Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Amazon Transcribe supporta gli output WebVTT (*.vtt) SubRip e (*.srt) da utilizzare come sottotitoli video. È possibile selezionare uno o entrambi i tipi di file quando si imposta il processo di trascrizione video in batch. Quando si utilizza la funzionalità dei sottotitoli, vengono prodotti i file di sottotitoli selezionati e un normale file di trascrizione (contenente informazioni aggiuntive). I file di sottotitoli e trascrizioni vengono inviati alla stessa destinazione.
I sottotitoli vengono visualizzati contemporaneamente alla pronuncia del testo e rimangono visibili fino a quando non si verifica una pausa naturale o finché il parlante non finisce di parlare. Tieni presente che se abiliti i sottotitoli nella richiesta di trascrizione e l'audio non contiene alcun dialogo, non viene creato un file di sottotitoli.
Importante
Amazon Transcribe utilizza un indice iniziale predefinito di 0 per l'output dei sottotitoli, che differisce dal valore più utilizzato di. 1 Se hai bisogno di un indice iniziale di1, puoi specificarlo nella AWS Management Console o nella tua richiesta API utilizzando il OutputStartIndexparametro.
L'utilizzo di un indice iniziale errato può causare errori di compatibilità con altri servizi, quindi assicurati di verificare l'indice iniziale richiesto prima di creare i sottotitoli. Se non hai certezza del valore da utilizzare, ti consigliamo di scegliere 1. Per ulteriori informazioni, consulta Subtitles.
Funzionalità supportate con i sottotitoli:
-
Redazione dei contenuti: qualsiasi contenuto redatto viene visualizzato come “
PII” sia nei sottotitoli che nei normali file di output delle trascrizioni. L'audio non viene alterato. -
Filtri del vocabolario: i file dei sottotitoli vengono generati dal file di trascrizione, quindi tutte le parole filtrate nell'output di trascrizione standard vengono filtrate anche nei sottotitoli. I contenuti filtrati vengono visualizzati come spazi bianchi o
***nei file di trascrizione e sottotitoli. L'audio non viene alterato. -
Diarizzazione dei parlanti: se in un determinato segmento di sottotitoli sono presenti più parlanti, vengono utilizzati dei trattini per distinguere ciascun parlante. Questo vale sia per WebVTT che per i formati, ad SubRip esempio:
-- Testo pronunciato dalla persona 1
-- Testo pronunciato dalla persona 2
I file dei sottotitoli vengono memorizzati nella stessa Amazon S3 posizione dell'output della trascrizione.
Per una video guida sulla creazione dei sottotitoli, consulta:
Generazione di file di sottotitoli
È possibile creare file di sottotitoli utilizzando AWS Management ConsoleAWS CLI, o AWS SDKs; consultate i seguenti esempi:
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo. Le opzioni per i sottotitoli si trovano nel pannello Dati di output.
-
Seleziona i formati che desideri per i file dei sottotitoli, quindi scegli un valore per l'indice iniziale. Si noti che l' Amazon Transcribe impostazione predefinita è
0, ma1è più utilizzata. Se non hai certezza del valore da utilizzare, ti consigliamo di scegliere1, in quanto ciò potrebbe migliorare la compatibilità con altri servizi.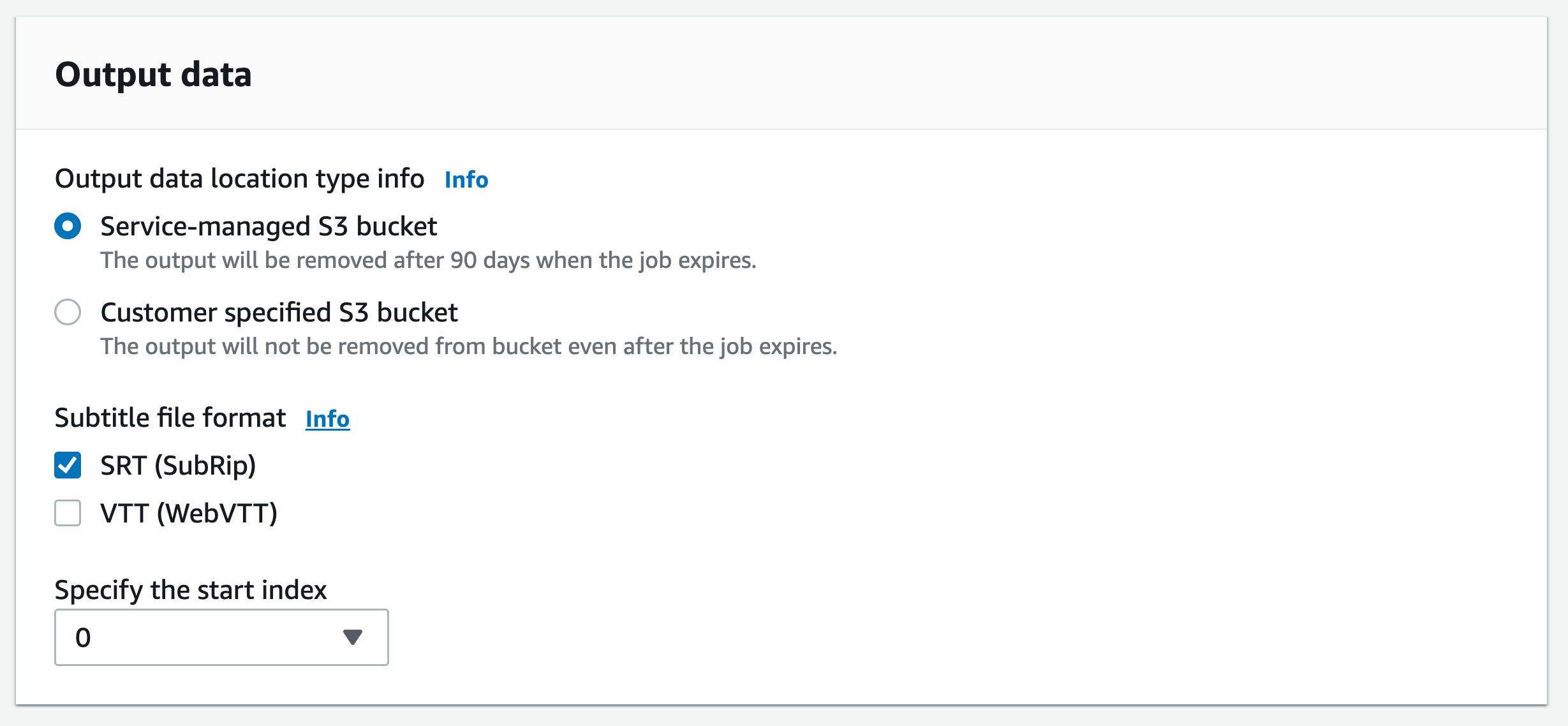
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
-
Seleziona Crea processo per eseguire il processo di trascrizione.
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo. Le opzioni per i sottotitoli si trovano nel pannello Dati di output.
-
Seleziona i formati che desideri per i file dei sottotitoli, quindi scegli un valore per l'indice iniziale. Si noti che l' Amazon Transcribe impostazione predefinita è
0, ma1è più utilizzata. Se non hai certezza del valore da utilizzare, ti consigliamo di scegliere1, in quanto ciò potrebbe migliorare la compatibilità con altri servizi.
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
-
Seleziona Crea processo per eseguire il processo di trascrizione.
Questo esempio utilizza il comando e il parametro. start-transcription-jobSubtitles Per ulteriori informazioni, consulta StartTranscriptionJob e Subtitles.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --subtitles Formats=vtt,srt,OutputStartIndex=1
Ecco un altro esempio di utilizzo del start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-subtitle-job.json
Il file my-first-subtitle-job.json contiene il seguente corpo della richiesta.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Subtitles": {
"Formats": [
"vtt","srt"
],
"OutputStartIndex": 1
}
}Questo esempio utilizza il AWS SDK per Python (Boto3) per aggiungere i sottotitoli utilizzando l'Subtitlesargomento per il metodo start_transcription_job.StartTranscriptionJob e Subtitles.
Per ulteriori esempi di utilizzo di, inclusi esempi relativi a scenari AWS SDKs e servizi diversi, inclusi esempi relativi a funzionalità specifiche, consultate il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDKs
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Subtitles = {
'Formats': [
'vtt','srt'
],
'OutputStartIndex': 1
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)