このページの改善にご協力ください
このユーザーガイドに貢献するには、すべてのページの右側のペインにある「GitHub でこのページを編集する」リンクを選択してください。
Amazon EKS での Amazon Application Recovery Controller (ARC) のゾーンシフトの詳細
Kubernetes には、アベイラビリティーゾーン (AZ) のヘルスの低下や障害などのイベントに対するアプリケーションの回復力を高めるネイティブ機能があります。Amazon EKS クラスターでワークロードを実行する場合、Amazon Application Recovery Controller (ARC) のゾーンシフトまたはゾーンオートシフトを使用して、アプリケーション環境の耐障害性とアプリケーション復旧をさらに改善できます。ARC ゾーンシフトは、ゾーンシフトが期限切れになるまで、またはキャンセルするまで、障害のある AZ からリソースのトラフィックを移動できる一時的な手段として設計されています。必要に応じてゾーンシフトを拡張できます。
EKS クラスターのゾーンシフトを開始することも、ゾーンオートシフトを有効にして AWS がトラフィックをシフトできるようにすることもできます。このシフトは、正常な AZ のワーカーノードで実行されているポッドのネットワークエンドポイントのみを使用するようにクラスター内の東西ネットワークトラフィックのフローを更新します。さらに、EKS クラスター内のアプリケーションの入力トラフィックを処理する ALB または NLB は、トラフィックを正常な AZ 内のターゲットに自動的にルーティングします。可用性を最大限に高めることを目標にしているお客様にとって、AZ で障害が発生した場合は、障害のある AZ が回復するまでその AZ からすべてのトラフィックを移動できることが重要です。そのためには、ARC ゾーンシフト で ALB または NLB を有効にすることもできます。
ポッド間の東西ネットワークトラフィックフローを理解する
次の図は、2 つのワークロードの例である Orders と Products を示しています。この例の目的は、さまざまな AZ でワークロードとポッドが通信する方法を示します。
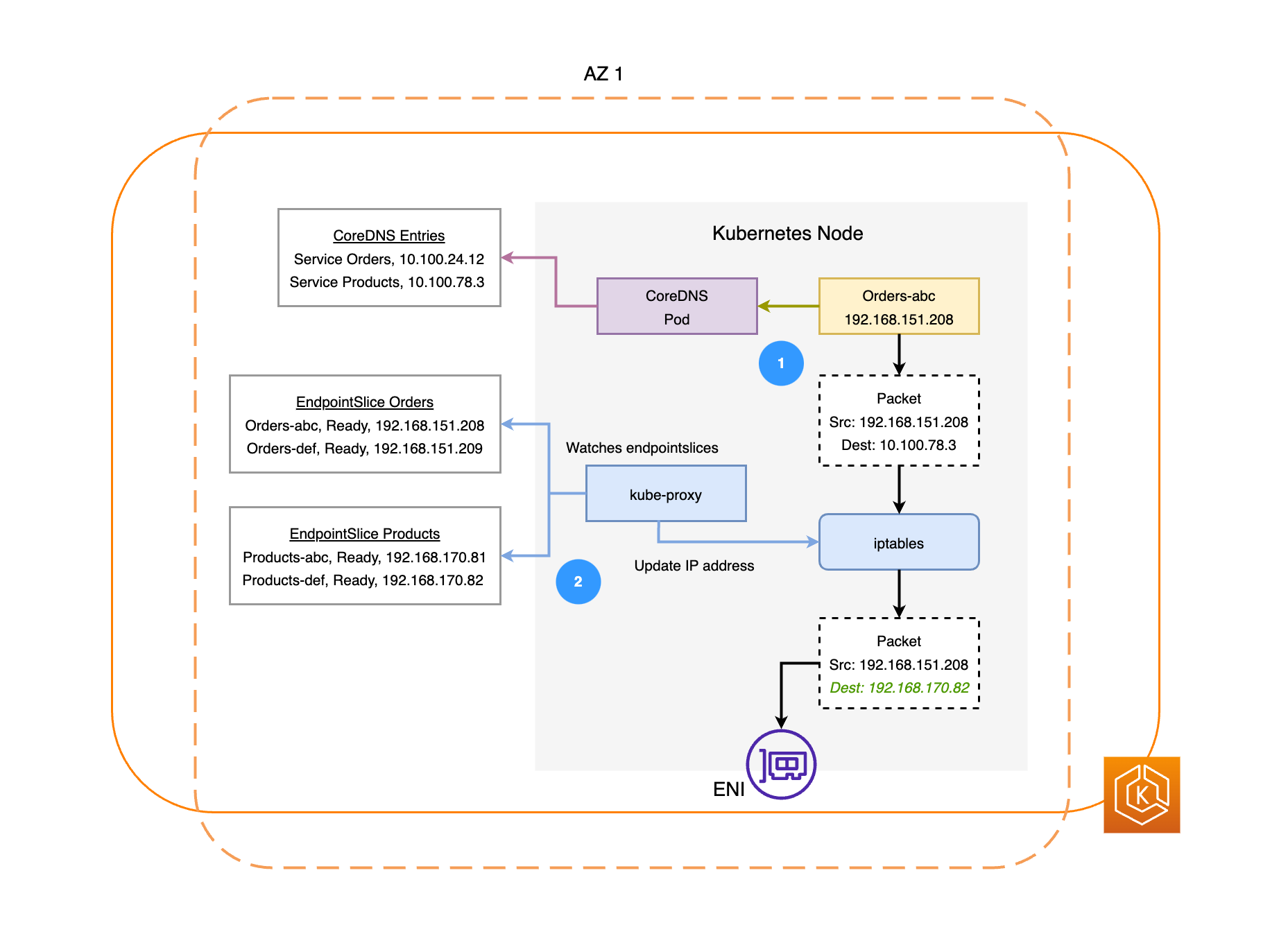
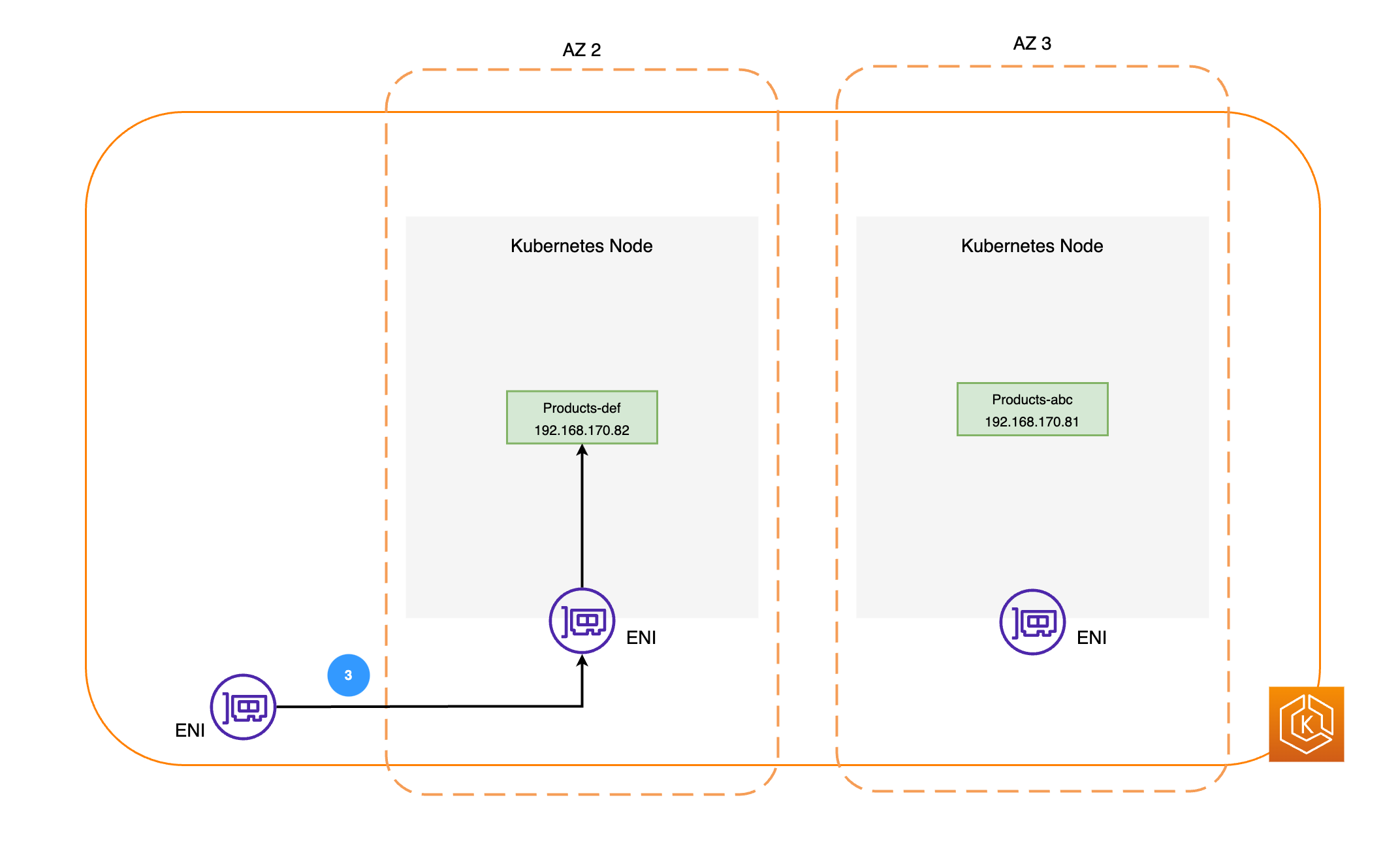
-
Orders が Products と通信するには、まず Orders が送信先のサービスの DNS 名を解決する必要があります。Orders は CoreDNS と通信して、そのサービスの仮想 IP アドレス (クラスター IP) を取得します。Orders が Products のサービス名を解決すると、そのターゲット IP アドレスにトラフィックが送信されます。
-
kube-proxy はクラスター内のすべてのノードで実行され、サービス用の EndpointSlices
を継続的に監視します。サービスが作成されると、EndpointSlice コントローラーによってバックグラウンドで EndpointSlice が作成され、管理されます。各 EndpointSlice には、ポッドアドレスのサブセットと、それらが実行されているノードを含むエンドポイントのリストまたは表があります。kube-proxy は、ノードで iptablesを使用して、これらのポッドエンドポイントごとにルーティングルールを設定します。また、kube-proxy は、基本的なロードバランシングも行います。サービスのクラスターの IP アドレス宛てのトラフィックを、ポッドの IP アドレスに直接送信するようリダイレクトします。kube-proxy は、送信接続の送信先 IP アドレスを書き換えることでこれを行います。 -
次に、前の図に示されているように、ネットワークパケットは、各ノードの ENI を使用して AZ 2 の Products ポッドに送信されます。
Amazon EKS での ARC ゾーンシフトについて
環境に AZ の障害がある場合は、EKS クラスター環境のゾーンシフトを開始できます。または、ゾーンオートシフトを使用して AWS がトラフィックのシフトを管理できます。ゾーンオートシフトでは、AWS は AZ の全体的なヘルスをモニタリングし、クラスター環境内の障害のある AZ からトラフィックを自動的に移動することで、潜在的な AZ 障害に対応します。
ARC で Amazon EKS クラスターのゾーンシフトを有効にすると、ARC コンソール、AWS CLI、またはゾーンシフト API やゾーンオートシフト API を使用して、ゾーンシフトをトリガーしたり、ゾーンオートシフトを有効にしたりできます。EKS ゾーンシフト中、次のことが自動的に行われます。
-
影響を受ける AZ 内のすべてのノードが遮断されます。これにより、Kubernetes スケジューラーが異常な AZ のノードに新しいポッドをスケジューリングできなくなります。
-
マネージドノードグループを使用している場合、アベイラビリティーゾーンの再分散は停止され、Auto Scaling グループが更新され、新しい EKS データプレーンノードが正常な AZ でのみ起動されるようにします。
-
異常な AZ のノードは終了されず、ポッドはこれらのノードから削除されません。これは、ゾーンシフトの有効期限が切れたりキャンセルされたりしたときに、トラフィックがフル容量で AZ に安全に戻ることができるようにするためです。
-
EndpointSlice コントローラーは、障害のある AZ 内のすべてのポッドエンドポイントを検索し、関連する EndpointSlices から削除します。これにより、正常な AZ のポッドエンドポイントのみがネットワークトラフィックの受信対象になります。ゾーンシフトがキャンセルまたは期限切れになると、EndpointSlice コントローラーは EndpointSlices を更新して、復元された AZ にエンドポイントを含めます。
以下の図は、EKS ゾーンシフトによって、クラスター環境で正常なポッドエンドポイントのみがターゲットにされる方法についての大まかな概要を示しています。
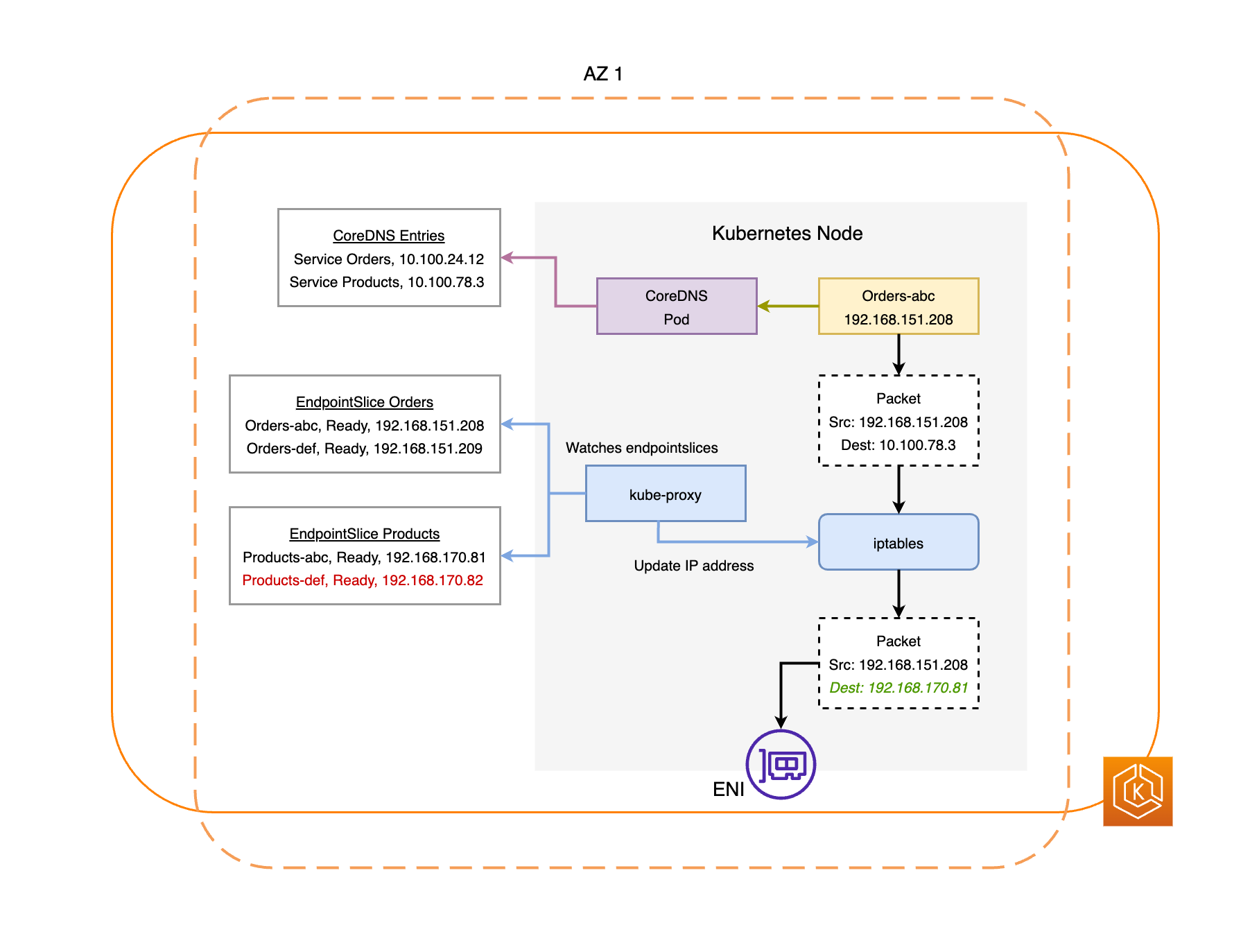
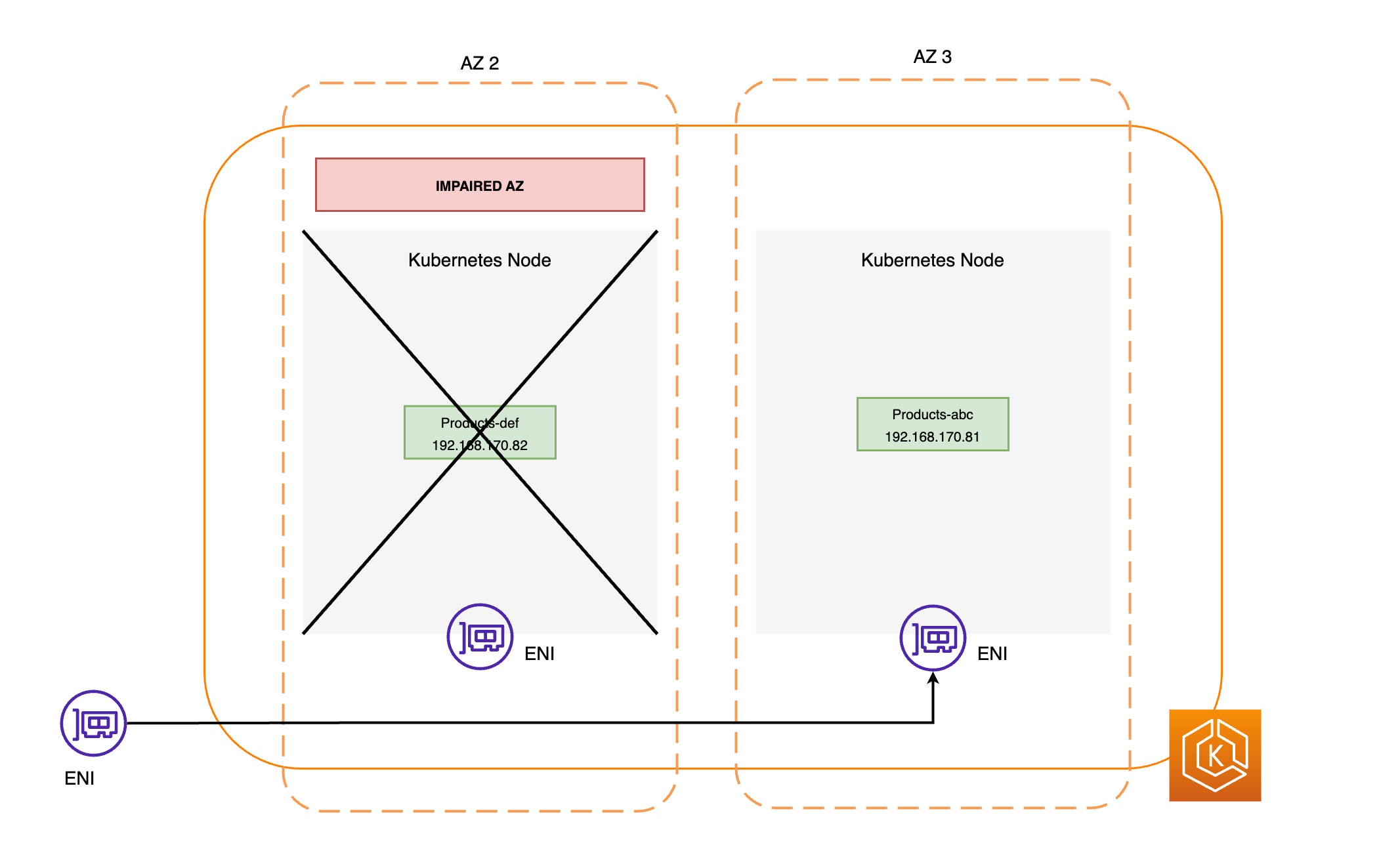
EKS ゾーンシフトの要件
ゾーンシフトを EKS で正常に機能させるには、事前に AZ の障害に対する回復性を実現できるようにクラスター環境を設定する必要があります。以下は、回復性を確保するのに役立つ設定オプションのリストです。
-
複数の AZ にクラスターのワーカーノードをプロビジョニングする
-
1 つの AZ を削除しても対応できる十分なコンピューティング容量をプロビジョニングする
-
CoreDNS を含むポッドをすべての AZ でプリスケールする
-
すべての AZ に複数のポッドレプリカを分散して、単一の AZ から移動した場合でも十分な容量を確保できるようにする
-
相互依存ポッドまたは関連ポッドを同じ AZ に配置する
-
AZ からのゾーンシフトを手動で開始することで、1 つの AZ がない状態でもクラスター環境が期待どおりに動作することをテストします。または、ゾーンオートシフトを有効にし、オートシフトの練習運用に頼ることもできます。手動または練習のゾーンシフトによるテストは、EKS でゾーンシフトを機能させるために必須ではありませんが、強くお勧めします。
複数のアベイラビリティーゾーンに EKS ワーカーノードをプロビジョニングする
AWS リージョンには、アベイラビリティーゾーン (AZ) と呼ばれる物理データセンターがある複数の別々の場所があります。AZ は、リージョン全体に影響を与える可能性のある同時障害を回避するために、互いに物理的に離れた場所に配置されています。EKS クラスターをプロビジョニングする場合は、リージョン内の複数の AZ にワーカーノードをデプロイすることをお勧めします。これにより、クラスター環境は 1 つの AZ の障害に対する回復力が向上し、他の AZ で実行されるアプリケーションの高可用性を維持できます。影響を受ける AZ からゾーンシフトを開始すると、EKS 環境のクラスター内ネットワークは自動的に更新され、正常な AZ のみを使用するようになり、クラスターの高可用性を維持するのに役立ちます。
EKS 環境にマルチ AZ 設定を実施することで、システム全体の信頼性が向上します。ただし、マルチ AZ 環境は、アプリケーションデータの転送と処理方法に影響を与え、環境のネットワーク料金に影響します。特に、頻繁な egress クロスゾーントラフィック (AZ 間に分散されたトラフィック) は、ネットワーク関連のコストに大きな影響を与える可能性があります。さまざまな戦略を適用して、EKS クラスター内のポッド間のクロスゾーントラフィックの量を制御し、関連するコストを削減できます。高可用性 EKS 環境を実行するときにネットワークコストを最適化する方法の詳細については、このベストプラクティスガイド
次の図は、3 つの正常な AZ を持つ高可用性 EKS 環境を示しています。
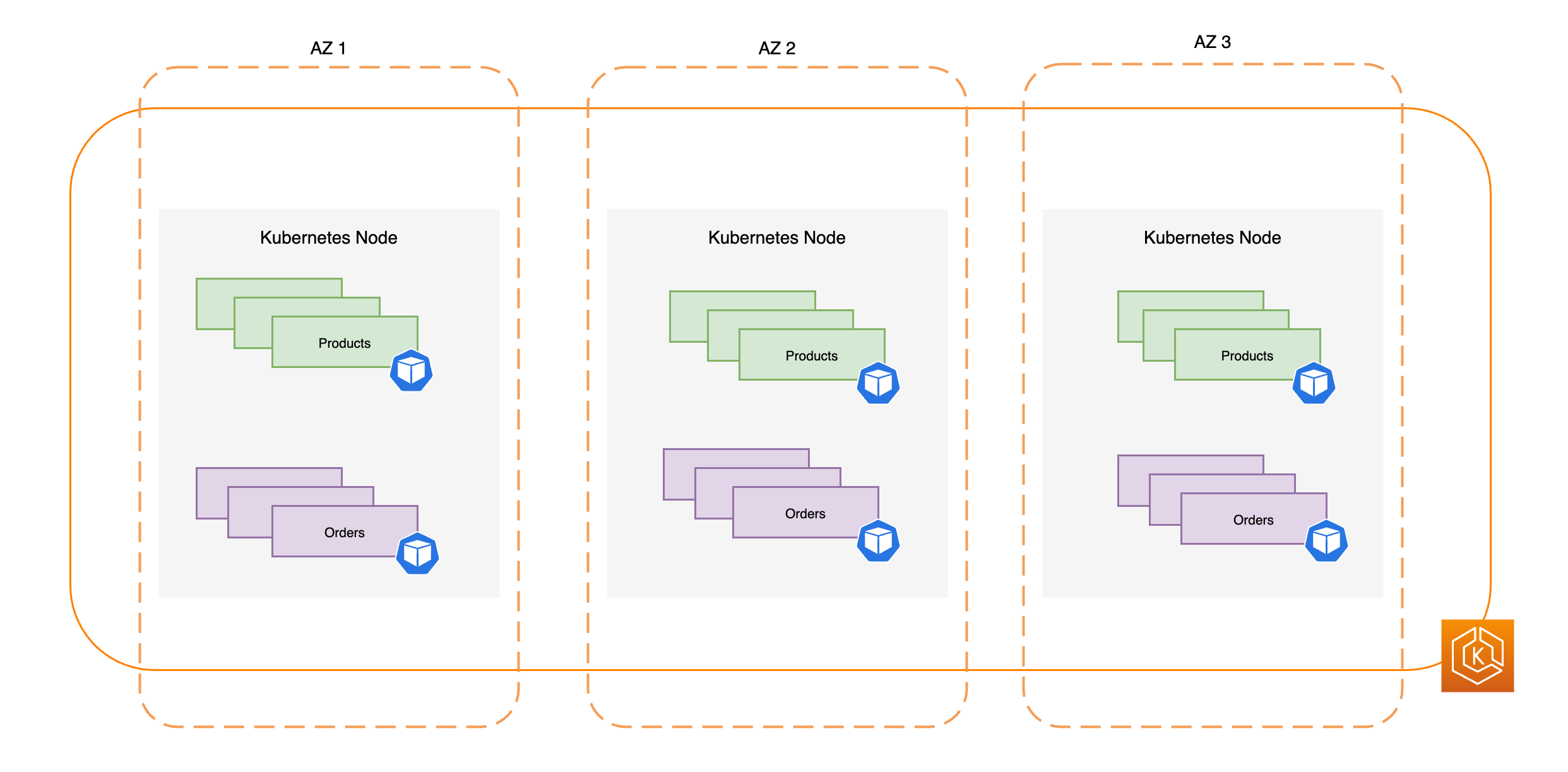
次の図は、3 つの AZ を持つ EKS 環境が AZ の障害に対して回復力があり、他の 2 つの正常な AZ が残っているために高可用性を維持する方法を示しています。
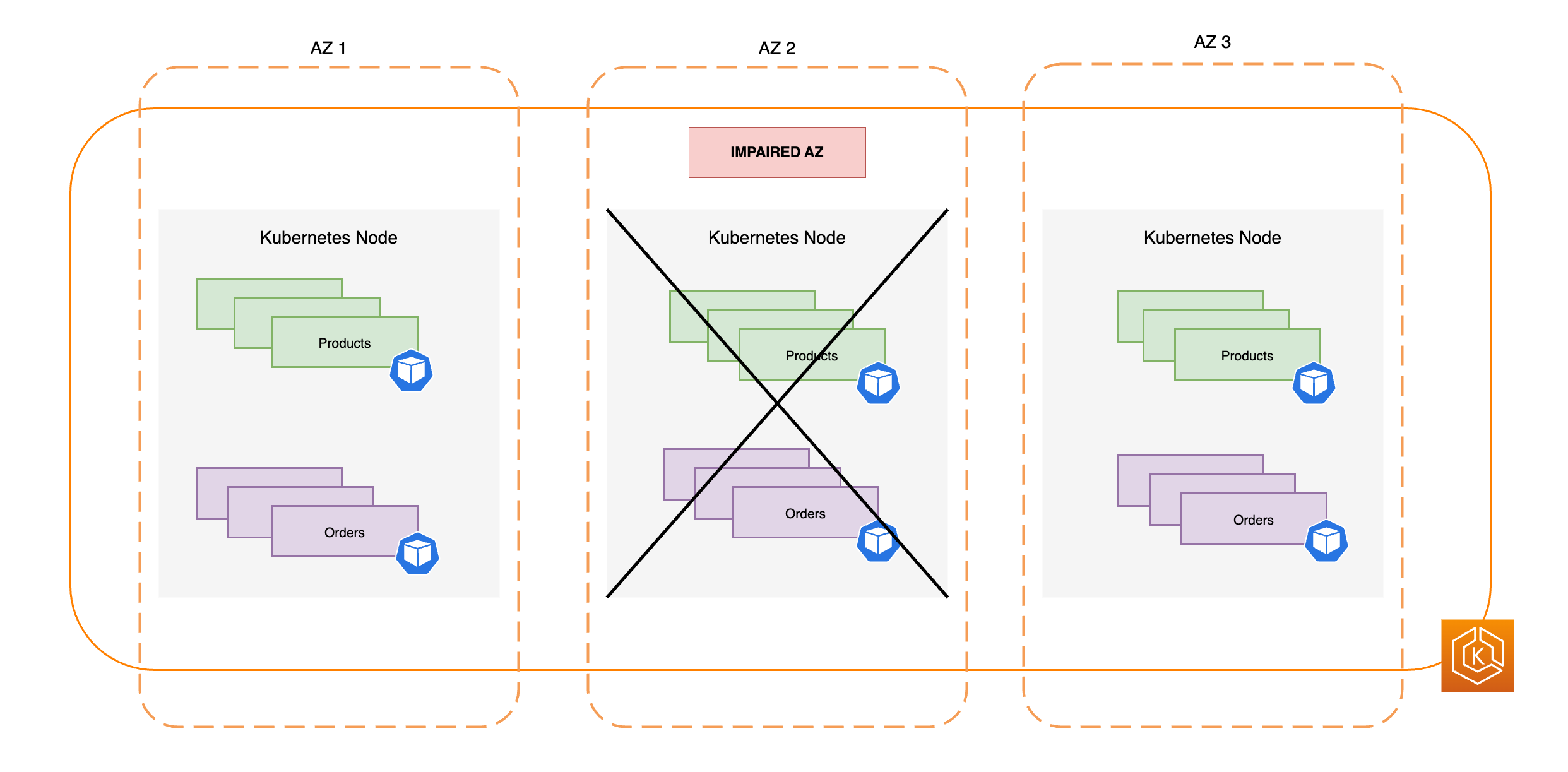
1 つのアベイラビリティーゾーンの削除に耐えるのに十分なコンピューティング容量をプロビジョニングする
EKS データプレーンでコンピューティングインフラストラクチャのリソース使用率とコストを最適化するには、コンピューティング容量をワークロード要件に合わせることをお勧めします。ただし、すべてのワーカーノードがフル容量である場合、新しいポッドをスケジュールする前に、新しいワーカーノードを EKS データプレーンに追加する必要があります。重要なワークロードを実行する場合、通常、負荷の急増やノードのヘルスの問題などのシナリオに対処するために、冗長な容量をオンラインで運用することをお勧めします。ゾーンシフトを使用する予定がある場合は、障害が発生したときに AZ 全体の容量を削除することになります。そのため、いずれか 1 つの AZ がオフラインになっても負荷を十分に処理できるよう、冗長なコンピューティング容量を調整する必要があります。
コンピューティングリソースをスケールすると、EKS データプレーンに新しいノードを追加するプロセスには一定の時間がかかります。これは、特にゾーン障害が発生した場合に、アプリケーションのリアルタイムのパフォーマンスと可用性に影響を与える可能性があります。EKS 環境は、エンドユーザーやクライアントのエクスペリエンスが低下させることなく、1 つの AZ を失った場合の負荷を吸収できる必要があります。これは、新しいポッドが必要な時点からワーカーノードで実際にスケジュールされる時点までの遅延を最小限に抑えるか、排除することを意味します。
さらに、ゾーンの障害が発生した場合は、コンピューティング容量の制約に直面するリスクを軽減する必要があります。これにより、新しく必要なノードが正常な AZ の EKS データプレーンに追加されるのを防ぐことができます。
これらの潜在的な悪影響のリスクを軽減するために、各 AZ の一部のワーカーノードでコンピューティングキャパシティを過剰にプロビジョニングすることをお勧めします。これにより、Kubernetes スケジューラには、新しいポッド配置に使用できる既存の容量が確保されます。これは、環境内でいずれか 1 つの AZ を失った場合に特に重要です。
複数のポッドレプリカを実行してアベイラビリティーゾーンに分散する
Kubernetes を使用すると、1 つのアプリケーションの複数のインスタンス (ポッドレプリカ) を実行してワークロードを事前スケールできます。アプリケーションに対して複数のポッドレプリカを実行すると、単一障害点がなくなり、単一のレプリカにかかるリソース負荷が軽減されることで、全体的なパフォーマンスが向上します。ただし、アプリケーションの高可用性と耐障害性向上を実現するには、トポロジドメインとも呼ばれる異なる障害ドメインにまたがってアプリケーションの複数のレプリカを分散させて実行することをお勧めします。このシナリオの障害ドメインはアベイラビリティーゾーンです。トポロジの分散制約
下図は、すべての AZ が正常である場合の、東西トラフィックフローが発生している EKS 環境を示しています。
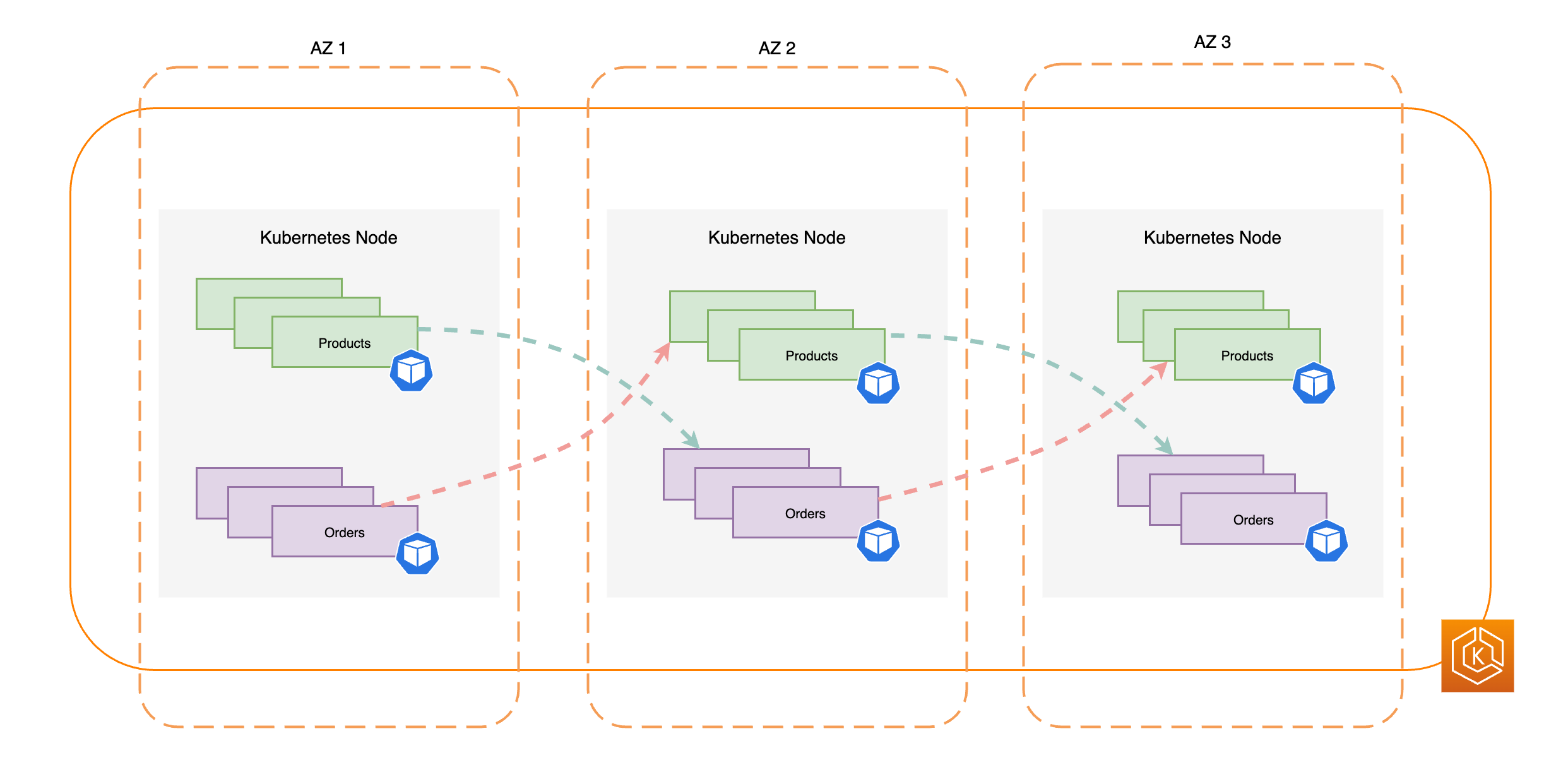
次の図は、1 つの AZ で障害が発生し、ゾーンシフトを開始した、東西トラフィックフローが発生している EKS 環境を示しています。
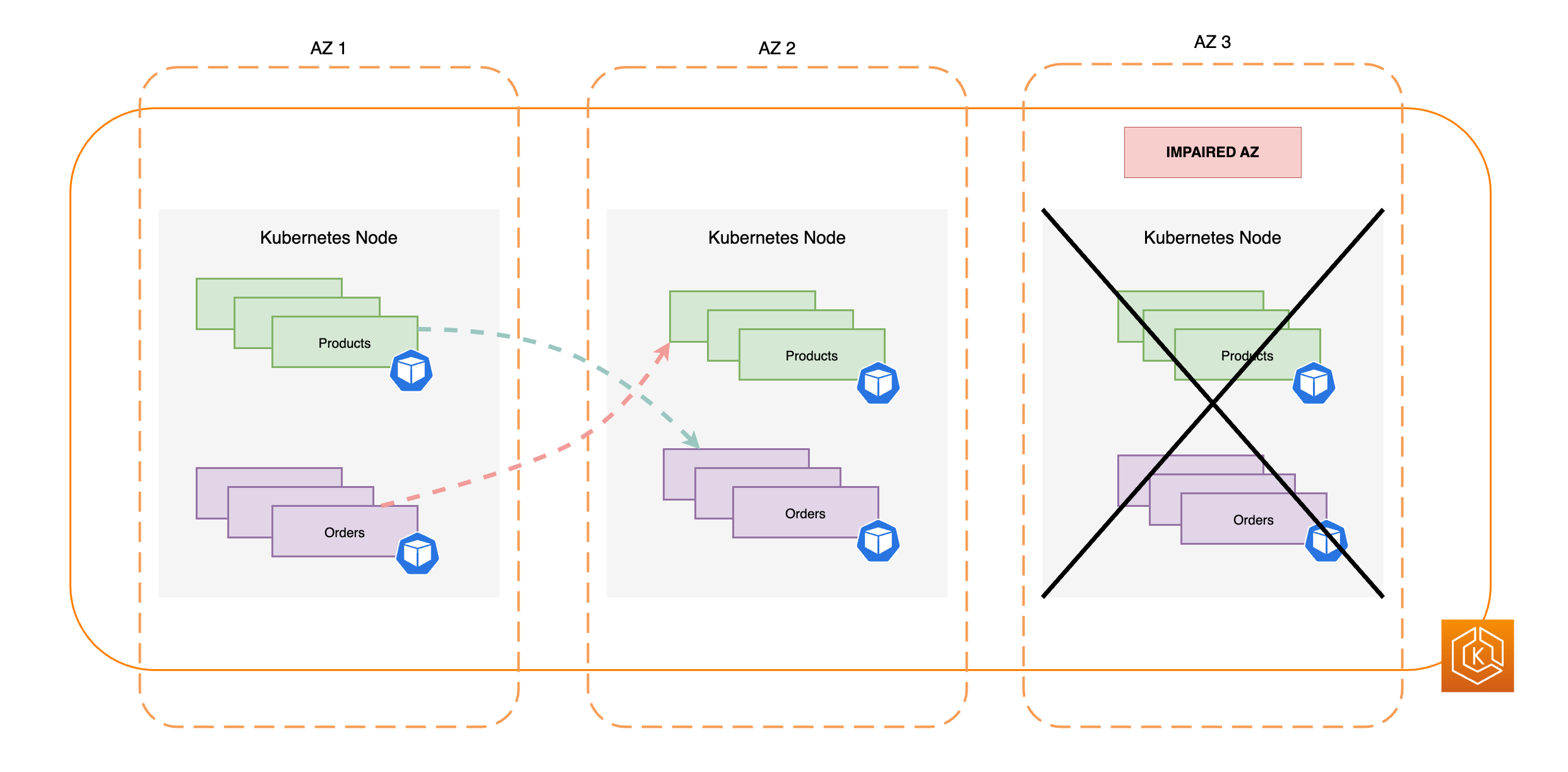
次のコードスニペットは、Kubernetes で複数のレプリカを使用してワークロードをセットアップする方法の例です。
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
最も重要なのは、DNS サーバーソフトウェア (CoreDNS/kube-dns) の複数のレプリカを実行し、それらがデフォルトで設定されていない場合は、同様のトポロジ分散制約を適用することです。これにより、単一の AZ 障害がある場合に、正常な AZ に十分な DNS ポッドがあり、クラスター内の他の通信ポッドのサービス検出リクエストを引き続き処理できます。CoreDNS EKS アドオンには、複数の AZ に使用可能なノードがある場合に、CoreDNS ポッドがクラスターのアベイラビリティーゾーンに分散されるようにするデフォルト設定があります。必要に応じて、これらのデフォルト設定を独自のカスタム設定に置き換えることもできます。
Helm で CoreDNSreplicaCount を更新して、各 AZ に十分なレプリカを確保できます。さらに、これらのレプリカがクラスター環境内の異なる AZ に分散されるようにするには、同じ values.yaml ファイルで topologySpreadConstraints プロパティを更新してください。次のコードスニペットは、これを行うために CoreDNS を設定する方法を示しています。
CoreDNS Helm の values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
AZ の障害が発生した場合は、CoreDNS の自動スケーリングシステムを使用して CoreDNS ポッドの負荷の増加を吸収できます。必要な DNS インスタンスの数は、クラスターで実行されているワークロードの数によって異なります。CoreDNS は CPU バインドであり、Horizontal Pod Autoscaler (HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
また、EKS は、CoreDNS の EKS アドオンバージョンで CoreDNS デプロイの自動スケーリングを管理できます。この CoreDNS オートスケーラーは、ノード数や CPU コア数など、クラスターの状態を継続的にモニタリングします。この情報に基づいて、コントローラーは EKS クラスター内の CoreDNS デプロイのレプリカ数を動的に調整します。
CoreDNS EKS アドオンで自動スケーリング設定を有効にするには、次の構成設定を使用します。
{ "autoScaling": { "enabled": true } }
NodeLocal DNS
同じアベイラビリティーゾーンで相互依存ポッドを同じ場所に配置する
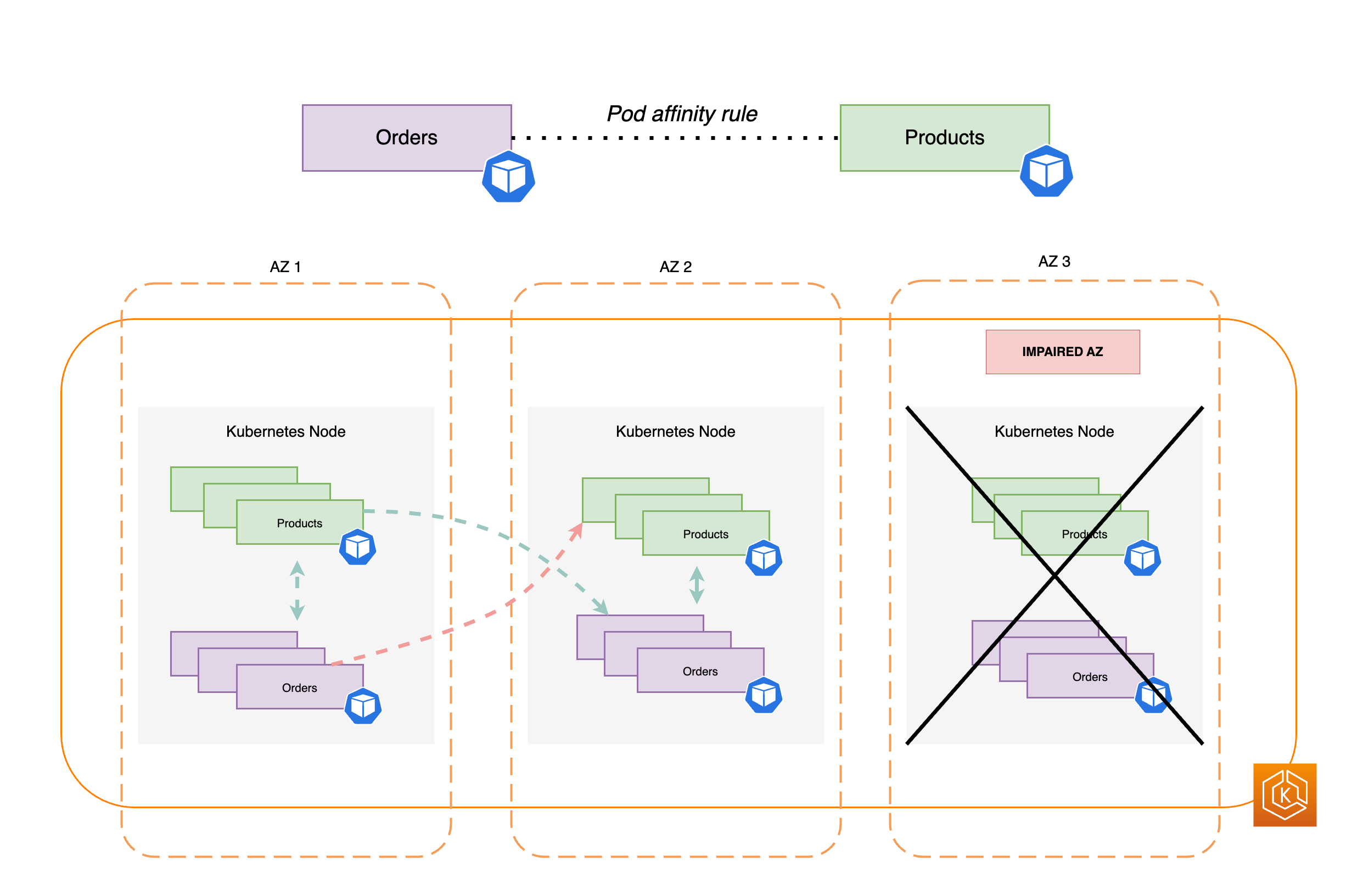
通常、アプリケーションには、エンドツーエンドのプロセスを正常に完了するために相互に通信する必要がある、個別のワークロードがあります。これらの異なるアプリケーションが異なる AZ に分散しており、同じ AZ に配置されていない場合、単一の AZ の障害がエンドツーエンドのプロセスに影響を与える可能性があります。例えば、アプリケーション A が AZ 1 と AZ 2 に複数のレプリカを持ち、アプリケーション B が AZ 3 にすべてのレプリカを持つ場合、AZ 3 が失われると、アプリケーション A とアプリケーション B の 2 つのワークロード間のエンドツーエンドのプロセスに影響が生じます。トポロジの分散制約とポッドのアフィニティを組み合わせると、すべての AZ にポッドを分散することで、アプリケーションの回復力を高めることができます。さらに、これにより、特定のポッドがコロケーションされるようにするためのポッド間の関係が設定されます。
ポッドのアフィニティのルール
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
次の図は、ポッドアフィニティルールを使用して同じノードにコロケーションされた複数のポッドを示しています。
クラスター環境が AZ の損失を処理できることをテストする
前のセクションで説明した要件を完了したら、次のステップは、AZ の損失を処理するのに十分なコンピューティングとワークロード容量があることをテストすることです。これを行うには、EKS でゾーンシフトを手動で開始します。または、ゾーンオートシフトを有効にして練習実行を設定して、クラスター環境内の AZ を 1 つ減らしてアプリケーションが期待どおりに機能することをテストすることもできます。
よくある質問
この機能を使用する理由は何ですか?
EKS クラスターで ARC ゾーンシフトまたはゾーンオートシフトを使用することで、クラスター内ネットワークトラフィックを障害のある AZ から移行する迅速な復旧プロセスを自動化することで、Kubernetes アプリケーションの可用性をより適切に維持できます。ARC を使用すると、障害のある AZ イベント中に回復期間を延長することがある、長く複雑なステップを回避できます。
この機能は他の AWS サービスとどのように連携しますか?
EKS は ARC と統合され、AWS で復旧オペレーションを実行するためのプライマリインターフェイスを提供します。クラスター内トラフィックが障害のある AZ から適切にルーティングされるように、EKS は Kubernetes データプレーンで実行されているポッドのネットワークエンドポイントのリストを変更します。クラスターへの外部トラフィックのルーティングに Elastic Load Balancing を使用している場合は、ロードバランサーを ARC に登録し、ゾーンシフトを開始して、トラフィックが機能低下した AZ に流れるのを防ぐことができます。ゾーンシフトは、EKS マネージド型ノードグループによって作成された Amazon EC2 Auto Scaling グループでも機能します。障害のある AZ が新しい Kubernetes ポッドまたはノードの起動に使用されるのを防ぐため、EKS は障害のある AZ を Auto Scaling グループから削除します。
この機能はデフォルトの Kubernetes 保護とどのように異なりますか?
この機能は、顧客のアプリケーションの回復力を高めるいくつかの Kubernetes 組み込み保護と連携して機能します。ポッドの準備状況とライブネスプローブを設定して、ポッドがいつトラフィックを取るかを決定できます。これらのプローブで障害が発生すると、Kubernetes はこれらのポッドをサービスのターゲットとして削除し、トラフィックはポッドに送信されなくなります。これは便利ですが、AZ が機能低下したときに障害が発生することが保証されるように、これらのヘルスチェックを設定するのは簡単ではありません。ARC ゾーンシフト機能には、Kubernetes のネイティブ保護が十分でない場合に、機能低下した AZ を完全に分離するのに役立つ追加のセーフティネットが用意されています。ゾーンシフトにはまた、アーキテクチャの運用準備状況と回復性を簡単にテストする方法も用意されています。
AWS はユーザーに代わってゾーンシフトを開始できますか?
はい。ARC ゾーンシフトを完全に自動化する方法が必要な場合は、ARC ゾーンオートシフトを有効にできます。ゾーンオートシフトでは、AWS を使用して EKS クラスターの AZ の状態を監視し、AZ の障害が検出されるとゾーンシフトを自動的に開始できます。
この機能を使用し、ワーカーノードとワークロードが事前にスケーリングされていない場合はどうなりますか?
ゾーンシフト中に事前スケールされておらず、追加のノードやポッドのプロビジョニングに依存している場合、復旧が遅れるリスクがあります。Kubernetes データプレーンに新しいノードを追加するプロセスには時間がかかるため、特にゾーンの障害が発生した場合に、アプリケーションのリアルタイムのパフォーマンスと可用性に影響を与える可能性があります。さらに、ゾーンの障害が発生した場合は、コンピューティング容量の制約により、新たに必要なノードが正常な AZ に追加できなくなる可能性があります。
ワークロードが事前にスケールされておらず、クラスター内のすべての AZ に分散されていない場合、ゾーンの障害により、影響を受ける AZ のワーカーノードでのみ実行されているアプリケーションの可用性に影響する可能性があります。アプリケーションの可用性が完全に停止するリスクを軽減するため、EKS にはフェイルセーフ機能があります。この機能により、ワークロードのすべてのエンドポイントが障害が発生している AZ にある場合でも、障害ゾーンのポッドエンドポイントにトラフィックを送信することが可能です。ただし、ゾーンの問題が発生した場合でも可用性を維持するために、アプリケーションを事前にスケールしてすべての AZ に分散することを強くお勧めします。
ステートフルアプリケーションを実行している場合、これはどのように機能しますか?
ステートフルアプリケーションを実行している場合は、ユースケースとアーキテクチャに基づいて、耐障害性を評価する必要があります。アクティブ/スタンバイのアーキテクチャまたはパターンがある場合、アクティブが障害のある AZ にある可能性があります。アプリケーションレベルでは、スタンバイがアクティブ化されていない場合、アプリケーションに問題が発生する可能性があります。また、正常な AZ で新しい Kubernetes ポッドを起動すると、障害のある AZ にバインドされた永続的なボリュームにアタッチできないため、問題が発生する可能性があります。
この機能は Karpenter で機能しますか?
Karpenter のサポートは、Karpenter バージョン 1.12 以降
この機能は EKS Fargate で機能しますか?
この機能は EKS Fargate では機能しません。デフォルトでは、EKS Fargate がゾーンヘルスイベントを認識すると、ポッドは他の AZ での動作を優先します。
EKS マネージド Kubernetes コントロールプレーンは影響を受けますか?
いいえ。デフォルトでは、Amazon EKS は、複数の AZ で Kubernetes コントロールプレーンを実行およびスケールして、高可用性を実現します。ARC ゾーンシフトとゾーンオートシフトは、Kubernetes データプレーンでのみ動作します。
この新機能に関連するコストはありますか?
EKS クラスターでは、ARC ゾーンシフトとゾーンオートシフトを追加料金なしで使用できます。ただし、プロビジョニングされたインスタンスの料金は引き続きお支払いいただきます。この機能を使用する前に、Kubernetes データプレーンを事前にスケールすることを強くお勧めします。コストとアプリケーションの可用性のバランスを考慮する必要があります。
その他のリソース
