Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Se l'audio ha due canali, puoi utilizzare l'identificazione del canale per trascrivere il discorso da ciascun canale separatamente. Amazon Transcribe attualmente non supporta l'audio con più di due canali.
Nella trascrizione, ai canali vengono assegnate le etichette ch_0 e ch_1.
Oltre alle sezioni di trascrizione standard (transcripts e items), le richieste con identificazione del canale abilitata includono una sezione channel_labels. Questa sezione contiene ogni enunciato o segno di punteggiatura, raggruppato per canale e per etichetta del canale associata, i timestamp e il punteggio di affidabilità associati.
"channel_labels": {
"channels": [
{
"channel_label": "ch_0",
"items": [
{
"channel_label": "ch_0",
"start_time": "4.86",
"end_time": "5.01",
"alternatives": [
{
"confidence": "1.0",
"content": "I've"
}
],
"type": "pronunciation"
},
...
"channel_label": "ch_1",
"items": [
{
"channel_label": "ch_1",
"start_time": "8.5",
"end_time": "8.89",
"alternatives": [
{
"confidence": "1.0",
"content": "Sorry"
}
],
"type": "pronunciation"
},
...
"number_of_channels": 2
},Tieni presente che se una persona su un canale parla contemporaneamente a una persona su un canale separato, i timestamp di ogni canale si sovrapporranno mentre le persone parlano l'una sull'altra.
Per visualizzare una trascrizione di esempio completa con l'identificazione del canale, consulta Esempio di output di identificazione del canale (batch).
Utilizzo dell'identificazione del canale in una trascrizione in batch
Per identificare i canali in una trascrizione in batch, puoi utilizzare AWS Management ConsoleAWS CLI, o AWS SDKs; vedi quanto segue per alcuni esempi:
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo.
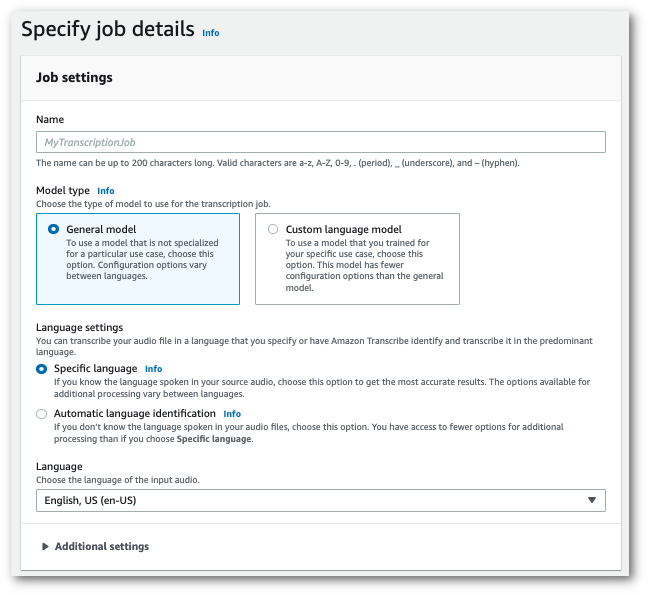
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
Nel pannello delle impostazioni audio, seleziona Identificazione del canale (sotto l'intestazione 'Tipo di identificazione audio').
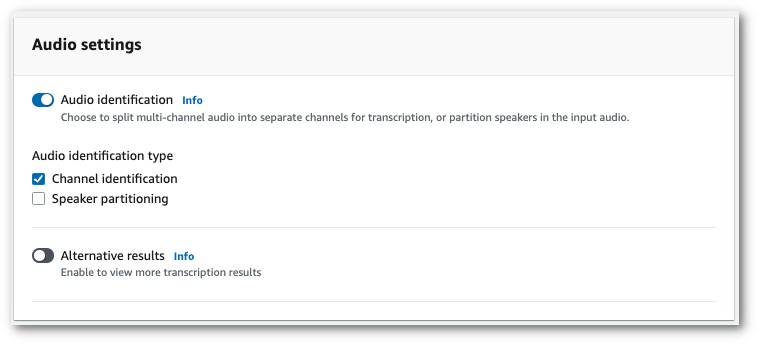
-
Seleziona Crea processo per eseguire il processo di trascrizione.
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo.
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
Nel pannello delle impostazioni audio, seleziona Identificazione del canale (sotto l'intestazione 'Tipo di identificazione audio').
-
Seleziona Crea processo per eseguire il processo di trascrizione.
Questo esempio utilizza start-transcription-jobStartTranscriptionJob.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ChannelIdentification=true
Ecco un altro esempio di utilizzo del start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-transcription-job.json
Il file my-first-transcription-job.json contiene il seguente corpo della richiesta.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"Settings": {
"ChannelIdentification": true
}
}Questo esempio utilizza il AWS SDK for Python (Boto3) per identificare i canali utilizzando il metodo start_transcription_job
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Settings = {
'ChannelIdentification':True
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)Utilizzo dell'identificazione del canale in una trascrizione in streaming
Per identificare i canali in una trascrizione in streaming, puoi utilizzare HTTP/2 o WebSockets; vedi quanto segue per alcuni esempi:
Questo esempio crea una richiesta HTTP/2 che separa i canali nell'output della trascrizione. Per ulteriori informazioni sull'utilizzo dello streaming HTTP/2 con, consulta. Amazon TranscribeImpostazione di un flusso HTTP/2 Per ulteriori dettagli sui parametri e le intestazioni specifici di Amazon Transcribe, consulta StartStreamTranscription.
POST /stream-transcription HTTP/2
host: transcribestreaming.us-west-2.amazonaws.com
X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscription
Content-Type: application/vnd.amazon.eventstream
X-Amz-Content-Sha256: string
X-Amz-Date: 20220208T235959Z
Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=string
x-amzn-transcribe-language-code: en-US
x-amzn-transcribe-media-encoding: flac
x-amzn-transcribe-sample-rate: 16000
x-amzn-channel-identification: TRUE
transfer-encoding: chunkedLe definizioni dei parametri sono disponibili nell'API Reference; i parametri comuni a tutte le operazioni AWS API sono elencati nella sezione Parametri comuni.
Questo esempio crea un URL prefirmato che separa i canali nell'output della trascrizione. Le interruzioni di riga sono state aggiunte per la leggibilità. Per ulteriori informazioni sull'utilizzo degli WebSocket stream con Amazon Transcribe, consultaConfigurazione di uno WebSocket stream. Per ulteriori dettagli sui parametri, consulta StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US &specialty=PRIMARYCARE&type=DICTATION&media-encoding=flac&sample-rate=16000&channel-identification=TRUE
Le definizioni dei parametri sono disponibili nell'API Reference; i parametri comuni a tutte le operazioni AWS API sono elencati nella sezione Parametri comuni.
