Amazon Forecast 不再提供給新客戶。Amazon Forecast 的現有客戶可以繼續正常使用服務。進一步了解"
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
評估預測器準確性
Amazon Forecast 會產生準確性指標來評估預測器,並協助您選擇要用來產生預測的項目。預測會使用根均方誤差 (RMSE)、加權量化損失 (wQL)、平均絕對百分比誤差 (MAPE)、平均絕對縮放誤差 (MASE) 和加權絕對百分比誤差 (WAPE) 指標來評估預測器。
Amazon Forecast 使用回溯測試來調校參數並產生準確性指標。在回溯測試期間,預測會自動將您的時間序列資料分割成兩組:訓練集和測試集。訓練集用於訓練模型,並產生測試集中資料點的預測。預測會比較預測值與測試集中觀察值,藉此評估模型的準確性。
預測可讓您使用不同的預測類型來評估預測器,這可以是一組四分位數預測和平均預測。平均預測提供點估計值,而四分位數預測通常會提供一系列可能的結果。
Python 筆記本
如需評估預測器指標step-by-step指南,請參閱使用項目層級回溯測試運算指標。
主題
解譯準確性指標
Amazon Forecast 提供根均方誤差 (RMSE)、加權量化損失 (wQL)、平均加權量化損失 (平均 wQL)、平均絕對擴展錯誤 (MASE)、平均絕對百分比錯誤 (MAPE) 和加權絕對百分比錯誤 (WAPE) 指標,以評估您的預測器。除了整體預測器的指標之外,預測也會計算每個回溯測試時段的指標。
您可以使用 Amazon Forecast Software Development Kit (SDK) 和 Amazon Forecast 主控台來檢視預測器的準確性指標。
使用 GetAccuracyMetrics 操作,指定 y PredictorArn 來檢視每個回溯測試的 RMSE、MASE、MAPE、WAPE、平均 wQL 和 wQL 指標。
{
"PredictorArn": "arn:aws:forecast:region:acct-id:predictor/example-id"
}
注意
對於平均 wQL、wQL、RMSE、MASE、MAPE 和 WAPE 指標,較低的值表示卓越的模型。
加權量化損失 (wQL)
加權量化損失 (wQL) 指標會測量指定四分位數的模型準確性。當低預測和高預測的成本不同時,特別有用。透過設定 wQL 函數的權重 (τ),您可以自動納入對低預測和高預測的不同懲罰。
損失函數的計算方式如下。
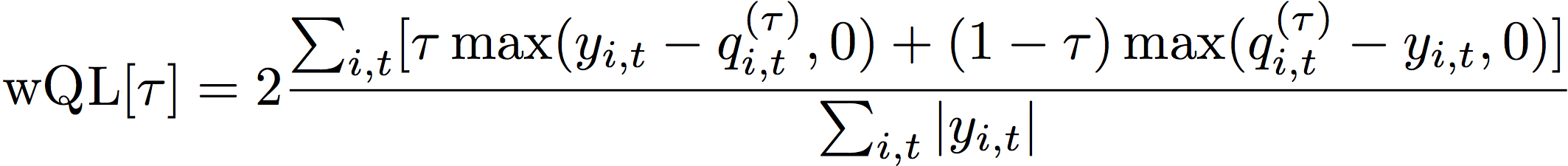
- 其中:
-
τ - 集合 {0.01、0.02、...、0.99} 中的四分位數
qi,t(τ) - 模型預測的 τ 四分位數。
yi,t - 點的觀察值 (i,t)
wQL 的四分位數 (τ) 範圍可從 0.01 (P1) 到 0.99 (P99)。無法計算平均預測的 wQL 指標。
根據預設,預測會在 0.1(P10)、 0.5 (P50) 和 0.9(P90) 運算 wQL。
-
P10 (0.1) - 實際值預期低於預測值的時間 10%。
-
P50 (0.5) - 實際值預期低於預測值的時間 50%。這也稱為中位數預測。
-
P90 (0.9) - 實際值預期會低於預測值 90% 的時間。
在零售業中,庫存不足的成本通常高於庫存過多的成本,因此 P75 的預測 (τ = 0.75) 可能比在中位數四分位數 (P50) 的預測更重要。在這些情況下,wQL【0.75】 會將較大的懲罰權重指派給預測不足 (0.75),並將較小的懲罰權重指派給預測過度 (0.25)。
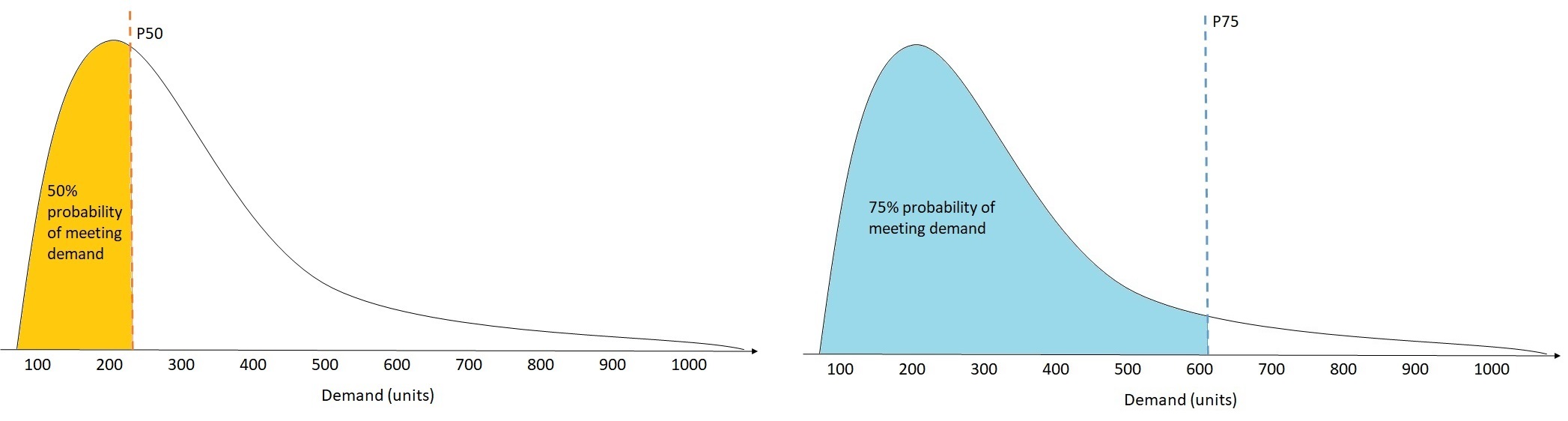
上圖顯示 wQL【0.50】 和 wQL【0.75】 的不同需求預測。P75 的預測值明顯高於 P50 的預測值,因為 P75 預測預期會滿足 75% 的時間需求,而 P50 預測預期只會滿足 50% 的時間需求。
當所有項目和時間點的觀察值總和在指定的回溯測試時段大約為零時,加權四分位數損失表達式即為未定義。在這些情況下,預測會輸出未加權的四分位數損失,這是 wQL 表達式中的分子。
預測也會計算平均 wQL,這是所有指定四分位數的加權四分位數損失平均值。根據預設,這將是 wQL【0.10】、wQL【0.50】 和 wQL【0.90】 的平均值。
加權絕對百分比錯誤 (WAPE)
加權絕對百分比錯誤 (WAPE) 會測量預測值與觀察值的整體偏差。WAPE 的計算方式是取得觀察值的總和和預測值的總和,並計算這兩個值之間的錯誤。數值越低表示模型越準確。
當所有時間點和所有項目的觀察值總和在指定的回溯測試時段大約為零時,加權絕對百分比錯誤表達式會未定義。在這些情況下,預測會輸出未加權絕對錯誤總和,這是 WAPE 表達式中的分子。
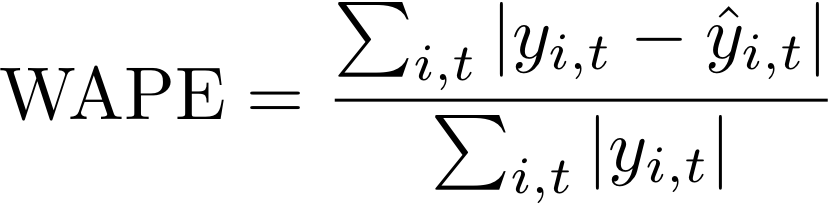
- 其中:
-
yi,t - 點的觀察值 (i,t)
i,t ŷ - 點的預測值 (i,t)
預測會使用平均預測做為預測值 i,tŷ。
WAPE 對於極端值比根均方誤差 (RMSE) 更強大,因為它使用絕對誤差而非平方誤差。
Amazon Forecast 先前將 WAPE 指標稱為平均絕對百分比錯誤 (MAPE),並使用中位數預測 (P50) 做為預測值。Forecast 現在使用平均預測來計算 WAPE。wQL【0.5】 指標等同於 WAPE【中位數】 指標,如下所示:
![Mathematical equation showing the equivalence of wQL[0.5] and WAPE[median] metrics.](images/wql-to-wape.PNG)
均方根錯誤 (RMSE)
Root Mean Square Error (RMSE) 是平方錯誤平均值的平方根,因此比其他準確度指標對極端值更為敏感。數值越低表示模型越準確。
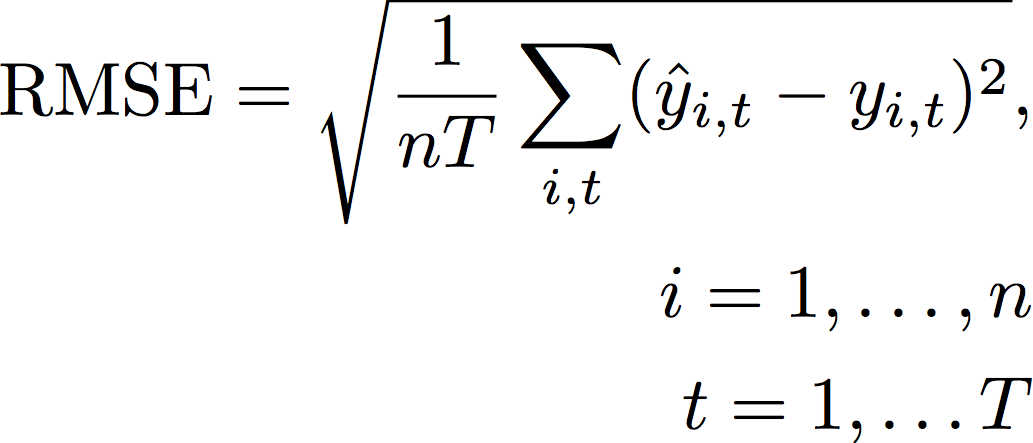
- 其中:
-
yi,t - 點的觀察值 (i,t)
i,t ŷ - 點的預測值 (i,t)
nT - 測試集中的資料點數量
預測會使用平均預測做為預測值 i,tŷ。計算預測器指標時,nT 是回溯測試視窗中的資料點數量。
RMSE 使用殘差的平方值,這會放大極端值的影響。在只有幾個大型錯誤預測可能非常昂貴的使用案例中,RMSE 是更相關的指標。
在 2020 年 11 月 11 日之前建立的預測器預設會使用 0.5 四分位數 (P50) 計算 RMSE。Forecast 現在使用平均預測。
平均絕對百分比錯誤 (MAPE)
平均絕對百分比錯誤 (MAPE) 會取得每個時間單位觀察值和預測值之間百分比錯誤的絕對值,然後平均這些值。數值越低表示模型越準確。
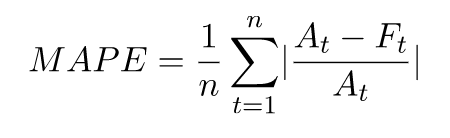
- 其中:
-
At - 點 t 的觀察值
Ft - 點 t 的預測值
n - 時間序列中的資料點數量
預測會使用平均預測做為預測值 Ft。
MAPE 適用於時間點和極端值之間值有顯著差異的情況。
平均絕對擴展錯誤 (MASE)
平均絕對擴展錯誤 (MASE) 的計算方式是將平均錯誤除以擴展係數。此擴展因素取決於季節性值 m,根據預測頻率選擇。數值越低表示模型越準確。
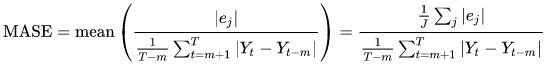
- 其中:
-
Yt - 點 t 的觀察值
Yt-m - 點 t-m 的觀察值
ej - 點 j 的錯誤 (觀察值 - 預測值)
m - 季節性值
預測會使用平均預測做為預測值。
MASE 非常適合具有循環性質或季節性屬性的資料集。例如,預測在夏季高需求和在冬季低需求的項目,可以受益於考量季節性影響。
匯出準確性指標
注意
匯出檔案可以直接從資料集匯入傳回資訊。如果匯入的資料含公式或命令,這會使檔案受到 CSV 注入的攻擊。因此,匯出的檔案可能會提示安全性警告。若要避免惡意活動,請在讀取匯出的檔案時停用連結和巨集。
預測可讓您匯出回測期間產生的預測值和準確性指標。
您可以使用這些匯出來評估特定時間點和四分位數的特定項目,並進一步了解您的預測器。回溯測試匯出會傳送至指定的 S3 位置,並包含兩個資料夾:
-
預測值:包含 CSV 或 Parquet 檔案,每個回溯測試的每個預測類型都有預測值。
-
accuracy-metrics-values包含 CSV 或 Parquet 檔案,其中包含每個回測的指標,以及所有回測的平均值。這些指標包括每個四分位數的 wQL、平均 wQL、RMSE、MASE、MAPE 和 WAPE。
forecasted-values 資料夾包含每個回溯測試時段每個預測類型的預測值。它也包含項目 IDs、維度、時間戳記、目標值和回溯測試時段開始和結束時間的相關資訊。
accuracy-metrics-values 資料夾包含每個回測時段的準確性指標,以及所有回測時段的平均指標。它包含每個指定四分位數的 wQL 指標,以及平均 wQL、RMSE、MASE、MAPE 和 WAPE 指標。
兩個資料夾中的檔案都遵循命名慣例:<ExportJobName>_<ExportTimestamp>_<PartNumber>.csv。
您可以使用 Amazon Forecast 軟體開發套件 (SDK) 和 Amazon Forecast 主控台匯出準確性指標。
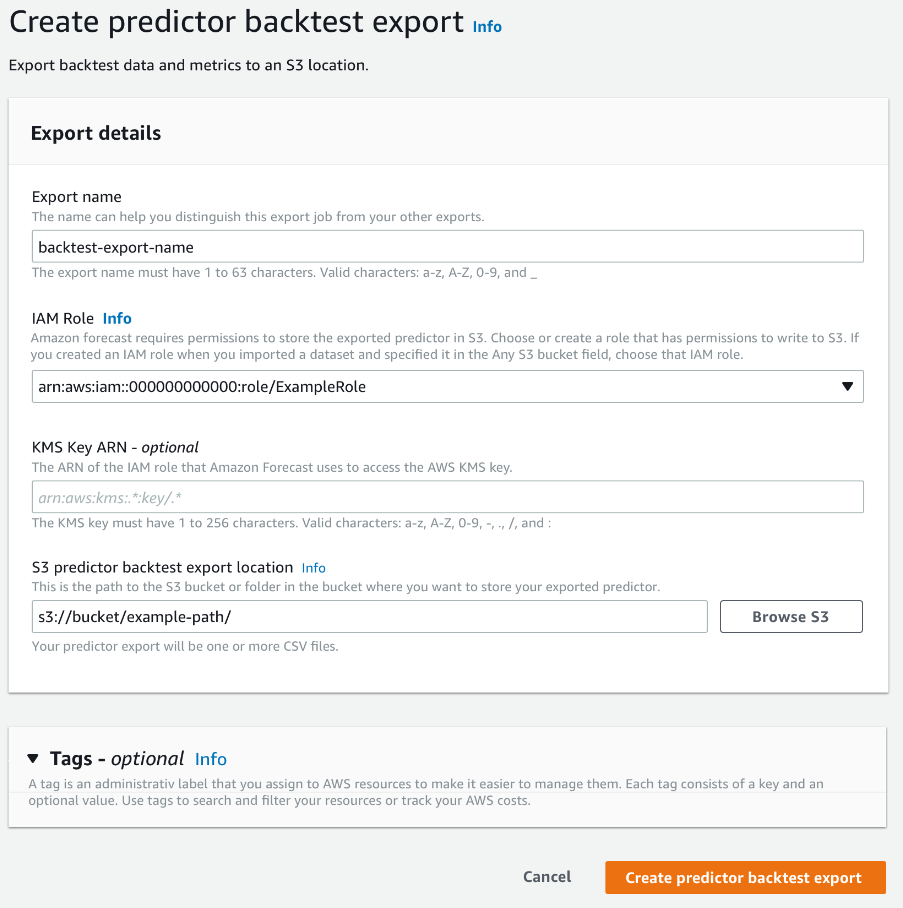
使用 CreatePredictorBacktestExportJob操作,指定DataDestination物件中的 S3 位置和 IAM 角色,以及 PredictorArn和 PredictorBacktestExportJobName。
例如:
{
"Destination": {
"S3Config": {
"Path": "s3://bucket/example-path/",
"RoleArn": "arn:aws:iam::000000000000:role/ExampleRole"
}
},
"Format": PARQUET;
"PredictorArn": "arn:aws:forecast:region:predictor/example",
"PredictorBacktestExportJobName": "backtest-export-name",
}
選擇預測類型
Amazon Forecast 使用預測類型來建立預測和評估預測器。預測類型有兩種形式:
-
平均預測類型 - 使用平均值做為預期值的預測。通常用作指定時間點的點預測。
-
量化預測類型 - 指定四分位數的預測。通常用於提供預測間隔,這是可考慮預測不確定性的一系列可能值。例如,
0.65四分位數的預測會預估低於觀察值 65% 的時間的值。
根據預設,預測會針對預測器預測類型使用下列值:0.1(P10)、0.5(P50) 和 0.9(P90)。您最多可以選擇五種自訂預測類型,包括 0.01(P1) 到 0.99(P99) 的 mean和 quantiles。
Quantiles 可以提供預測的上限和下限。例如,使用預測類型 0.1(P10) 和 0.9(P90) 提供稱為 80% 信賴區間的一系列值。觀察值預期低於 P10 值 10% 的時間,而 P90 值預期高於觀察值 90% 的時間。透過在 p10 和 P90 產生預測,您可以預期 80% 時間的真實值落在這些界限之間。此值範圍由下圖中 P10 和 P90 之間的陰影區域描述。
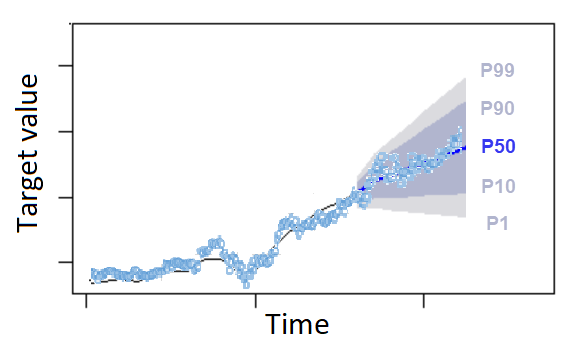
當低預測成本與高預測成本不同時,您也可以使用四分位數預測作為點預測。例如,在某些情況下,庫存不足的成本高於庫存過多的成本。在這些情況下,0.65 (P65) 的預測比中位數 (P50) 或平均預測更重要。
訓練預測器時,您可以使用 Amazon Forecast Software Development Kit (SDK) 和 Amazon Forecast 主控台來選擇自訂預測類型。
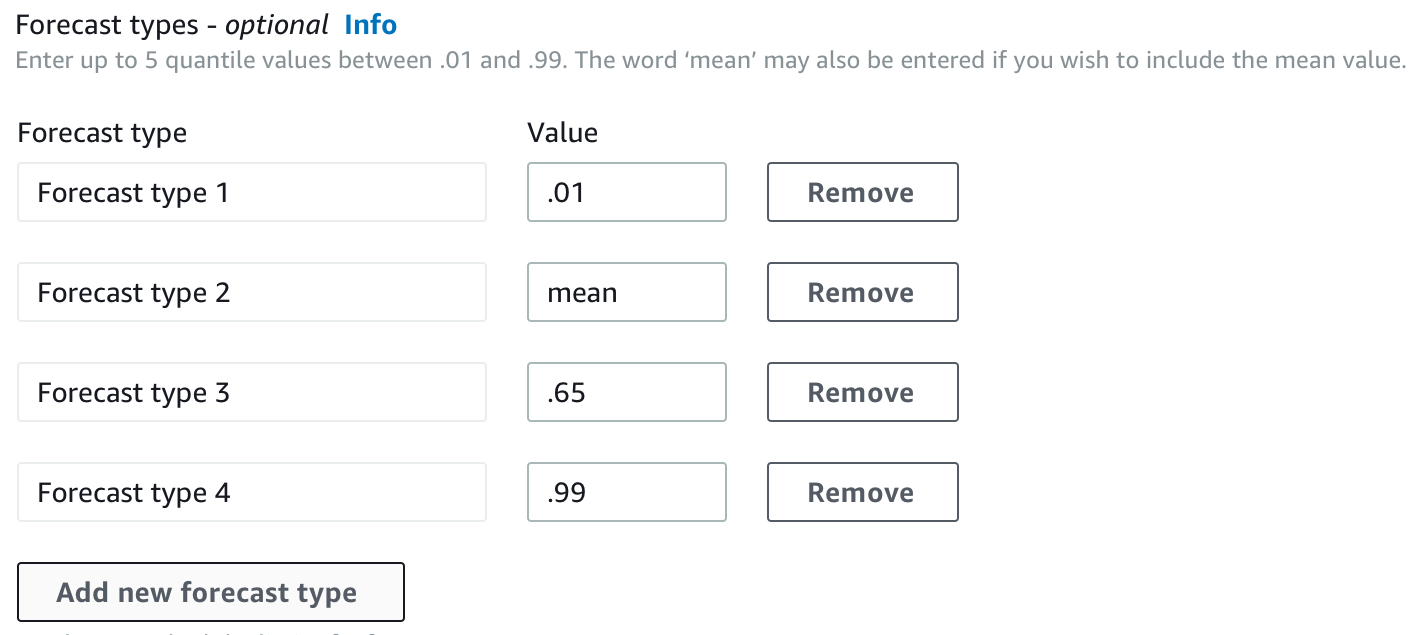
使用 CreateAutoPredictor操作,在 ForecastTypes 參數中指定自訂預測類型。將 參數格式化為字串陣列。
例如,若要在 0.01、0.65、 mean和 0.99 預測類型建立預測器,請使用下列程式碼。
{
"ForecastTypes": [ "0.01", "mean", "0.65", "0.99" ],
}, 使用舊版預測器
設定回測參數
預測使用回溯測試來計算準確性指標。如果您執行多個回溯測試,預測會平均所有回溯測試時段的每個指標。根據預設,預測會運算一個回測,回測視窗的大小 (測試集) 等於預測時間範圍的長度 (預測視窗)。您可以在訓練預測器時同時設定回溯測試時段長度和回溯測試案例的數量。
預測會省略來自回溯測試程序的填入值,且指定回溯測試時段內填入值的任何項目都會從該回溯測試中排除。這是因為預測只會比較預測值與回測期間觀察到的值,而填入的值不會觀察到。
回溯測試時段必須至少與預測時間範圍一樣大,且長度小於整個目標時間序列資料集的一半。您可以選擇 1 到 5 個回溯測試。
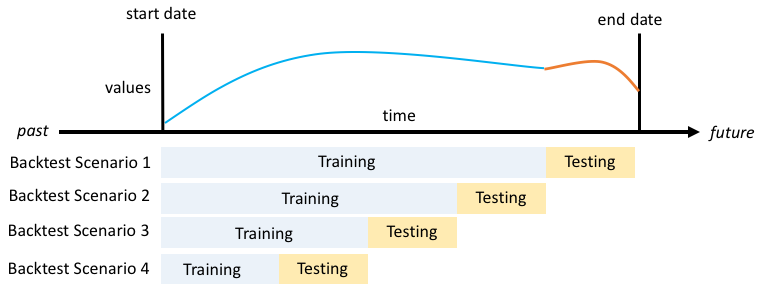
一般而言,增加回溯測試數量會產生更可靠的準確性指標,因為在測試期間使用時間序列的較大部分,且預測能夠在所有回溯測試中取得指標的平均值。
您可以使用 Amazon Forecast Software Development Kit (SDK) 和 Amazon Forecast 主控台來設定回溯測試參數。

使用 CreatePredictor 操作,在 EvaluationParameters 資料類型中設定回溯測試參數。指定使用 BackTestWindowOffset 參數進行回溯測試期間測試集的長度,以及使用 NumberOfBacktestWindows 參數進行回溯測試時段的數量。
例如,若要執行 2 個具有 10 個時間點的測試集的回溯測試,請使用下列程式碼。
"EvaluationParameters": {
"BackTestWindowOffset": 10,
"NumberOfBacktestWindows": 2
}
HPO 和 AutoML
根據預設,Amazon Forecast 在超參數最佳化 0.1(HPO) 期間使用 0.9(P10)、0.5(P50) 和 (P90) 四分位數進行超參數調校,並在 AutoML 期間使用模型選擇。如果您在建立預測器時指定自訂預測類型,預測會在 HPO 和 AutoML 期間使用這些預測類型。
如果指定了自訂預測類型,預測會使用這些指定的預測類型來判斷 HPO 和 AutoML 期間的最佳結果。在 HPO 期間,預測會使用第一個回測時段來尋找最佳的超參數值。在 AutoML 期間,預測會使用所有回溯測試視窗的平均值,以及 HPO 的最佳超參數值,來尋找最佳演算法。
對於 AutoML 和 HPO,Forecast 會選擇選項,將預測類型的平均損失降至最低。您也可以在 AutoML 和 HPO 期間,使用下列其中一項準確度指標來最佳化預測器:平均加權量化損失 (平均 wQL)、加權絕對百分比錯誤 (WAPE)、根平均平方錯誤 (RMSE)、平均絕對百分比錯誤 (MAPE) 或平均絕對縮放錯誤 (MASE)。
您可以使用 Amazon Forecast Software Development Kit (SDK) 和 Amazon Forecast 主控台來選擇最佳化指標。
使用 CreatePredictor操作,在 ObjectiveMetric 參數中指定自訂預測類型。
ObjectiveMetric 參數接受下列值:
-
AverageWeightedQuantileLoss- 平均加權量化損失 -
WAPE- 加權絕對百分比錯誤 -
RMSE- 根均方錯誤 -
MAPE- 平均絕對百分比錯誤 -
MASE- 絕對擴展錯誤平均值
例如,若要使用 AutoML 建立預測器並使用平均絕對擴展錯誤 (MASE) 準確度指標進行最佳化,請使用下列程式碼。
{
...
"PerformAutoML": "true",
...
"ObjectiveMetric": "MASE",
}, 