Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Trascrizioni alternative
Quando Amazon Transcribe trascrive l'audio, crea versioni diverse della stessa trascrizione e assegna un punteggio di confidenza a ciascuna versione. In una trascrizione tipica, si ottiene solo la versione con il punteggio di affidabilità più elevato.
Se attivi trascrizioni alternative, Amazon Transcribe restituisce altre versioni della trascrizione con livelli di confidenza inferiori. Si può scegliere che vengano restituite fino a 10 trascrizioni alternative. Se specificate un numero maggiore di alternative rispetto a quello Amazon Transcribe identificato, viene restituito solo il numero effettivo di alternative.
Tutte le alternative si trovano nello stesso file di output della trascrizione e sono presentate a livello di segmento. I segmenti sono pause naturali nel discorso, ad esempio una modifica dell'oratore o una pausa nell'audio.
Le trascrizioni alternative sono disponibili solo per le trascrizioni in batch.
L'output della trascrizione è strutturato come segue. Le ellissi (...) negli esempi di codice indicano dove il contenuto è stato rimosso per brevità.
Una trascrizione finale completa per un determinato segmento.
"results": { "language_code": "en-US", "transcripts": [ { "transcript": "The amazon is the largest rainforest on the planet." } ],Un punteggio di affidabilità per ogni parola della sezione
transcriptprecedente."items": [ { "start_time": "1.15", "end_time": "1.35", "alternatives": [ { "confidence": "1.0", "content": "The" } ], "type": "pronunciation" }, { "start_time": "1.35", "end_time": "2.05", "alternatives": [ { "confidence": "1.0", "content": "amazon" } ], "type": "pronunciation" },-
Le trascrizioni alternative si trovano nella parte
segmentsdell'output della trascrizione. Le alternative per ogni segmento sono ordinate in base al punteggio di affidabilità decrescente."segments": [ { "start_time": "1.04", "end_time": "5.065", "alternatives": [ {..."transcript": "The amazon is the largest rain forest on the planet.", "items": [ { "start_time": "1.15", "confidence": "1.0", "end_time": "1.35", "type": "pronunciation", "content": "The" },...{ "start_time": "3.06", "confidence": "0.0037", "end_time": "3.38", "type": "pronunciation", "content": "rain" }, { "start_time": "3.38", "confidence": "0.0037", "end_time": "3.96", "type": "pronunciation", "content": "forest" }, -
Uno stato alla fine dell'output della trascrizione.
"status": "COMPLETED" }
Richiesta di trascrizioni alternative
È possibile richiedere trascrizioni alternative utilizzando l’AWS Management Console, l’AWS CLI o gli SDK AWS ; consultare quanto segue per alcuni esempi:
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo.
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
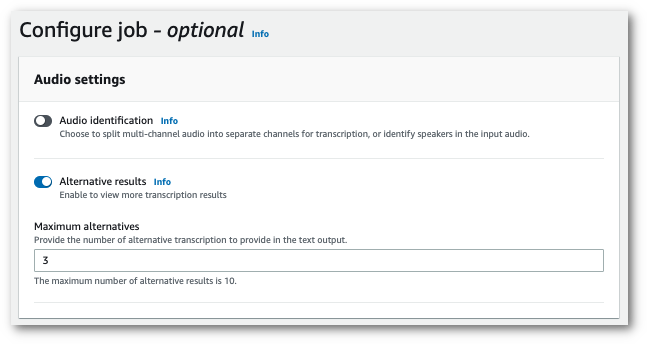
Selezionare Risultati alternativi e specificare il numero massimo di risultati di trascrizioni alternative che si desidera nella trascrizione.
-
Selezionare Crea processo per eseguire il processo di trascrizione.
Questo esempio utilizza il comando inizia-processo-trascrizioneShowAlternatives. Per ulteriori informazioni, consultare StartTranscriptionJob e ShowAlternatives.
Nota che se si include ShowAlternatives=true nella richiesta, si dovrà includere anche MaxAlternatives.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ShowAlternatives=true,MaxAlternatives=4
Ecco un altro esempio che utilizza il comando inizia-processo-trascrizione
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-alt-transcription-job.json
Il file my-first-alt-transcription-job.json contiene il seguente corpo della richiesta.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "ShowAlternatives": true, "MaxAlternatives":4} }
L'esempio seguente utilizza AWS SDK per Python (Boto3) per richiedere trascrizioni alternative utilizzando l'ShowAlternativesargomento per il metodo start_transcription_job.StartTranscriptionJob e ShowAlternatives.
Per ulteriori esempi di utilizzo degli AWS SDK, inclusi esempi relativi a funzionalità specifiche, scenari e interservizi, consulta il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDK
Tenere presente che se si include 'ShowAlternatives':True nella richiesta, si dovrà includere anche MaxAlternatives.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'ShowAlternatives':True, 'MaxAlternatives':4} ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
