Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Identificazione della lingua con processi di trascrizione in batch
Utilizza l'identificazione della lingua in batch per identificare automaticamente la lingua o le lingue nel tuo file multimediale.
Se i file multimediali contengono una sola lingua, è possibile abilitare l’identificazione monolingue, che identifica la lingua dominante parlata nel file multimediale e crea la trascrizione utilizzando solo questa lingua.
Se i file multimediali contengono più di una lingua, è possibile abilitare l’identificazione multilingue, che identifica tutte le lingue parlate nel file multimediale e crea la trascrizione utilizzando ogni lingua identificata. Nota che viene prodotta una trascrizione multilingue. Puoi utilizzare altri servizi, ad esempio Amazon Translate per tradurre la tua trascrizione.
Consulta la tabella delle lingue supportate per un elenco completo delle lingue supportate e dei codici di lingua associati.
Per ottenere risultati ottimali, assicurati che il file multimediale contenga almeno 30 secondi di discorso.
Per esempi di utilizzo con AWS Management Console AWS CLI, e AWS Python SDK, consulta. Utilizzo dell’identificazione della lingua con trascrizione in batch
Identificazione della lingua nell'audio multilingue
Multi-language l'identificazione è destinata ai file multimediali multilingue e fornisce una trascrizione che riflette tutte le lingue supportate parlate nei file multimediali. Ciò significa che se chi parla cambia lingua durante la conversazione o se ogni partecipante parla una lingua diversa, l'output della trascrizione rileva e trascrive correttamente ogni lingua. Ad esempio, se i file multimediali contengono un parlante bilingue che alterna l'inglese americano (en-US) e l'hindi (hi-IN), l'identificazione multilingue può identificare e trascrivere l'inglese americano parlato come en-US e l'hindi parlato come hi-IN.
Ciò differisce dall'identificazione monolingue, in cui viene utilizzata una sola lingua dominante per creare una trascrizione. In questo caso, qualsiasi lingua parlata che non sia la lingua dominante viene trascritta in modo errato.
Nota
La redazione e i modelli linguistici personalizzati non sono attualmente supportati con l'identificazione multilingue.
Nota
Le seguenti lingue sono attualmente supportate con l'identificazione multilingue: en-AB, en-AU, en-GB, en-IE, en-IN, en-NZ, en-US, en-WL, en-ZA, es-ES, es-US, fr-CA, fr-FR, zh-CN, zh-TW, pt-BR, pt-PT, de-CH, de-DE, AF-ZA, ar-AE, da-DK, he-IL, hi-in, ID-ID, Fa-IR, it-IT, ja-JP, ko-KR, MS-MY, fr-IT, it-IT, Te-in, Th-TH, tr-TR
Multi-language le trascrizioni forniscono un riepilogo delle lingue rilevate e del tempo totale in cui ciascuna lingua viene parlata nei media. Ecco un esempio:
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
Miglioramento della precisione dell'identificazione della lingua
Con l'identificazione della lingua, hai la possibilità di includere un elenco di lingue che ritieni possano essere presenti nei tuoi contenuti multimediali. L'inclusione delle opzioni di lingua (LanguageOptions) consente di Amazon Transcribe utilizzare solo le lingue specificate per abbinare l'audio alla lingua corretta, il che può velocizzare l'identificazione della lingua e migliorare la precisione associata all'assegnazione del dialetto linguistico corretto.
Se scegli di includere i codici di lingua, devi includerne almeno due. Non c'è limite al numero di codici di lingua che puoi includere, ma ti consigliamo di utilizzarne da due a cinque per un'efficienza e una precisione ottimali.
Nota
Se includi codici di lingua nella richiesta e nessuno dei codici di lingua forniti corrisponde alla lingua o alle lingue identificate nell'audio, Amazon Transcribe seleziona la lingua più simile tra i codici di lingua specificati. Quindi produce una trascrizione in quella lingua. Ad esempio, se i file multimediali sono in inglese americano (en-US) e fornisci Amazon Transcribe i codici di lingua zh-CN fr-FRde-DE, ed Amazon Transcribe è probabile che abbini i file multimediali al tedesco (de-DE) e produca una German-language trascrizione. La mancata corrispondenza dei codici linguistici e delle lingue parlate può comportare una trascrizione imprecisa, pertanto consigliamo cautela nell'includere i codici di lingua.
Combinare l'identificazione linguistica con altre Amazon Transcribe caratteristiche
È possibile utilizzare l'identificazione della lingua in batch in combinazione con qualsiasi altra funzionalità Amazon Transcribe
. Se si combina l'identificazione della lingua con altre funzionalità, si è limitati alle lingue supportate da tali funzionalità. Ad esempio, se utilizzi l'identificazione della lingua con la redazione dei contenuti, sei limitato all'inglese americano (en-US) o allo spagnolo degli Stati Uniti (es-US), poiché questa è l'unica lingua disponibile per la redazione. Per ulteriori informazioni, consulta Lingue supportate e funzionalità specifiche della lingua.
Importante
Se utilizzi l'identificazione automatica della lingua con la redazione dei contenuti abilitata e l'audio contiene lingue diverse dall'inglese americano (en-US) o dallo spagnolo degli Stati Uniti (es-US), nella trascrizione viene oscurato solo il contenuto in inglese americano o spagnolo degli Stati Uniti. Le altre lingue non possono essere redatte e non sono presenti avvertenze o errori di lavoro.
Modelli linguistici personalizzati, vocabolari personalizzati e filtri del vocabolario personalizzati
Se desideri aggiungere uno o più modelli linguistici personalizzati, vocabolari personalizzati o filtri del vocabolario personalizzati alla tua richiesta di identificazione della lingua, devi includere il parametro LanguageIdSettings. È quindi possibile specificare un codice di lingua con un modello linguistico personalizzato, un vocabolario personalizzato e un filtro del vocabolario personalizzato corrispondenti. Tieni presente che l'identificazione multilingue non supporta modelli linguistici personalizzati.
Si consiglia di includere le LanguageOptions quando si utilizzano le LanguageIdSettings per garantire che venga identificato il dialetto linguistico corretto. Ad esempio, se specificate un vocabolario en-US personalizzato, ma Amazon Transcribe stabilite che la lingua parlata nei file multimediali è quella parlataen-AU, il vocabolario personalizzato non viene applicato alla trascrizione. Se includi le LanguageOptions e specifichi en-US come unico dialetto della lingua inglese, il vocabolario personalizzato verrà applicato alla trascrizione.
Per alcuni esempi delle LanguageIdSettings in una richiesta, consulta l'Opzione 2 nell’AWS CLI e i pannelli a discesa degli SDL AWS nella sezione Utilizzo dell’identificazione della lingua con trascrizione in batch.
Utilizzo dell’identificazione della lingua con trascrizione in batch
Puoi utilizzare l'identificazione automatica della lingua in un processo di trascrizione in batch utilizzando la AWS Management Console, l’AWS CLI o gli SDK AWS ; per alcuni esempi, consulta quanto segue:
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo.
-
Nel pannello Impostazioni processo, trova la sezione Impostazioni della lingua e seleziona Identificazione automatica della lingua o Identificazione automatica multilingue.
Hai la possibilità di selezionare le opzioni multilingue (dal menu a discesa Seleziona lingue) se conosci le lingue presenti nel tuo file audio. Fornire opzioni di lingua può migliorare la precisione, ma non è obbligatorio.
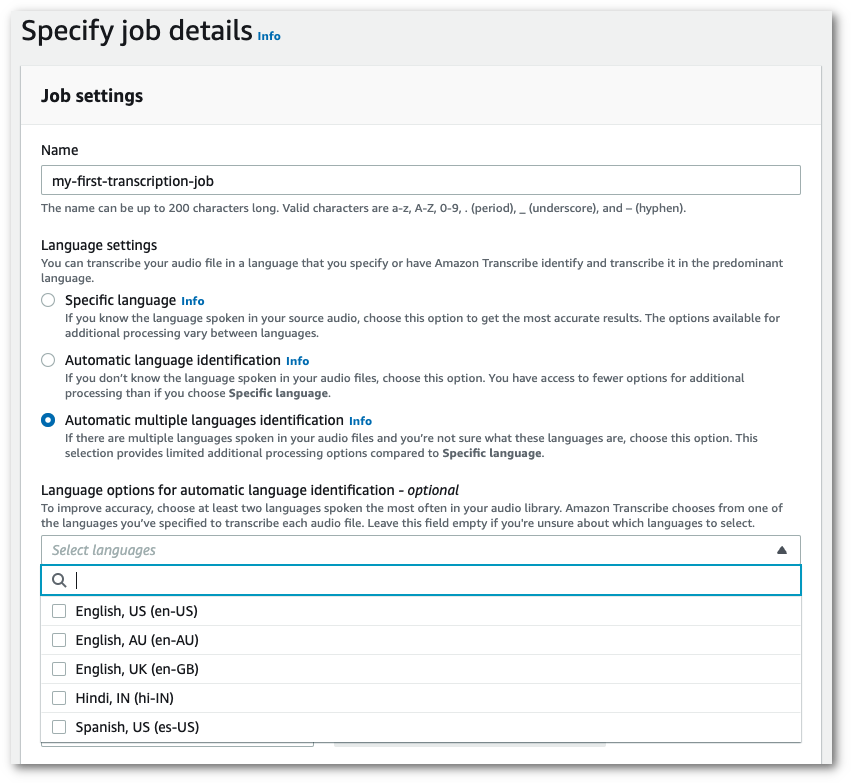
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
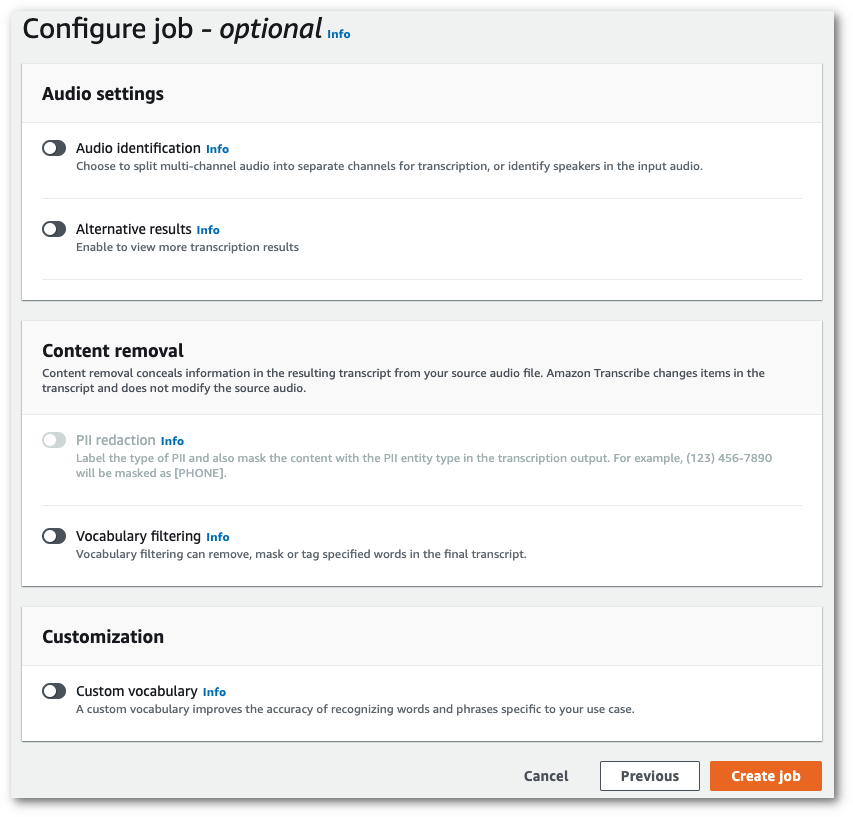
-
Seleziona Crea processo per eseguire il processo di trascrizione.
Questo esempio utilizza il comando inizia-processo-trascrizioneIdentifyLanguage. Per ulteriori informazioni, consultare StartTranscriptionJob e LanguageIdSettings.
Opzione 1: senza il parametro language-id-settings. Utilizza questa opzione se nella richiesta non includi un modello linguistico personalizzato, un vocabolario personalizzato o un filtro di vocabolario personalizzato. Le language-options sono facoltative, ma consigliate.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
Opzione 2: con il parametro language-id-settings. Utilizza questa opzione se nella richiesta includi un modello linguistico personalizzato, un vocabolario personalizzato o un filtro di vocabolario personalizzato.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
Ecco un altro esempio che utilizza il comando avvia processo trascrizione
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
Il file my-first-language-id-job.json contiene il seguente corpo della richiesta.
Opzione 1: senza il parametro LanguageIdSettings. Utilizza questa opzione se nella richiesta non includi un modello linguistico personalizzato, un vocabolario personalizzato o un filtro di vocabolario personalizzato. Le LanguageOptions sono facoltative, ma consigliate.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
Opzione 2: con il parametro LanguageIdSettings. Utilizza questa opzione se nella richiesta includi un modello linguistico personalizzato, un vocabolario personalizzato o un filtro di vocabolario personalizzato.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
Questo esempio utilizza il AWS SDK per Python (Boto3) per identificare la lingua del file utilizzando l'IdentifyLanguageargomento per il metodo start_transcription_job.StartTranscriptionJob e LanguageIdSettings.
Per ulteriori esempi di utilizzo degli AWS SDK, inclusi esempi relativi a funzionalità specifiche, scenari e interservizi, consulta il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDK
Opzione 1: senza il parametro LanguageIdSettings. Utilizza questa opzione se nella richiesta non includi un modello linguistico personalizzato, un vocabolario personalizzato o un filtro di vocabolario personalizzato. Le LanguageOptions sono facoltative, ma consigliate.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Opzione 2: con il parametro LanguageIdSettings. Utilizza questa opzione se nella richiesta includi un modello linguistico personalizzato, un vocabolario personalizzato o un filtro di vocabolario personalizzato.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
