Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Accodamento dei processi
Utilizzando l'accodamento dei processi, puoi inviare più richieste del processo di trascrizione di quante ne possano essere elaborate contemporaneamente. Senza l’accodamento dei processi, una volta raggiunta la quota di richieste simultanee consentite, è necessario attendere il completamento di una o più richieste prima di inviarne una nuova.
L'accodamento dei lavori è facoltativo sia per i lavori di trascrizione che per le richieste di lavoro di analisi post-chiamata.
Se abiliti l'accodamento dei lavori, Amazon Transcribe crea una coda che contiene tutte le richieste che superano il limite. Non appena una richiesta viene completata, una nuova richiesta viene estratta dalla coda ed elaborata. Le richieste in coda vengono elaborate in ordine FIFO (first-in-first-out).
Puoi aggiungere fino a 10.000 processi alla coda. Se si supera questo limite, si verificherà un errore LimitExceededConcurrentJobException. Per mantenere prestazioni ottimali, utilizza Amazon Transcribe solo fino al 90 percento della quota (un rapporto di larghezza di banda di 0,9) per elaborare i lavori in coda. Tieni presente che si tratta di valori predefiniti che possono essere aumentati su richiesta.
Suggerimento
È possibile trovare un elenco dei limiti e delle quote predefiniti per Amazon Transcribe le risorse nella Guida generale.AWS Alcune di queste impostazioni predefinite possono essere aumentate su richiesta.
Se abiliti l'accodamento dei processi ma non superi la quota per le richieste simultanee, tutte le richieste vengono elaborate contemporaneamente.
Abilitazione dell’accodamento dei processi
Puoi abilitare l'accodamento dei processi utilizzando la AWS Management Console, l’AWS CLI o gli SDK AWS ; vedi quanto segue per alcuni esempi; vedi quanto segue per esempi:
-
Accedi alla AWS Management Console
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo.
-
Nella casella Impostazioni processo, c'è un pannello di impostazioni aggiuntive. Se espandi questo pannello, puoi selezionare la casella Aggiungi alla coda dei processi per abilitare l'accodamento dei processi.
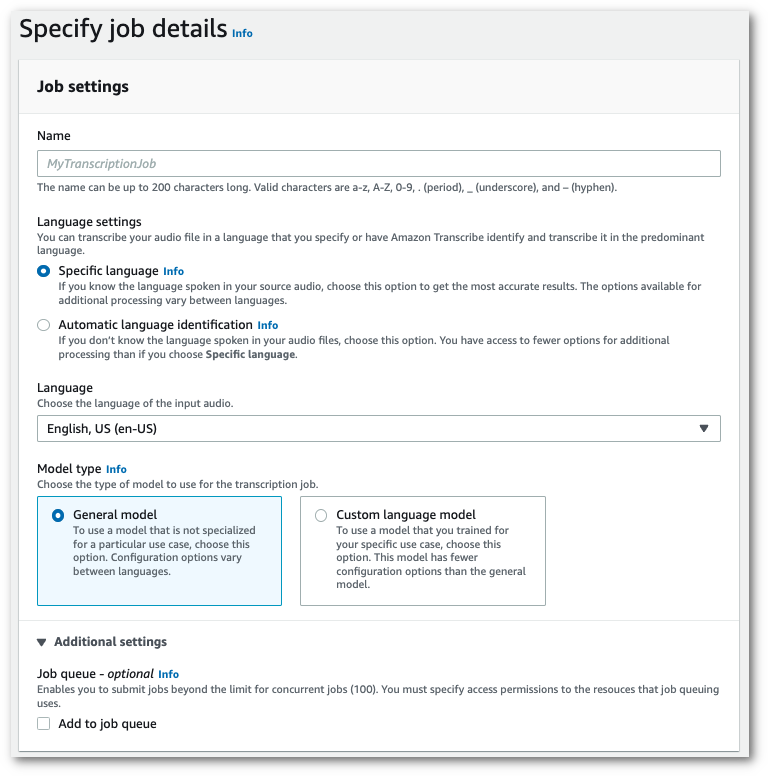
-
Compila tutti i campi che desideri includere nella pagina Specifica i dettagli del processo, quindi seleziona Avanti. Verrà visualizzata la pagina Configura processo - opzionale.
-
Seleziona Crea processo per eseguire il processo di trascrizione.
Questo esempio utilizza il comando avvia processo trascrizionejob-execution-settings con il sottoparametro AllowDeferredExecution. Tenere presente che quando si include AllowDeferredExecution nella richiesta, si dovrà includere anche DataAccessRoleArn.
Per ulteriori informazioni, consultare StartTranscriptionJob e JobExecutionSettings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --job-execution-settings AllowDeferredExecution=true,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole
Ecco un altro esempio che utilizza il comando avvia processo trascrizione
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-queueing-request.json
Il file my-first-queueing-request.json contiene il seguente corpo della richiesta.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "JobExecutionSettings": { "AllowDeferredExecution": true, "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" } }
Questo esempio utilizza AWS SDK per Python (Boto3) per abilitare l'accodamento dei lavori utilizzando l'AllowDeferredExecutionargomento per il metodo start_transcription_job.AllowDeferredExecution nella richiesta, si dovrà includere anche DataAccessRoleArn. Per ulteriori informazioni, consultare StartTranscriptionJob e JobExecutionSettings.
Per ulteriori esempi di utilizzo degli AWS SDK, inclusi esempi relativi a funzionalità specifiche, scenari e interservizi, consulta il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-queueing-request" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', JobExecutionSettings = { 'AllowDeferredExecution': True, 'DataAccessRoleArn': 'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
È possibile visualizzare lo stato di avanzamento di un lavoro in coda tramite o inviando una richiesta. AWS Management Console GetTranscriptionJob Quando un processo è in coda, lo Status è QUEUED. Lo stato cambia in IN_PROGRESS quando il processo viene avviato, e quindi cambia in COMPLETED o FAILED al termine dell'elaborazione.
