Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Avvio di una trascrizione di analisi post-chiamata
Prima di iniziare una trascrizione analitica post-chiamata, devi creare tutte le categorie Amazon Transcribe a cui desideri che corrispondano nell'audio.
Nota
Le trascrizioni di analisi delle chiamate non possono essere corrisposte retroattivamente a nuove categorie. Solo le categorie create prima di iniziare una trascrizione di analisi delle chiamate possono essere applicate a tale output di trascrizione.
Se hai creato una o più categorie e l'audio corrisponde a tutte le regole all'interno di almeno una delle categorie, Amazon Transcribe contrassegna l'output con la categoria corrispondente. Se scegli di non utilizzare le categorie o se l'audio non corrisponde alle regole specificate nelle categorie, la trascrizione non viene contrassegnata.
Per avviare una trascrizione analitica post-chiamata, puoi utilizzare la Console di gestione AWS, l’AWS CLI, o gli SDK AWS ; vedi quanto segue per alcuni esempi:
Utilizza la procedura seguente per avviare un processo di analisi post-chiamata. Le chiamate che corrispondono a tutte le caratteristiche definite da una categoria vengono etichettate con tale categoria.
-
Nel riquadro di navigazione, sotto Amazon Transcribe Call Analytics, scegli Call analytics jobs.
-
Scegli Crea processo.
-
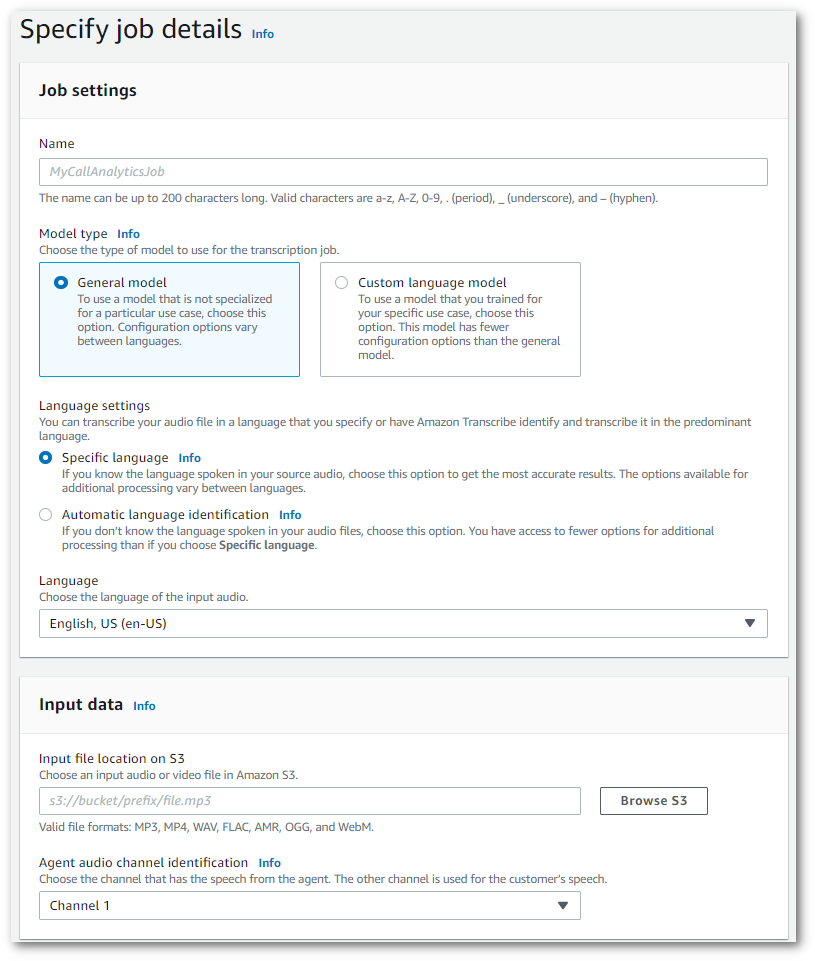
Nella pagina Specifica i dettagli del processo, fornisci informazioni sul tuo processo di analisi delle chiamate, inclusa la posizione dei dati di input.
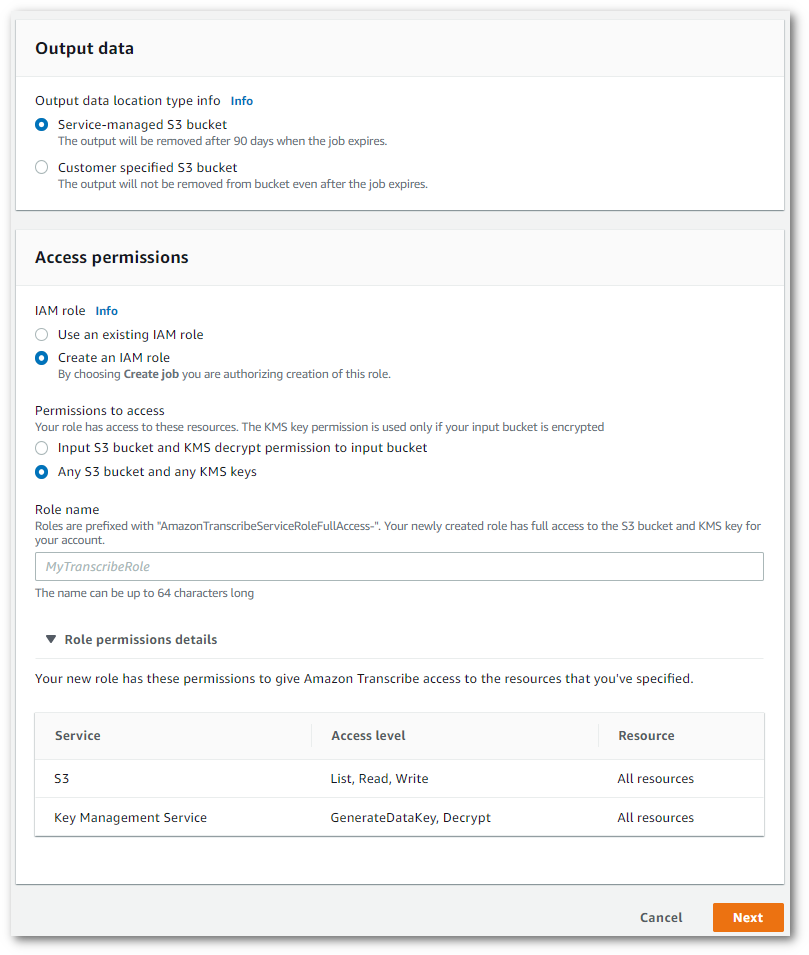
Specificate la Amazon S3 posizione desiderata dei dati di output e il IAM ruolo da utilizzare.
-
Scegli Next (Successivo).
-
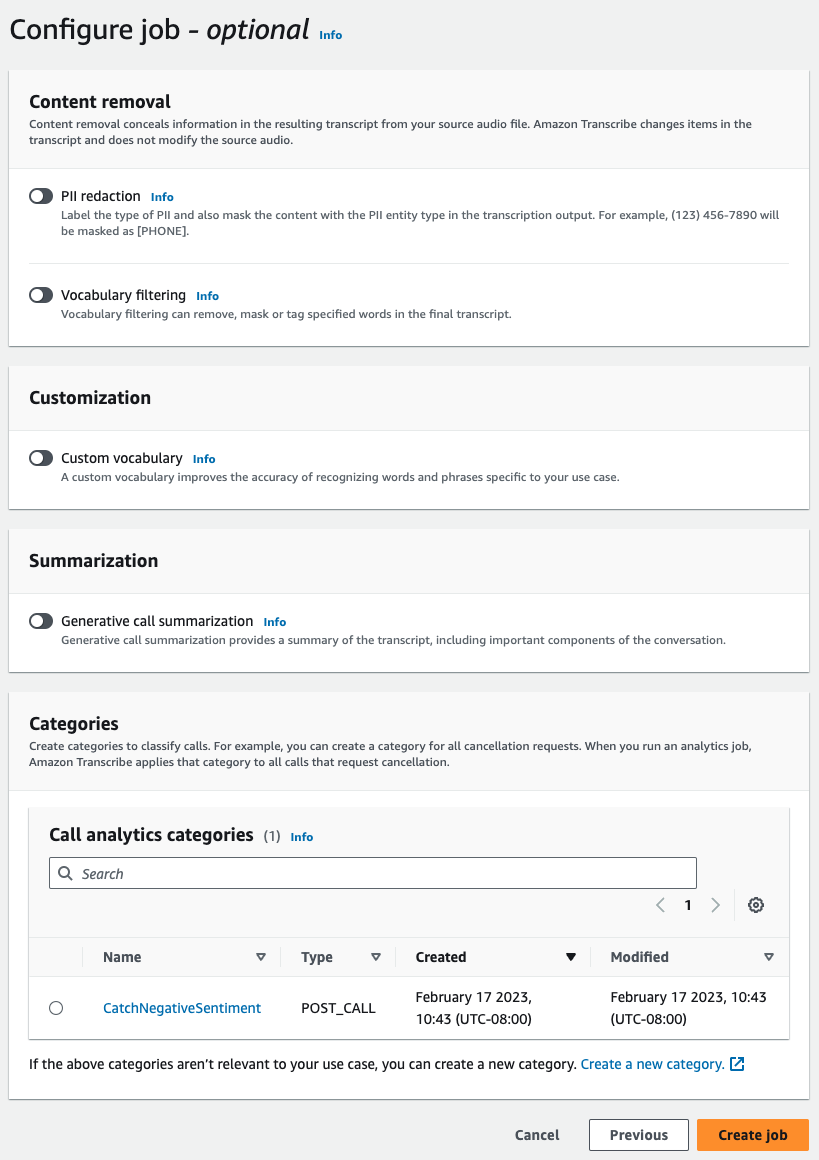
Per Configura processo, attiva tutte le funzionalità opzionali che desideri includere nel tuo processo di analisi delle chiamate. Se hai già creato delle categorie, queste vengono visualizzate nel pannello Categorie e vengono applicate automaticamente al tuo processo di analisi delle chiamate.
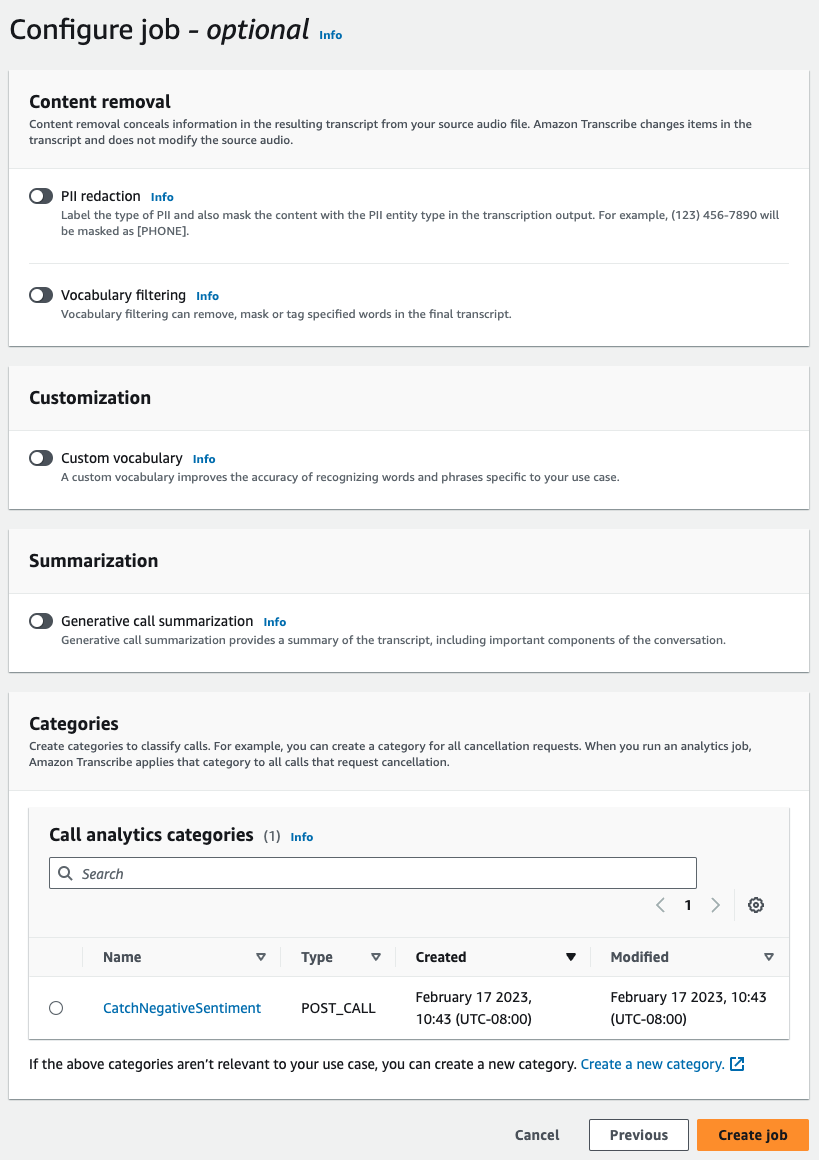
-
Scegli Crea processo.
Questo esempio utilizza il comando avvia processo analisi chiamatechannel-definitions. Per ulteriori informazioni, consultare StartCallAnalyticsJob e ChannelDefinition.
aws transcribe start-call-analytics-job \ --regionus-west-2\ --call-analytics-job-namemy-first-call-analytics-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-location s3://amzn-s3-demo-bucket/my-output-files/ \ --data-access-role-arn arn:aws:iam::111122223333:role/ExampleRole\ --channel-definitions ChannelId=0,ParticipantRole=AGENTChannelId=1,ParticipantRole=CUSTOMER
Ecco un altro esempio che utilizza il comando avvia processo analisi chiamate
aws transcribe start-call-analytics-job \ --regionus-west-2\ --cli-input-json file://filepath/my-call-analytics-job.json
Il file my-call-analytics-job.json contiene il seguente corpo della richiesta.
{ "CallAnalyticsJobName": "my-first-call-analytics-job", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputLocation": "s3://amzn-s3-demo-bucket/my-output-files/", "ChannelDefinitions": [ { "ChannelId": 0, "ParticipantRole": "AGENT" }, { "ChannelId": 1, "ParticipantRole": "CUSTOMER" } ] }
Questo esempio utilizza AWS SDK per Python (Boto3) per avviare un processo di Call Analytics utilizzando il metodo start_call_analytics_job.StartCallAnalyticsJob e ChannelDefinition.
Per ulteriori esempi di utilizzo degli AWS SDK, inclusi esempi relativi a funzionalità specifiche, scenari e interservizi, consulta il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-call-analytics-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" output_location = "s3://amzn-s3-demo-bucket/my-output-files/" data_access_role = "arn:aws:iam::111122223333:role/ExampleRole" transcribe.start_call_analytics_job( CallAnalyticsJobName = job_name, Media = { 'MediaFileUri': job_uri }, DataAccessRoleArn = data_access_role, OutputLocation = output_location, ChannelDefinitions = [ { 'ChannelId': 0, 'ParticipantRole': 'AGENT' }, { 'ChannelId': 1, 'ParticipantRole': 'CUSTOMER' } ] ) while True: status = transcribe.get_call_analytics_job(CallAnalyticsJobName = job_name) if status['CallAnalyticsJob']['CallAnalyticsJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
