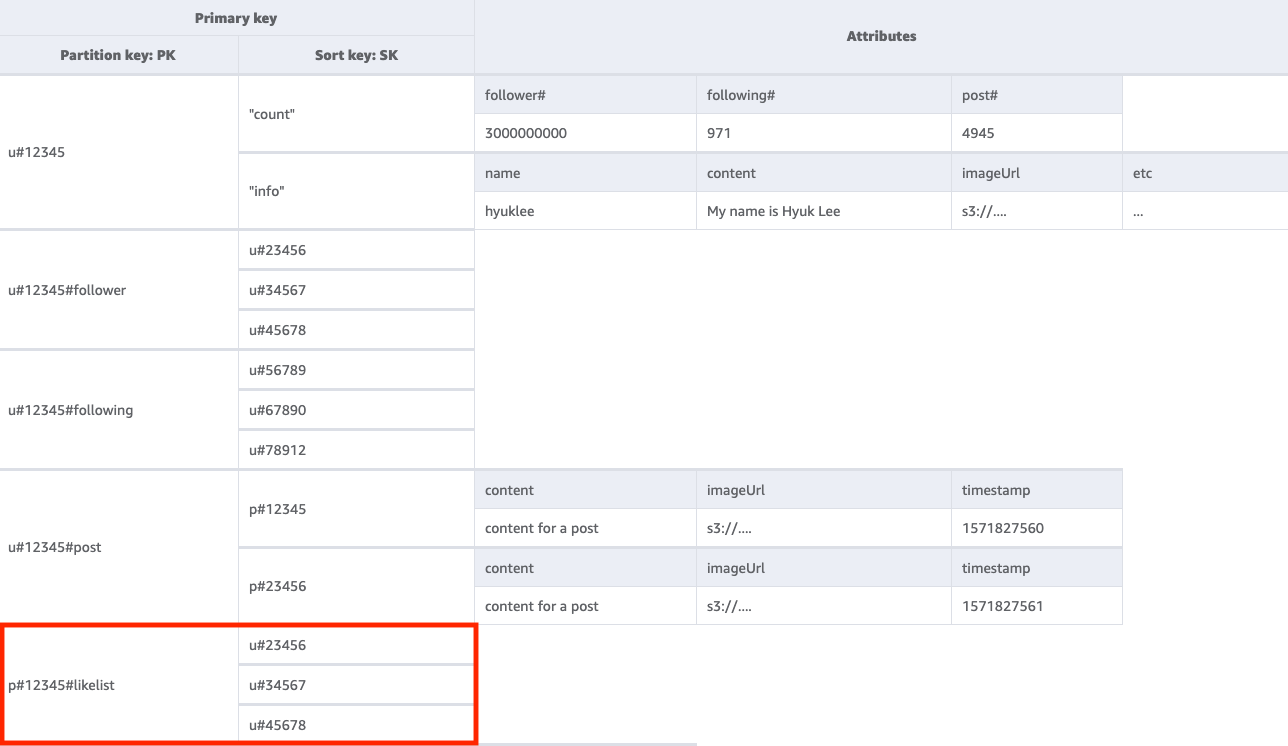
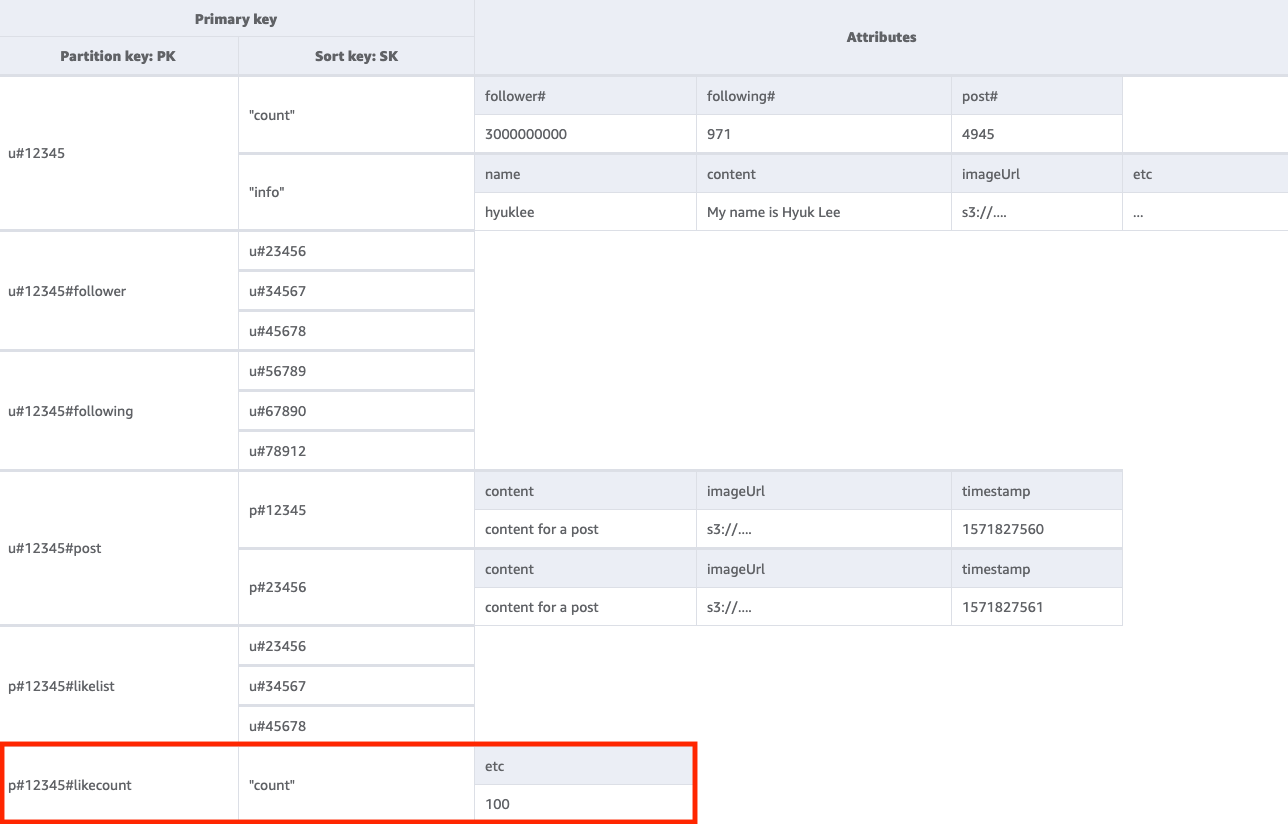
6단계: 액세스 패턴 6(getLikeCountByPostID) 처리
주어진 게시물에 대한 좋아요 수를 가져오려면 키 조건 PK=<postID>#likecount를 사용하여 기본 테이블에서 GetItem 작업을 수행해야 합니다. 파티션의 처리량이 초당 1,000WCU를 초과하면 제한이 발생하기 때문에 이 액세스 패턴은 팔로워가 많은 사용자(예: 유명인)가 게시물을 작성할 때마다 제한 문제를 일으킬 수 있습니다. 이 문제는 DynamoDB로 인한 것은 아니며, 소프트웨어 스택의 끝에 있기 때문에 DynamoDB에 나타납니다.
모든 사용자가 좋아요 수를 동시에 보는 것이 정말 필요한지 아니면 시간이 지남에 따라 점진적으로 표시되어도 무방한지 평가해야 합니다. 일반적으로 게시물의 좋아요 수가 즉시 100% 정확할 필요는 없습니다. 애플리케이션과 DynamoDB 사이에 대기열을 두어 정기적으로 업데이트가 이루어지도록 하면 이 전략을 구현할 수 있습니다.
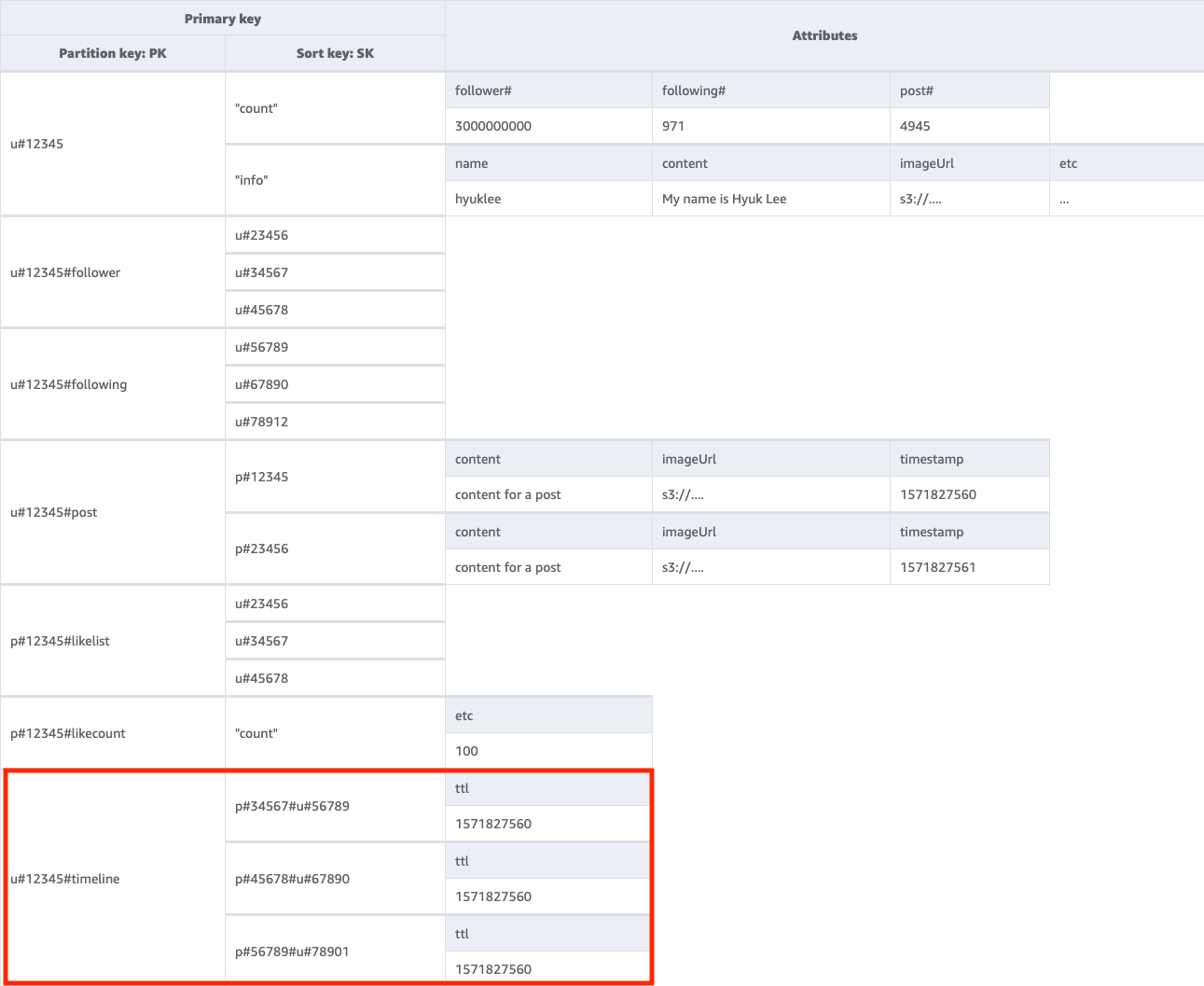
7단계: 액세스 패턴 7(getTimelineByUserID) 처리
주어진 사용자의 타임라인을 가져오려면 키 조건 PK=<userID>#timeline를 사용하여 기본 테이블에서 Query 작업을 수행해야 합니다. 사용자의 팔로워들이 게시물을 동기식으로 봐야 하는 시나리오를 생각해 보겠습니다. 사용자가 게시물을 작성할 때마다 팔로워 목록을 읽고 팔로워의 userID와 postID가 모든 팔로워의 타임라인 키에 천천히 입력됩니다. 그런 다음 애플리케이션이 시작되면 Query 작업으로 타임라인 키를 읽고 새 항목에 BatchGetItem 작업을 사용하여 타임라인 화면을 userID와 postID의 조합으로 채울 수 있습니다. API 직접 호출로 타임라인을 읽을 수는 없지만 게시물을 자주 수정할 수 있다면 이것이 더 비용 효율적인 솔루션입니다.
타임라인은 최근 게시물을 보여 주는 곳이므로 이전 게시물을 정리할 방법이 필요합니다. WCU를 사용하여 삭제하는 대신 DynamoDB의 TTL 기능을 사용하여 무료로 삭제할 수 있습니다.
모든 액세스 패턴과 스키마 설계에서 이를 처리하는 방법이 아래 표에 요약되어 있습니다.
| 액세스 패턴 | 기본 테이블/GSI/LSI | 연산 | 파티션 키 값 | 정렬 키 값 | 기타 조건/필터 |
|---|---|---|---|---|---|
| getUserInfoByUserID | 기본 테이블 | 쿼리 | PK=<userID> | ||
| getFollowerListByUserID | 기본 테이블 | 쿼리 | PK=<userID>#follower | ||
| getFollowingListByUserID | 기본 테이블 | 쿼리 | PK=<userID>#following | ||
| getPostListByUserID | 기본 테이블 | 쿼리 | PK=<userID>#post | ||
| getUserLikesByPostID | 기본 테이블 | 쿼리 | PK=<postID>#likelist | ||
| getLikeCountByPostID | 기본 테이블 | GetItem | PK=<postID>#likecount | ||
| getTimelineByUserID | 기본 테이블 | 쿼리 | PK=<userID>#timeline |
소셜 네트워크 최종 스키마
다음은 최종 스키마 설계입니다. 이 스키마 설계를 JSON 파일로 다운로드하려면 GitHub의 DynamoDB 예제
기본 테이블:
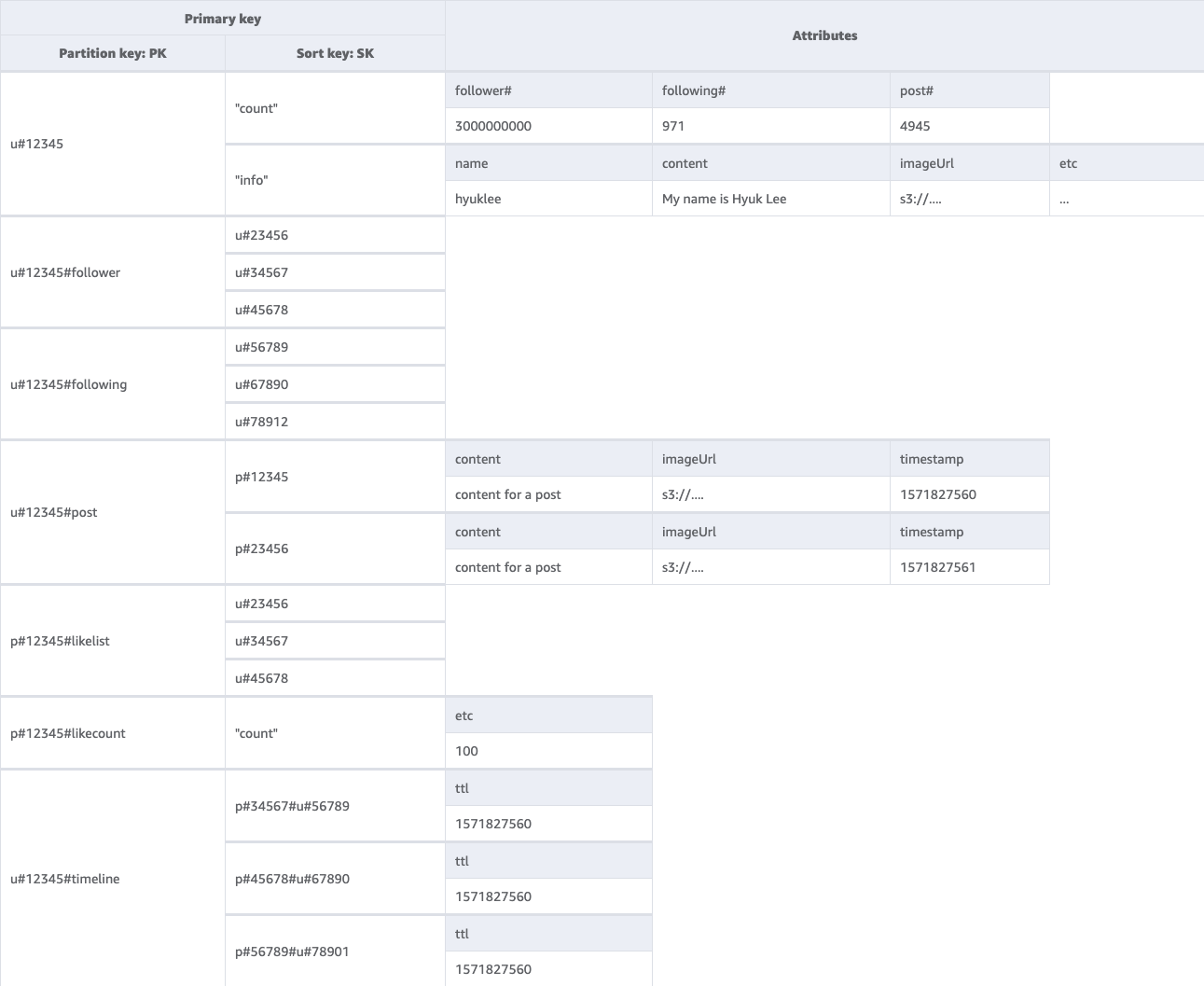
이 스키마 설계와 함께 NoSQL Workbench 사용
이 최종 스키마를 DynamoDB 데이터 모델링, 데이터 시각화, 쿼리 개발 기능을 제공하는 시각적 도구인 NoSQL Workbench로 가져와서 새 프로젝트를 추가로 탐색하고 편집할 수 있습니다. 시작하려면 다음 단계를 따릅니다.
-
NoSQL Workbench 다운로드 자세한 내용은 DynamoDB용 NoSQL Workbench 다운로드 섹션을 참조하세요.
-
위에 나열된 JSON 스키마 파일을 다운로드합니다. 이 파일은 이미 NoSQL Workbench 모델 형식으로 되어 있습니다.
-
JSON 스키마 파일을 NoSQL Workbench로 가져옵니다. 자세한 내용은 기존 데이터 모델 가져오기 섹션을 참조하세요.
-
NOSQL Workbench로 가져온 후 데이터 모델을 편집할 수 있습니다. 자세한 내용은 기존 데이터 모델 편집 섹션을 참조하세요.
